Introduces the logged recommendation setting, the unit of analysis, candidate treatment definitions, engagement outcomes, and the basic imbalance that makes naive rank comparisons unreliable.
Ranking and Recommendation Lift
Causal Inference
Recommendation Systems
Project Lab
An applied causal inference lab on ranking-position effects in logged recommendation data.
This lab studies whether higher recommendation rank changes engagement in logged recommendation data. It is framed as a causal workflow rather than a predictive ranking exercise. The central problem is that high-ranked items are not randomly assigned. They are usually selected by an existing recommender, so raw click-through-rate differences mix position effects with item quality, user intent, category preference, and prior ranking logic.
The lab moves through the same steps an analyst would need before using logged recommendation evidence to support a product decision. It defines the ranking-position treatment, checks overlap, estimates propensities, compares adjusted estimators, studies heterogeneity, and asks how sensitive the conclusion is to remaining confounding and modeling choices.
Lab Sequence
Models the probability of receiving high-rank exposure, checks overlap, and uses inverse probability weighting to separate ranking-position lift from observed placement bias.
Combines outcome modeling with propensity adjustment so the estimate has two chances to remain credible when one nuisance model is imperfect.
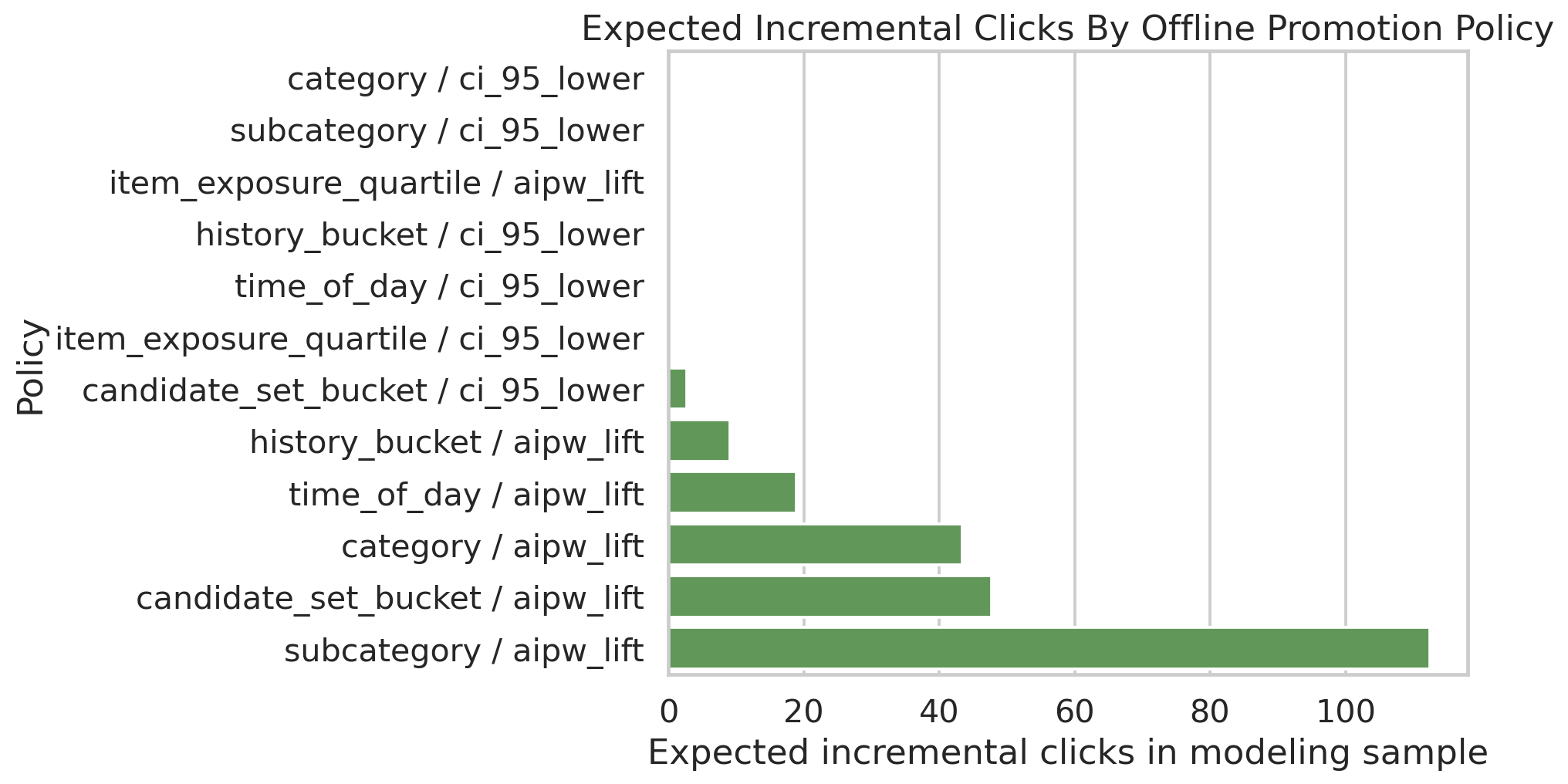
Studies how ranking lift varies across categories and segments, making clear that an average effect can hide where visibility creates the most incremental engagement.
Translates estimated effects into hypothetical ranking-policy changes and shows how causal estimates can inform product decisions without treating the model as a launch guarantee.
06. Sensitivity and Limitations
Stress-tests the results under alternative assumptions, documents what the logged data cannot settle, and connects remaining risks to online experimentation.
Uses machine-learning nuisance models for propensities and outcomes while keeping diagnostics focused on support, calibration, and causal interpretation.
Extends the workflow with causal machine-learning tools to estimate heterogeneous lift and compare segment-level conclusions with simpler estimators.