Off-policy evaluation for recommendation systems
Causal Inference
Off-Policy Evaluation
Recommender Systems
Doubly Robust
Causal ML
A causal ML project estimating counterfactual recommendation-policy value from logged bandit data with IPS, SNIPS, direct method, doubly robust OPE, and support diagnostics.
Decision Question
Which recommendation policy is credible enough to move from offline analysis into an online A/B test?
Causal Setup
- Context contains user, item, position, and time features available before recommendation.
- Action is the recommended item.
- Reward is the observed click.
- Behavior policy is the logged policy that generated historical data.
Methods
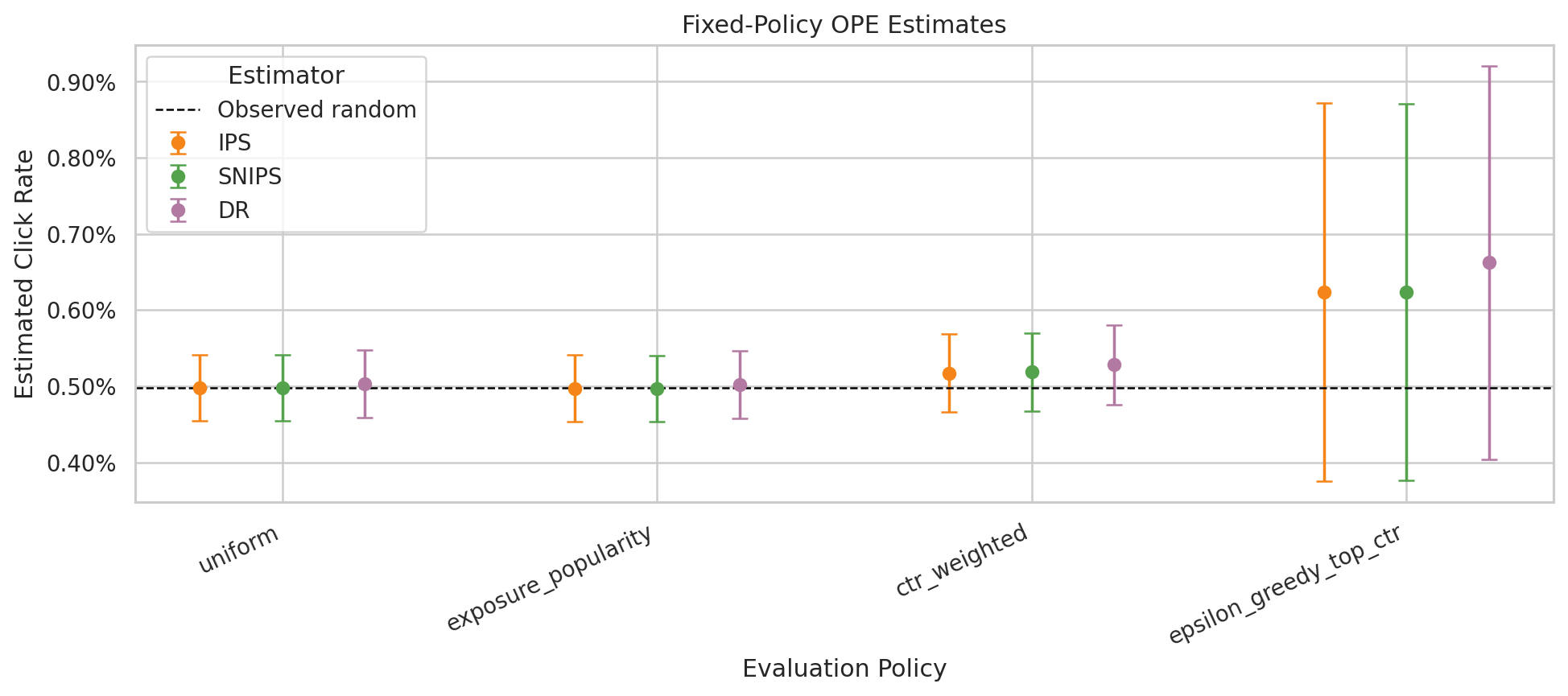
- IPS and self-normalized IPS
- Direct method reward modeling
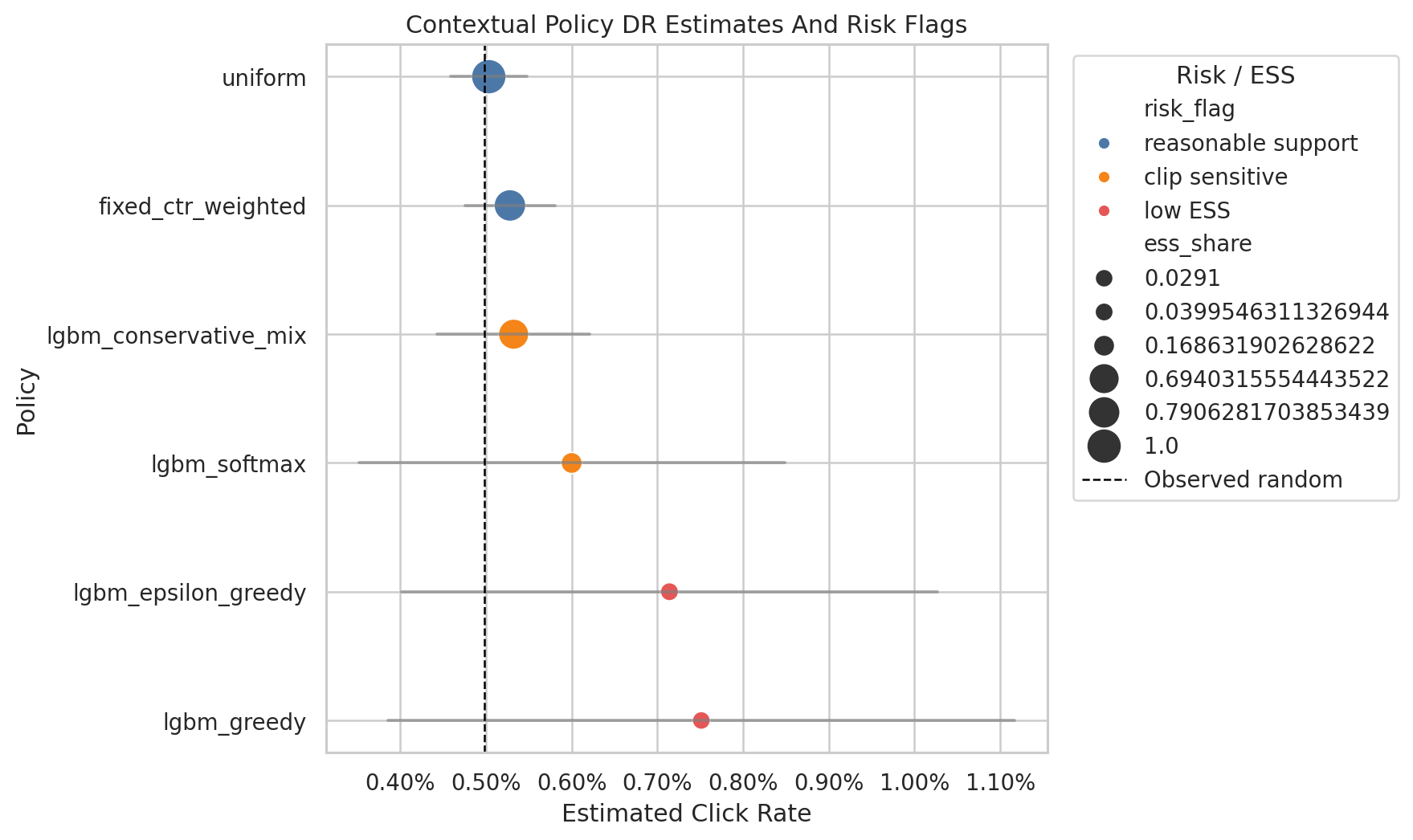
- Doubly robust off-policy evaluation
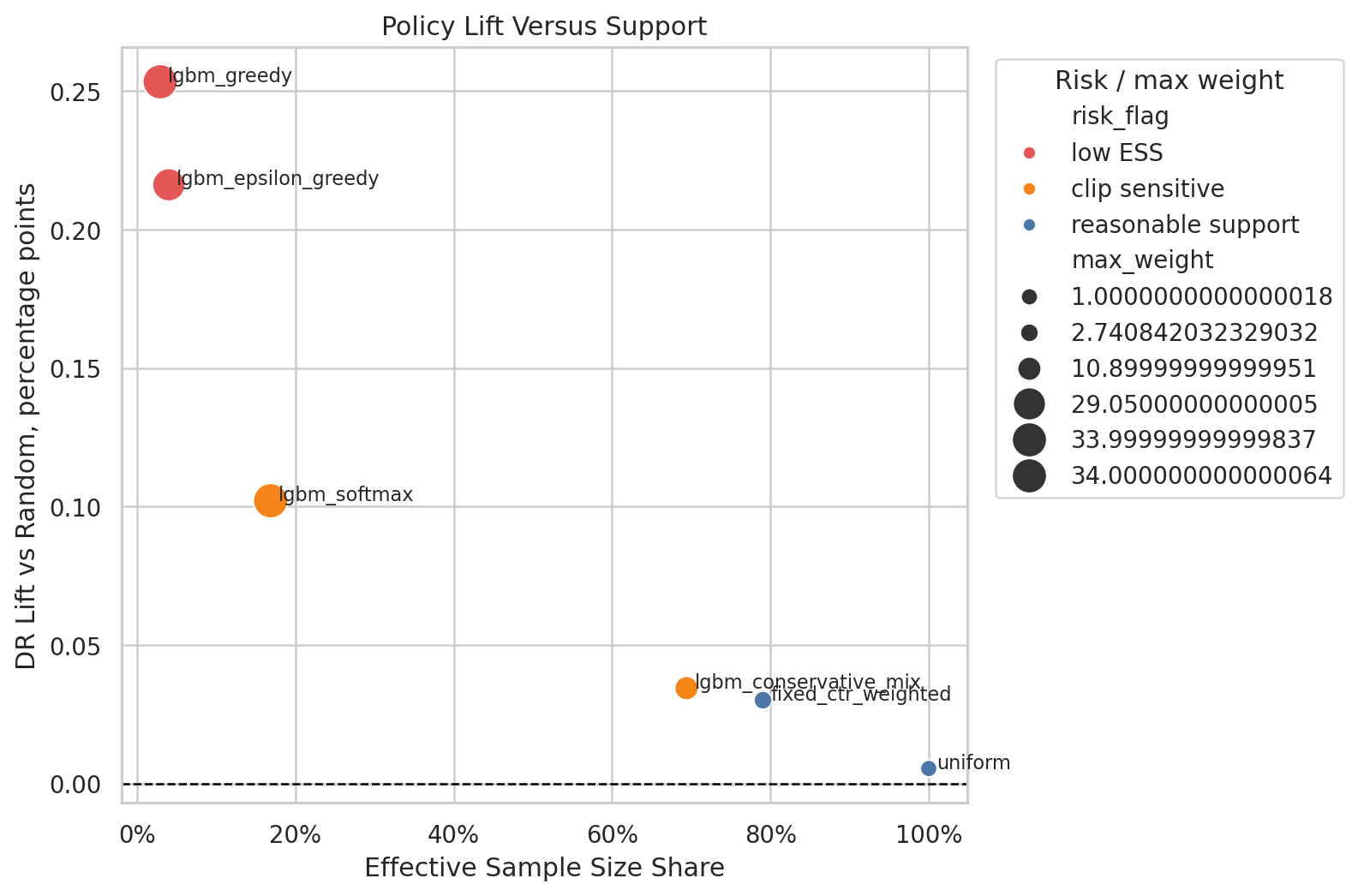
- Effective sample size and weight-tail diagnostics
- Contextual policy learning
Decision Takeaway
The project shows how to separate high point estimates from credible offline policy candidates by auditing support, clipping sensitivity, and reward-model stability.
Selected Figures
Notebook Sequence
Generated Artifacts
Limitations
These notebook-driven causal analyses should be read with their identification assumptions, support diagnostics, measurement choices, and sensitivity checks in view.