Lecture Notes
This page collects course notes developed for my teaching in computational mathematics and data science degree programs at Embry-Riddle Aeronautical University. The curriculum is organized across four connected modules: (i) Statistical Inference, (ii) Core Causal Inference, (iii) Advanced Causal Inference, and (iv) AI and Machine Learning. Together, these modules move from statistical foundations to causal design, advanced causal workflows, machine learning, AI, diagnostics, simulations, and decision-focused interpretation.
Scroll through the modules below and click course names to open the full lecture sequences. If you notice an error or typo, please let me know.
Module 1: Statistical Inference (MA 412 and MA 506)
Statistical Inference is the entry point for the lecture curriculum. It builds the quantitative habits needed for later causal, machine-learning, and AI courses, including careful data description, uncertainty reasoning, assumption checks, and evidence-to-decision translation.
This module is designed for readers who want statistical work to feel connected to action. The first course builds the language of data, variation, bias, and modeling. The second course turns that language into formal inference, where likelihoods, intervals, tests, Bayesian updating, and decision reports support defensible analysis.
The two courses work as a pair. One trains the eye to see structure in data. The other trains the judgment to recognize where evidence is strong, weak, or incomplete.
Course 1: Statistical Foundations for Data Science
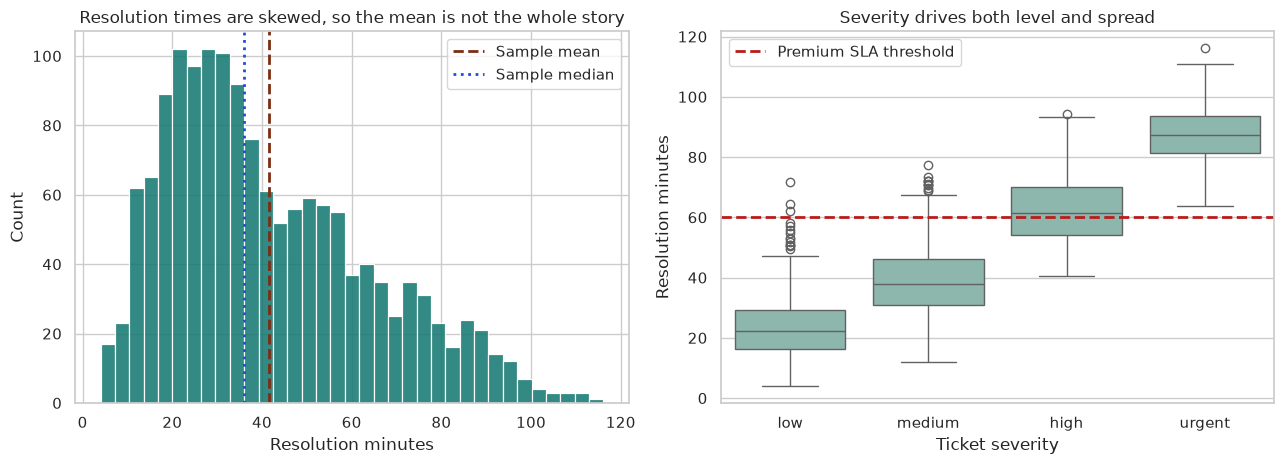
This course builds the habits behind responsible data analysis. It covers units and variables, randomness, distributions, sampling problems, simulation, and careful communication about what a model can support.
Course 2: Statistical Inference for Decision Science
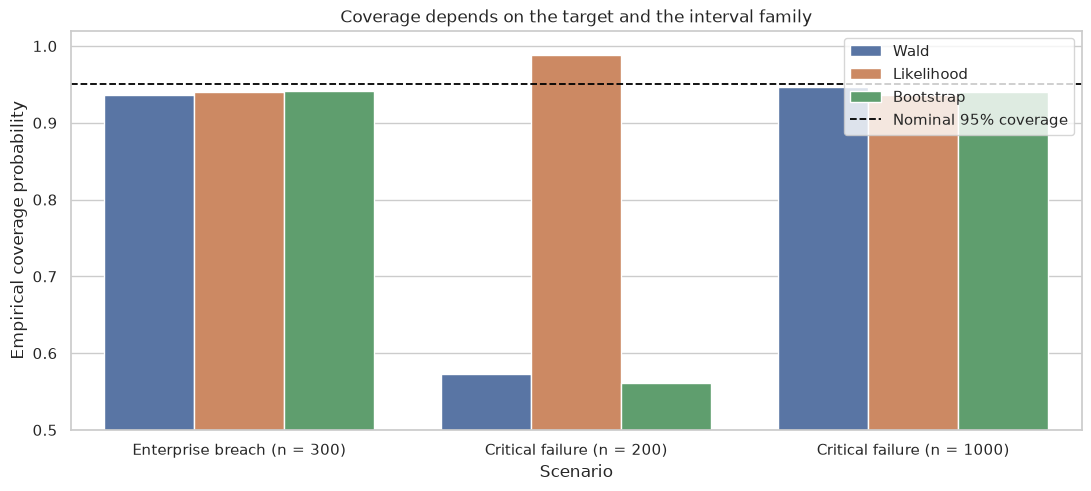
This course moves from descriptive analysis to evidence claims. It covers likelihood, uncertainty intervals, testing, resampling, regression inference, Bayesian updating, missing data, model checking, and value-of-information reasoning.
Module 2: Core Causal Inference (MA 412 and MA 413)
Core Causal Inference is the backbone of the lecture curriculum. It develops the conceptual grammar needed for the rest of the site, including causal questions, interventions, estimands, randomization, credible adjustment, and quasi-experimental variation.
The sequence is split into four courses. Together they move from causal language to design practice. The reader first learns how to define the question, then how to create evidence through experiments, how to repair observational comparisons, and how to use policy variation in applied settings.
This module is the conceptual center of the site. Everything later, from causal ML to AI-assisted analysis, depends on getting this design logic right.
Course 1: Foundations of Causal Inference
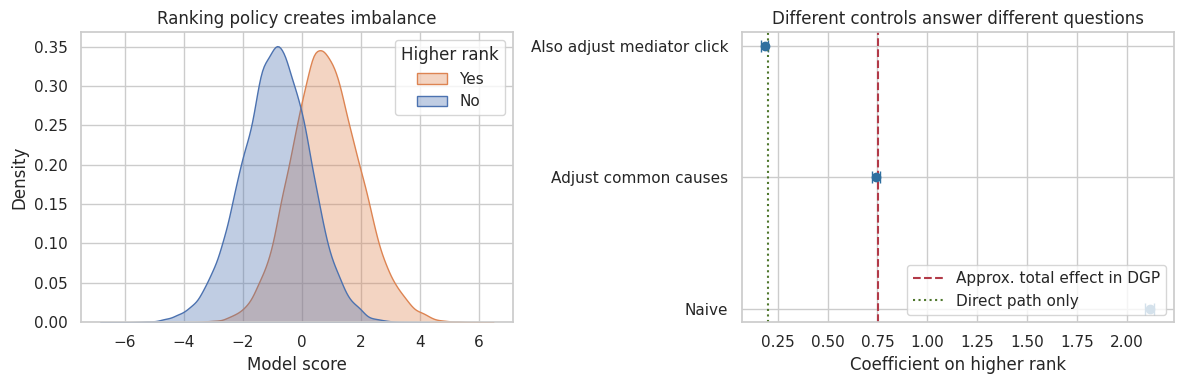
This course builds the language of causal reasoning, moving from interventions and potential outcomes to estimands, identification assumptions, DAGs, and common adjustment mistakes.
Course 2: Randomized Experiments and Product Experimentation
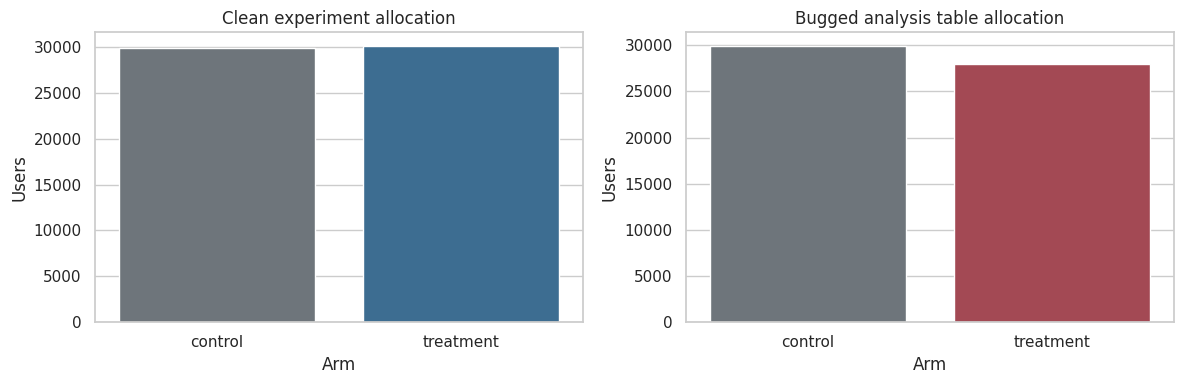
This course treats randomized evidence as an operational workflow. It covers experiment design, power, guardrail metrics, clustered assignment, noncompliance, interference, and clear reporting for launch decisions.
Course 3: Observational Adjustment
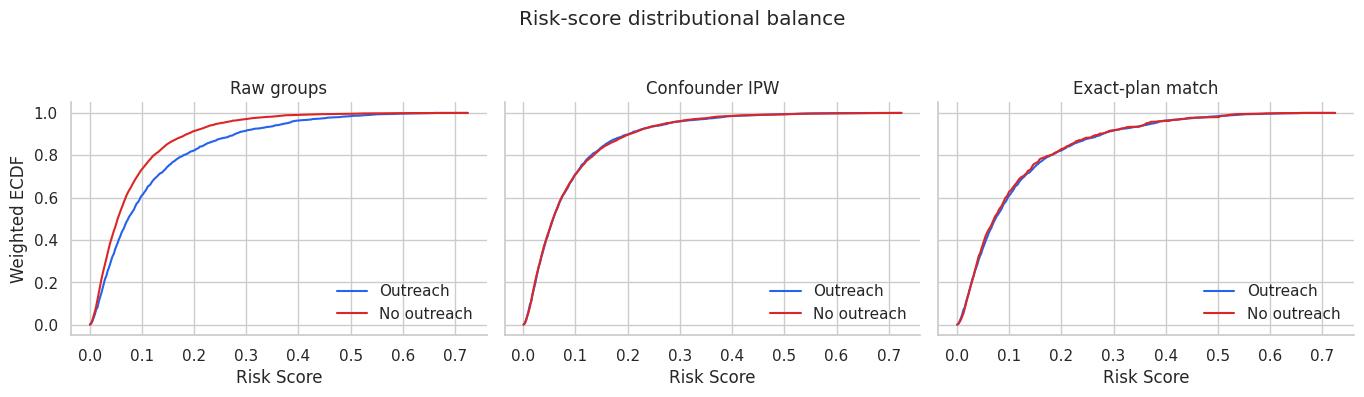
When treatment assignment comes from observed behavior, credibility depends on measured confounding, overlap, and diagnostics. This course covers regression adjustment, propensity scores, matching, weighting, balance checks, doubly robust estimation, TMLE, and sensitivity analysis.
Course 4: Quasi-Experiments and Natural Experiments
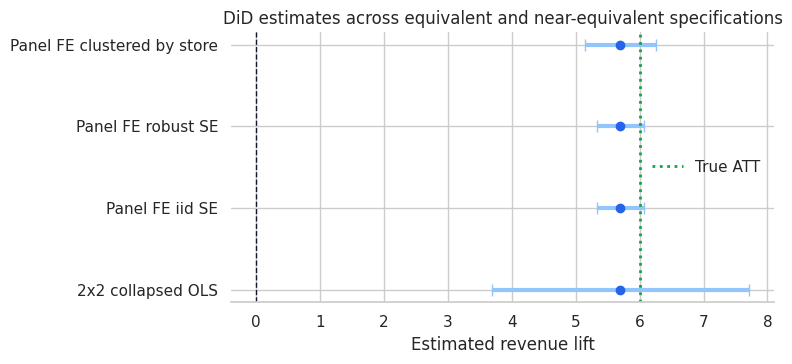
This course studies designs that exploit timing, thresholds, instruments, shocks, or policy variation. Topics include difference-in-differences, event studies, staggered adoption, synthetic control, regression discontinuity, instrumental variables, encouragement designs, and interrupted time series.
Module 3: Advanced Causal Inference (MA 505 and MA 506)
Advanced Causal Inference is the second major causal module in the lecture sequence. It assumes the reader has worked through the core causal inference material, then moves toward the professional settings where causal work becomes more technical, more operational, and more decision-facing.
The module has three courses. Causal Machine Learning covers modern estimation and policy-learning workflows once the estimand is clear. Industry Applications shows how causal designs map to product, marketing, marketplace, and policy decisions. Advanced Topics covers the complications that mature causal projects must confront, including mechanisms, missingness, measurement error, transportability, interference, panels, discovery, Bayesian workflows, and AI-system complications.
Here the goal is to estimate effects and decide which effect matters, which method is credible, and how the result changes a real decision.
Course 1: Causal Machine Learning
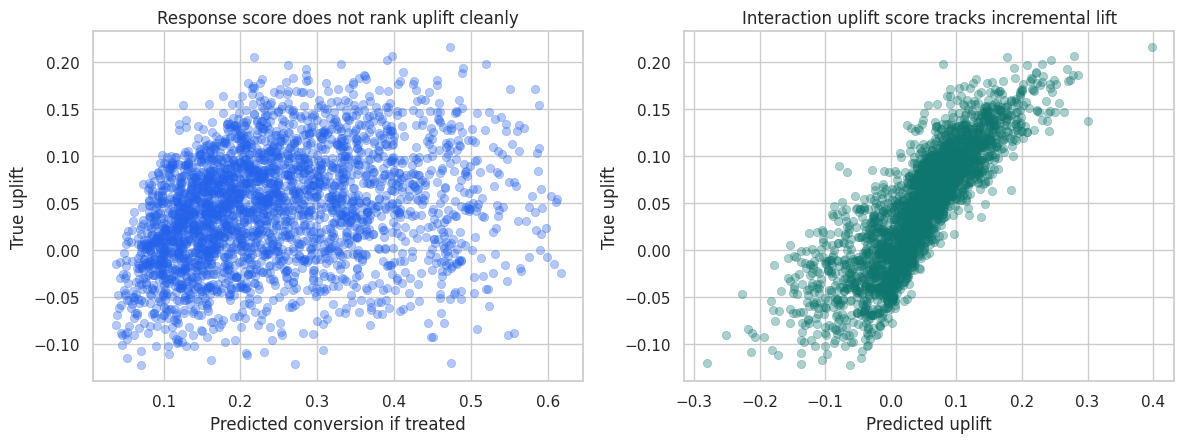
This course focuses on heterogeneous treatment effects, CATE and uplift modeling, meta-learners, causal forests, Double ML, policy learning, treatment targeting, off-policy evaluation, and validation.
Course 2: Industry Applications of Causal Inference
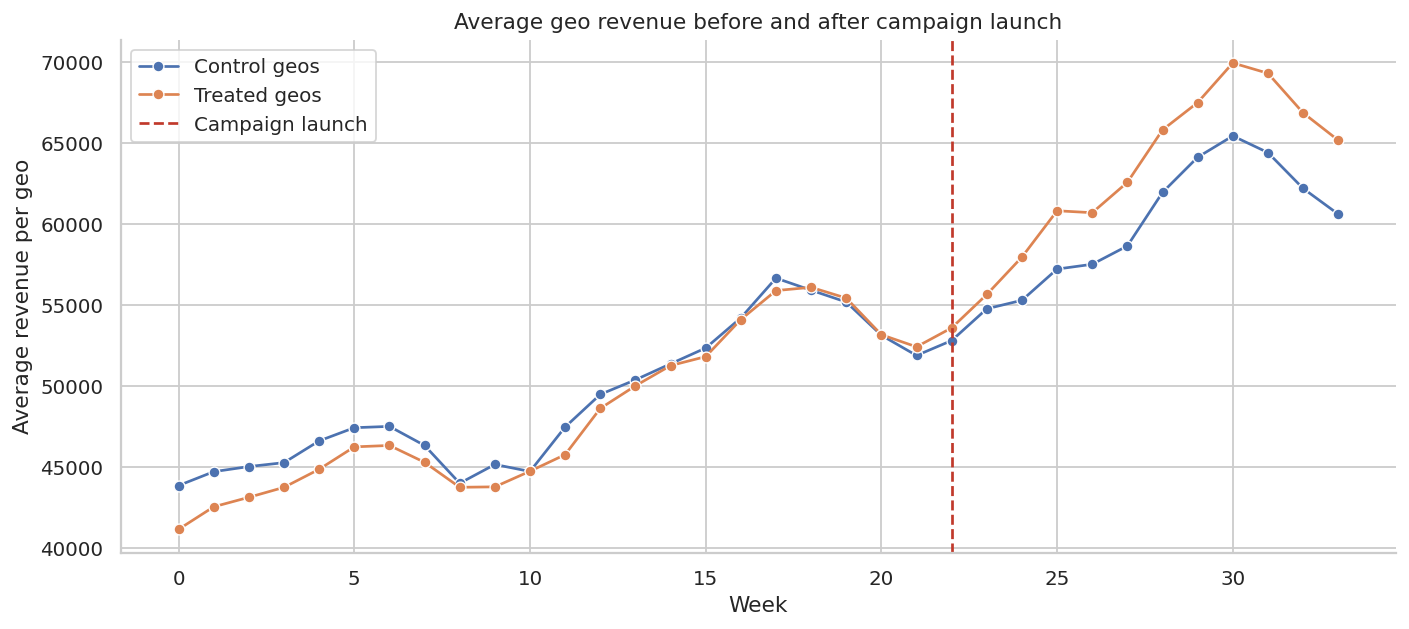
This course translates causal inference into applied decision workflows for marketing incrementality, pricing, promotions, ranking, retention, product launches, marketplaces, public-sector applications, and leadership decision summaries.
Course 3: Advanced Topics in Causal Inference

This course studies the issues that make advanced causal projects difficult, including mediation, principal stratification, missing data, measurement error, transportability, interference, panel complications, causal discovery, Bayesian causal inference, and AI-system complications.
Module 4: AI and Machine Learning (DS 440, DS 540, DS 625 and DS 699)
AI and Machine Learning complements the statistics and causal curriculum with courses on predictive modeling, explanation, anomaly detection, and AI-assisted causal work. The common theme is decision science: models are useful when they support auditable choices, expose uncertainty, and remain connected to operational guardrails.
The module has four courses. The first covers supervised and unsupervised machine learning foundations for operational decision systems. The second develops interpretable ML and XAI as reviewable explanation workflows. The third treats anomaly detection as a triage and monitoring problem. The fourth shows how LLMs, RAG, agents, and structured evaluation can assist causal analysts while preserving identification discipline.
The through-line is practical governance. A useful model can score, cluster, explain, detect, or draft while making uncertainty and failure modes visible enough for responsible use.
Course 1: Machine Learning Basics for Decision Science
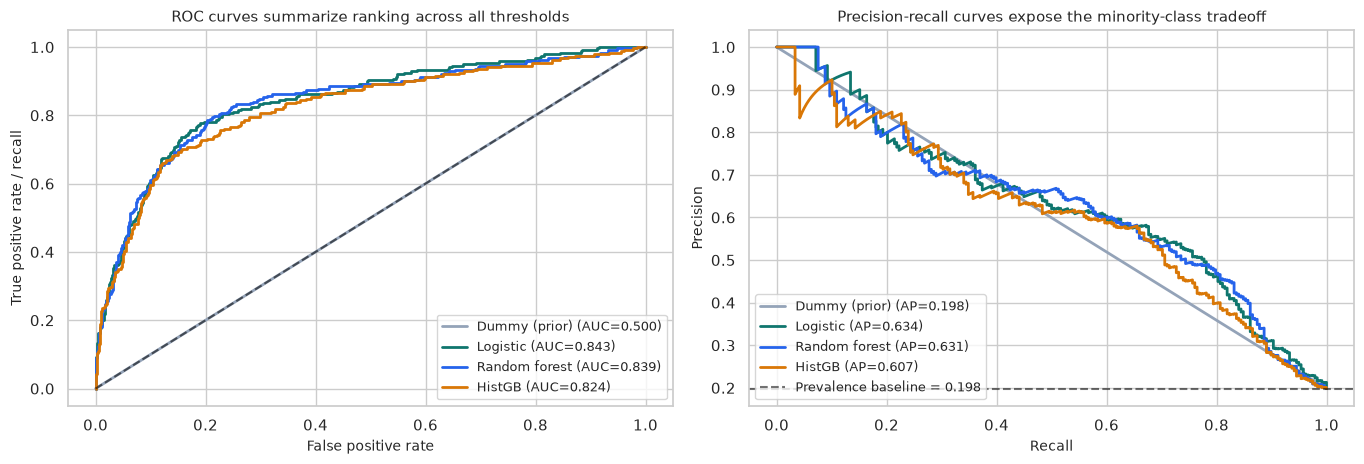
A supervised and unsupervised learning course for decision systems, covering framing, leakage, baselines, regularization, trees, metrics, calibration, clustering, monitoring, and guardrails.
Course 2: Interpretable ML and XAI
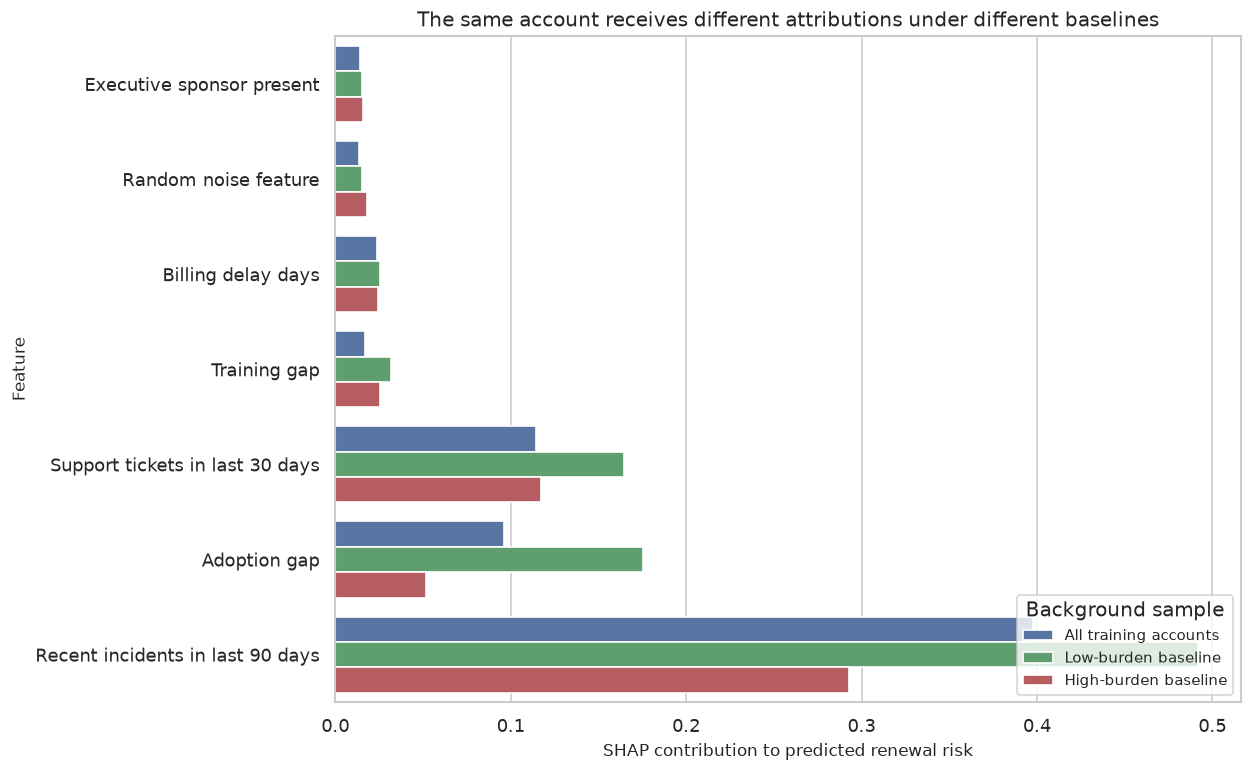
A mathematically grounded interpretability course covering transparent baselines, feature effects, SHAP, LIME, recourse, explanation stability, fairness, governance, and stakeholder communication.
Course 3: Anomaly Detection for Decision Systems
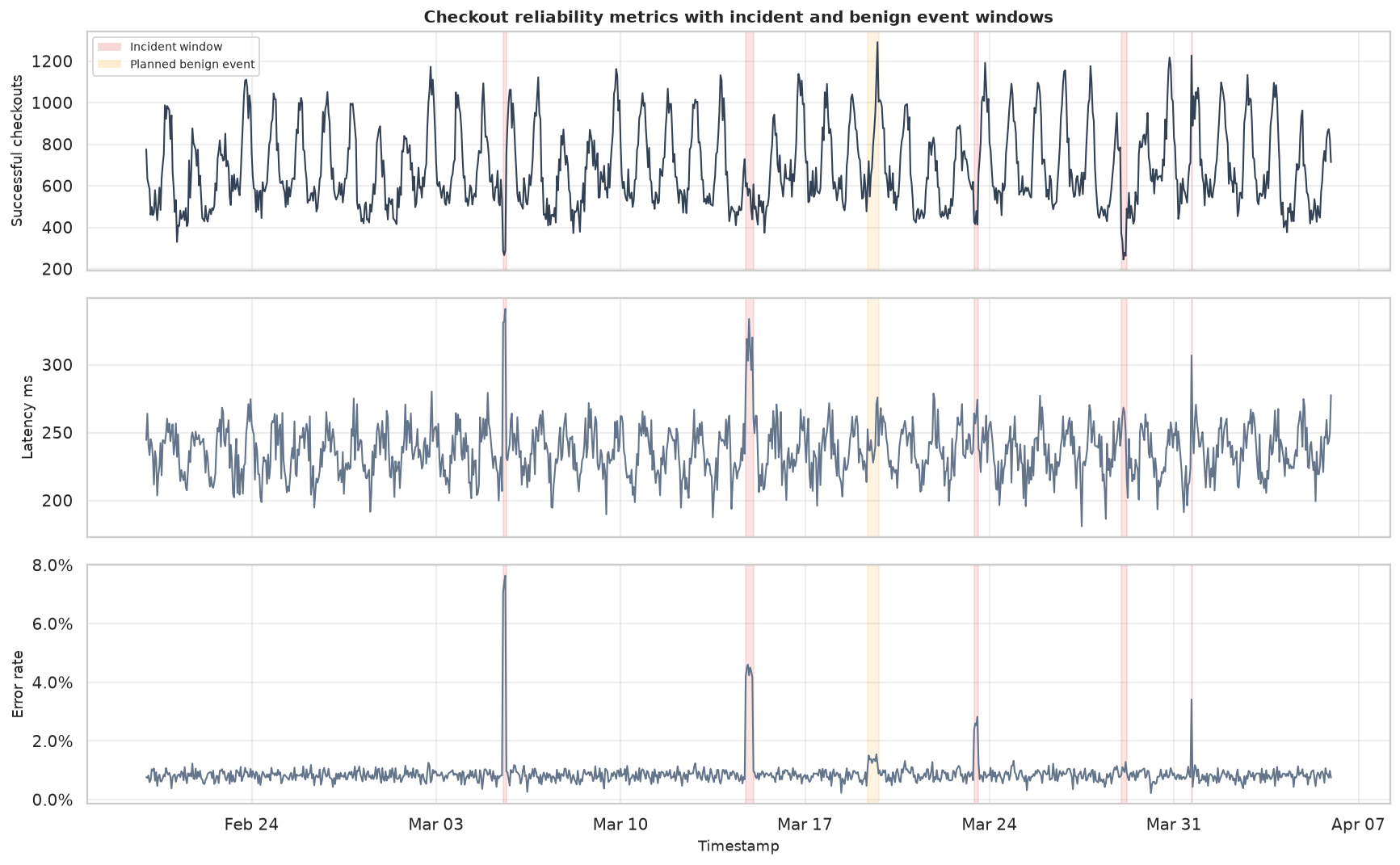
A decision-focused anomaly detection course covering statistical detectors, distance and density methods, isolation forests, reconstruction, time series, thresholds, triage, root-cause analysis, and governance.
Course 4: AI for Causal Inference
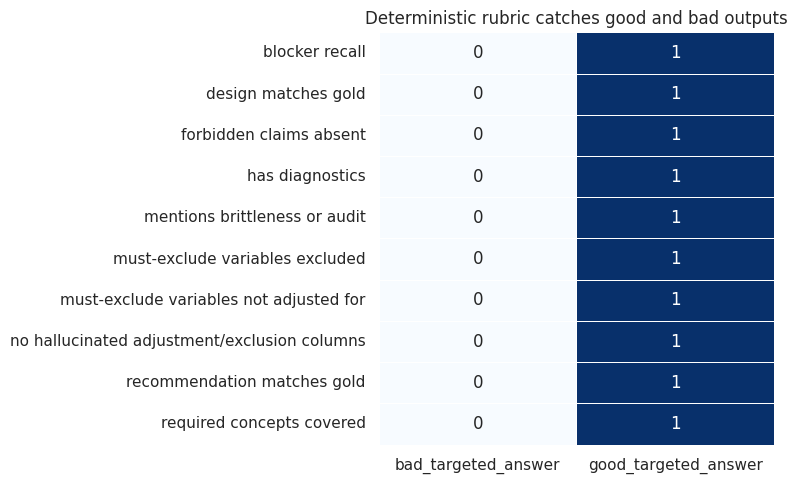
A course on using local LLMs, RAG, structured outputs, agents, diagnostics, code generation, sensitivity workflows, and evaluation to support causal analysts while preserving identification judgment.