Introduces the logged bandit dataset, available contexts, actions, rewards, and the policy-evaluation question that motivates the rest of the lab.
Off-Policy Evaluation for Bandit Systems
Causal Inference
Off-Policy Evaluation
Project Lab
An applied causal inference lab on evaluating bandit policies from logged feedback.
This lab studies how to evaluate a new decision policy using historical bandit logs. A logged policy chose actions, observed rewards, and stored propensities or features that let the analyst reconstruct how likely each action was under the behavior policy.
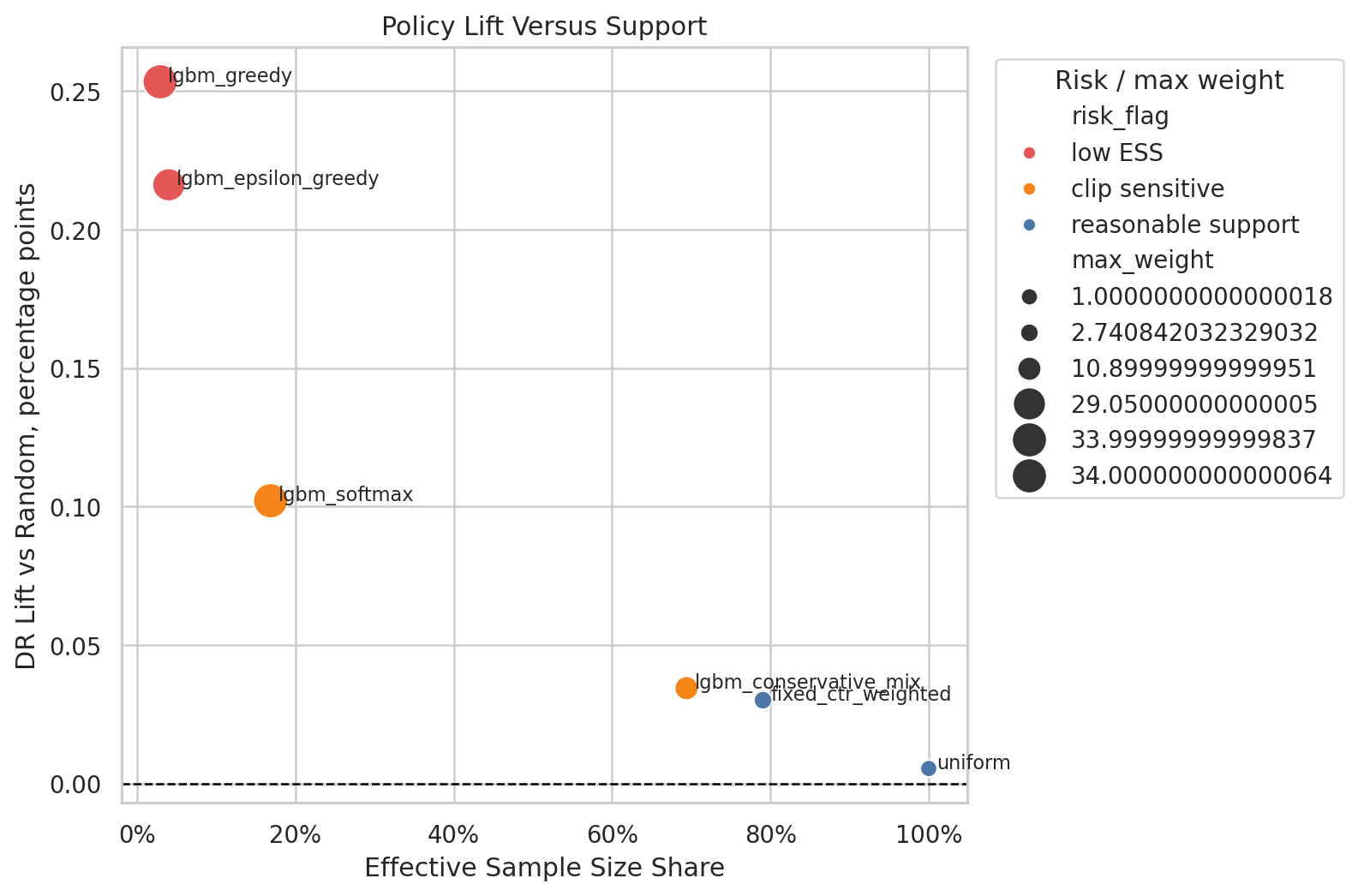
The main lesson is that off-policy evaluation is not just a value-estimation formula. It is a decision workflow. A policy with high estimated lift can still be risky when it relies on weak support, unstable weights, or narrow slices of the logged action space. The lab therefore pairs IPS, SNIPS, and doubly robust estimators with diagnostics, uncertainty summaries, and contextual policy-learning comparisons.
Lab Sequence
02. Behavior Policy and Propensities
Reconstructs the behavior-policy information needed for OPE and studies whether candidate policies are sufficiently supported by historical logging.
Builds inverse-propensity and self-normalized estimators, then examines how weights create both the possibility and the fragility of off-policy learning.
Combines reward modeling with propensity weighting to reduce variance and clarify the role of model fit in decision-quality OPE.
05. Policy Comparison and Sensitivity
Compares candidate policies using lift, support, clipping behavior, and uncertainty so the decision is based on robustness rather than a single point estimate.
06. Contextual Policy Learning
Learns context-dependent policies from logged feedback and evaluates whether personalization improves value without weakening support or increasing decision risk.