01. Why Interpretability Matters in Decision Systems
This lecture connects Why Interpretability Matters in Decision Systems to model behavior, explanation stability, stakeholder review, and decision limits.
This course treats interpretability as part of the model governance workflow. Explanations are studied as objects that need mathematical grounding, stability checks, causal caution, and clear communication.
By the end, a reader should be able to use transparent models as baselines, read feature effects and interaction patterns, compare SHAP and LIME-style explanations, assess recourse, evaluate explanation stability, and communicate model behavior with appropriate caution about what explanations prove.
01. Why Interpretability Matters in Decision Systems
This lecture connects Why Interpretability Matters in Decision Systems to model behavior, explanation stability, stakeholder review, and decision limits.
02. Transparent Models as First-Class Baselines
This lecture develops Transparent Models as First-Class Baselines with examples that make assumptions, diagnostics, and interpretation visible.
03. Reading Models: Coefficients, Odds Ratios, and Response Surfaces
This lecture uses Reading Models: Coefficients, Odds Ratios, and Response Surfaces to clarify the analyst’s question, evidence, assumptions, and decision implications.
04. Shape Constraints, Monotonicity, and Business Logic
This lecture connects shape constraints and monotonicity to business logic, plausibility, and model review.
05. Tree Models, Path Logic, and Segment Rules
This lecture frames Tree Models, Path Logic, and Segment Rules as a decision problem and asks what evidence can be trusted, challenged, and communicated.
06. Global Explanations: Partial Dependence, ICE, and ALE
This lecture builds intuition for Global Explanations: Partial Dependence, ICE, and ALE and ties the result to model choice, uncertainty, and action.
07. Permutation Importance and Model Reliance
This lecture applies Permutation Importance and Model Reliance with emphasis on diagnostics, tradeoffs, and evidence limits.
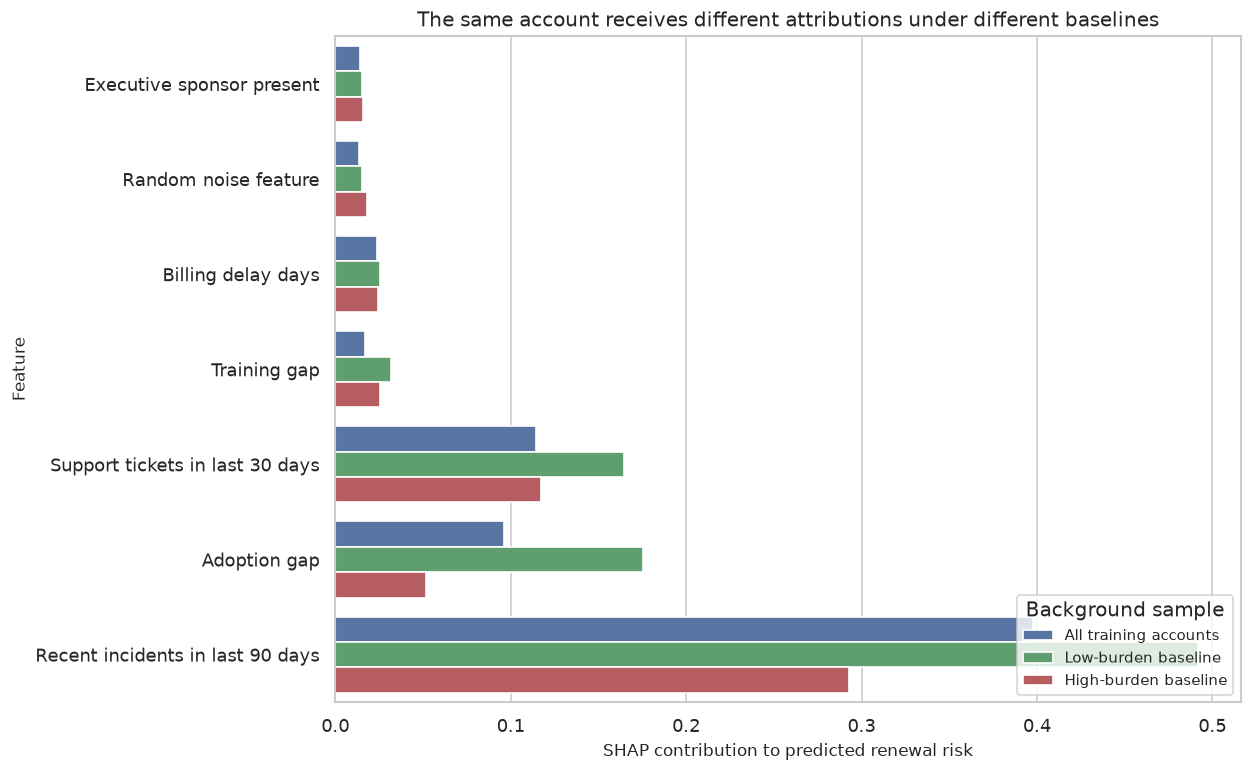
08. SHAP Values: Intuition, Computation, and Failure Modes
This lecture develops SHAP Values: Intuition, Computation, and Failure Modes as a practical pattern for analysis, diagnostics, and decision support.
09. LIME, Local Surrogates, and Neighborhood Sensitivity
This lecture connects LIME, Local Surrogates, and Neighborhood Sensitivity to local explanation quality, stability, and review.
10. Interactions, Heterogeneity, and Nonlinear Structure
This lecture develops Interactions, Heterogeneity, and Nonlinear Structure with examples that make assumptions, diagnostics, and interpretation visible.
11. Counterfactual Explanations and Actionable Recourse
This lecture uses Counterfactual Explanations and Actionable Recourse to clarify the analyst’s question, evidence, assumptions, and decision implications.
12. Explaining Ranking, Prioritization, and Policy Scores
This lecture studies ranking and prioritization scores through explanation, auditability, and decision impact.
13. Explanation Stability Across Resamples and Retrains
This lecture frames Explanation Stability Across Resamples and Retrains as a decision problem and asks what evidence can be trusted, challenged, and communicated.
14. When Explanations Conflict with Causal Reasoning
This lecture builds intuition for When Explanations Conflict with Causal Reasoning and ties the result to model choice, uncertainty, and action.
15. Fairness, Governance, and Auditability of Explanations
This lecture applies Fairness, Governance, and Auditability of Explanations with emphasis on diagnostics, tradeoffs, and evidence limits.
16. Communicating Explanations to Stakeholders
This lecture develops Communicating Explanations to Stakeholders as a practical pattern for analysis, diagnostics, and decision support.
17. Capstone: An Interpretable Decision Pipeline
Brings the interpretability course together through a full decision pipeline with model review, explanation, and communication.