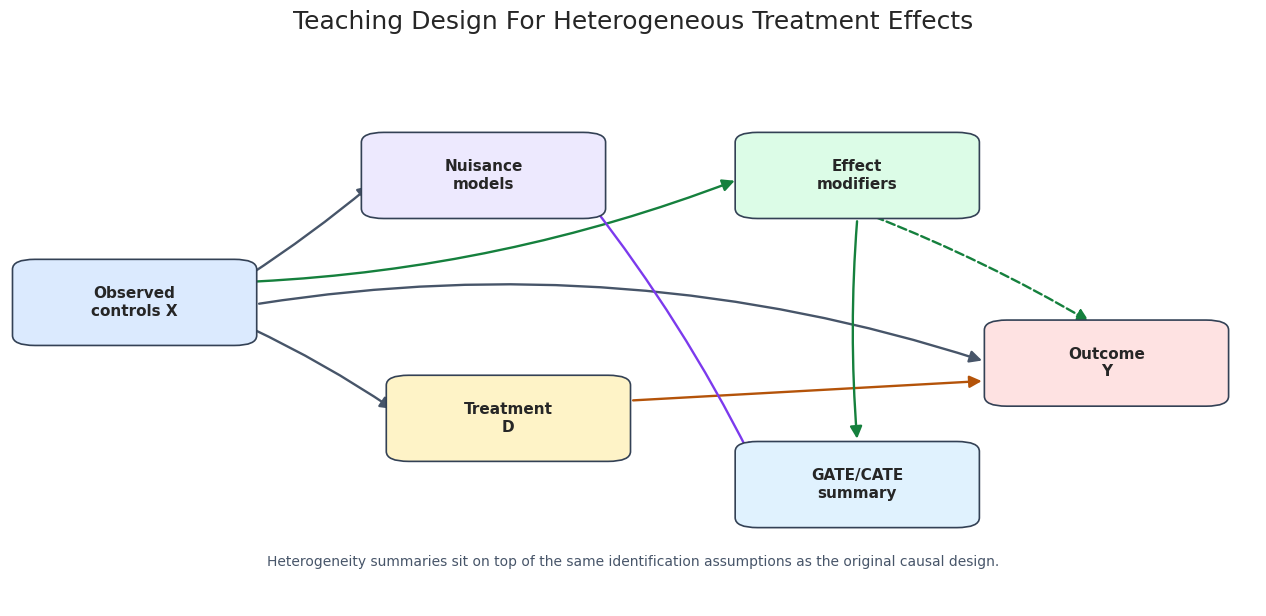
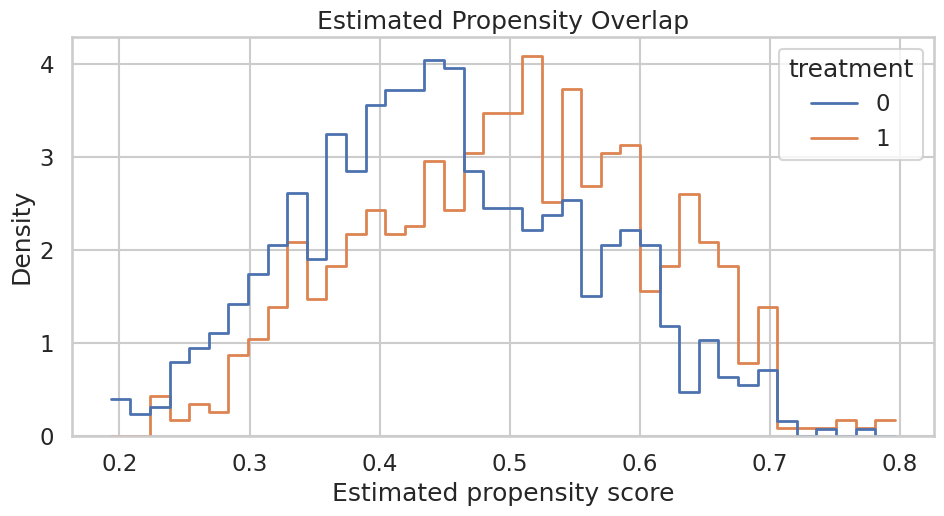
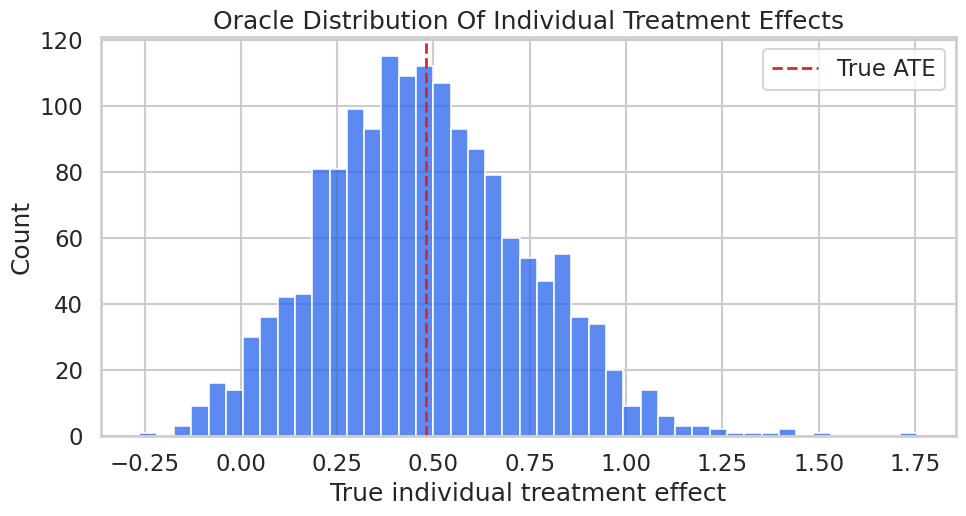
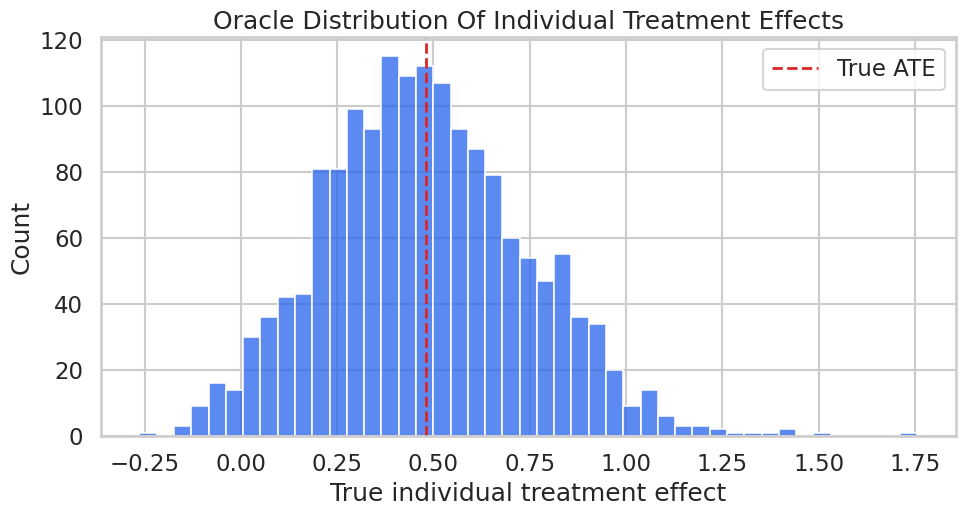
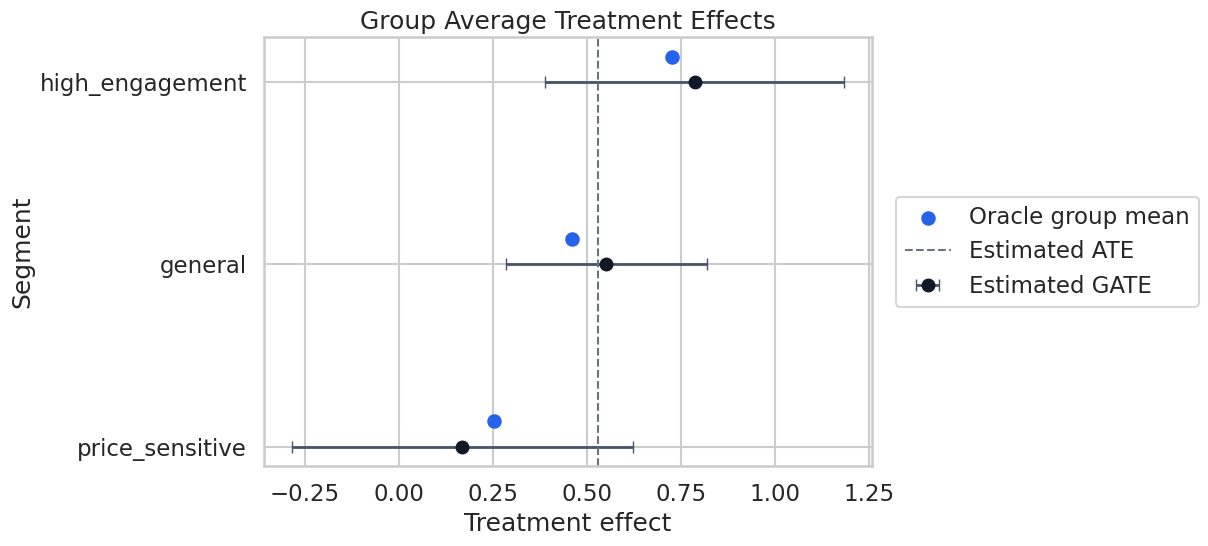
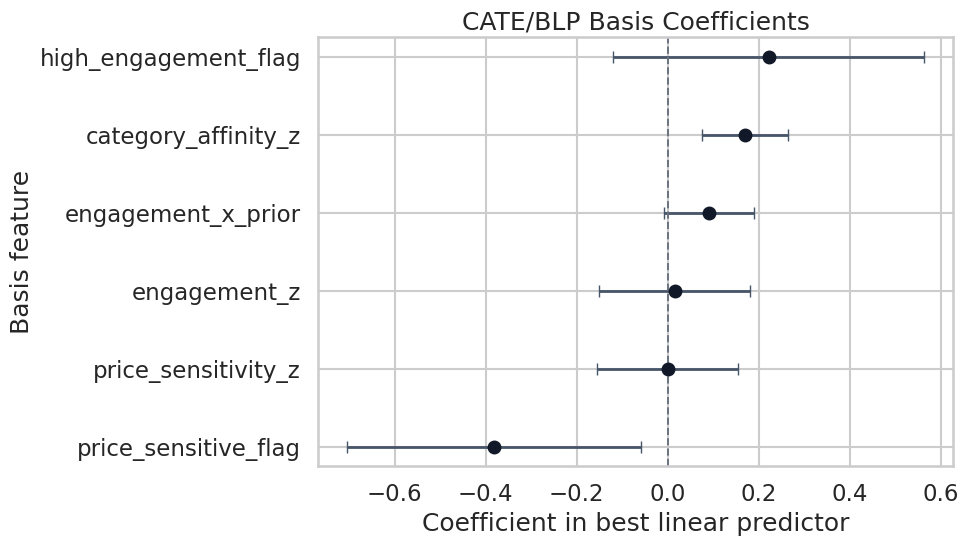
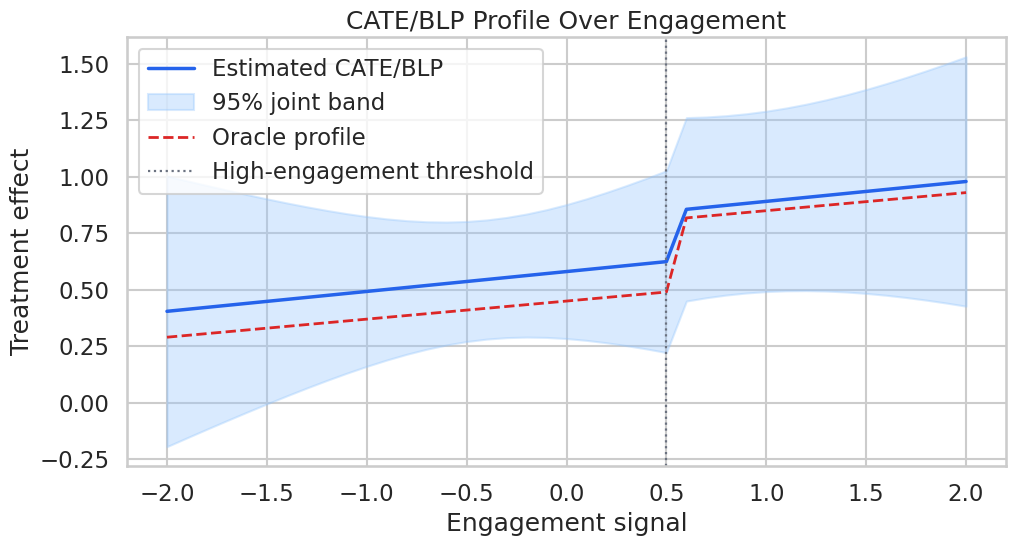
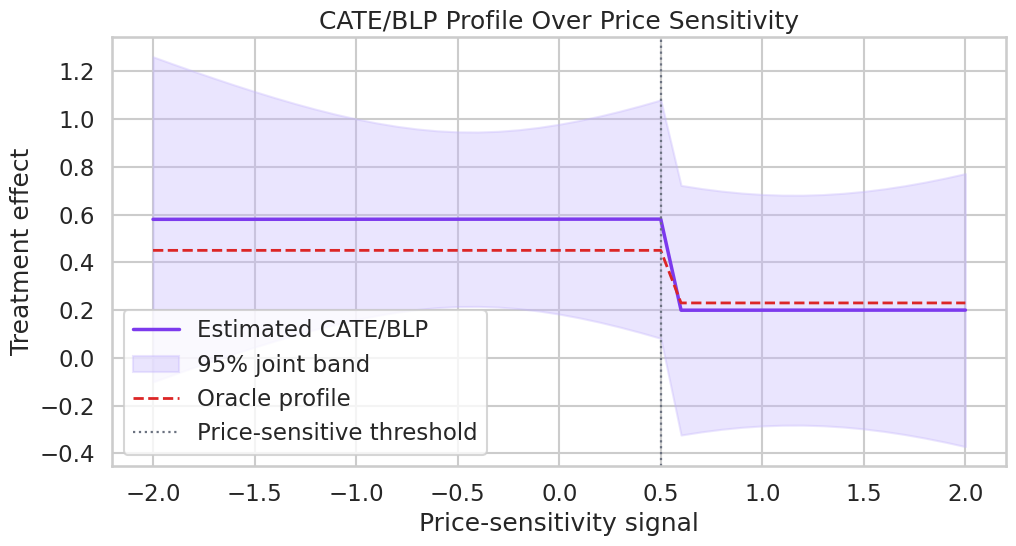
# Define reusable helpers for the Teaching Design Diagram section.
fig, ax = plt.subplots(figsize=(13, 6.5))
ax.set_axis_off()
nodes = {
"X": {"xy": (0.10, 0.55), "label": "Observed\ncontrols X", "color": "#dbeafe"},
"N": {"xy": (0.38, 0.78), "label": "Nuisance\nmodels", "color": "#ede9fe"},
"D": {"xy": (0.40, 0.34), "label": "Treatment\nD", "color": "#fef3c7"},
"T": {"xy": (0.68, 0.78), "label": "Effect\nmodifiers", "color": "#dcfce7"},
"Y": {"xy": (0.88, 0.44), "label": "Outcome\nY", "color": "#fee2e2"},
"H": {"xy": (0.68, 0.22), "label": "GATE/CATE\nsummary", "color": "#e0f2fe"},
}
box_w, box_h = 0.16, 0.12
def anchor(node, side):
"""
Idea: Return the plotting anchor point for a named node in the diagram.
Parameters
----------
node : object
Graph node whose position, label, or incident edges are being processed.
side : object
Endpoint side used to place an arrow or edge on the correct part of a node.
Returns
-------
tuple[float, float] or np.ndarray
Coordinate of the requested side of a plotted node.
"""
x, y = nodes[node]["xy"]
offsets = {
"left": (-box_w / 2, 0),
"right": (box_w / 2, 0),
"top": (0, box_h / 2),
"bottom": (0, -box_h / 2),
"upper_right": (box_w / 2, box_h * 0.25),
"lower_right": (box_w / 2, -box_h * 0.25),
"upper_left": (-box_w / 2, box_h * 0.25),
"lower_left": (-box_w / 2, -box_h * 0.25),
}
dx, dy = offsets[side]
return np.array([x + dx, y + dy], dtype=float)
def shorten(start, end, gap=0.018):
"""
Idea: Shorten a line segment so the arrowhead remains visible outside the node box.
Parameters
----------
start : tuple[float, float]
Starting coordinate for a plotted element.
end : tuple[float, float]
Ending coordinate for a plotted element.
gap : float
Spacing used to keep plotted elements from overlapping.
Returns
-------
tuple[float, float]
Shortened endpoint coordinate that keeps an arrowhead visible.
"""
start = np.asarray(start, dtype=float)
end = np.asarray(end, dtype=float)
delta = end - start
length = np.hypot(delta[0], delta[1])
if length == 0:
return tuple(start), tuple(end)
unit = delta / length
return tuple(start + gap * unit), tuple(end - gap * unit)
def draw_arrow(start, end, color="#334155", style="solid", rad=0.0, linewidth=1.7):
"""
Idea: Draw a routed arrow between diagram nodes while keeping the arrowhead visible.
Parameters
----------
start : tuple[float, float]
Starting coordinate for a plotted element.
end : tuple[float, float]
Ending coordinate for a plotted element.
color : str
Plot color used to identify this element.
style : object
Plotting style that determines how the curve, marker, or annotation is drawn.
rad : float
Curvature parameter for the plotted arrow.
linewidth : object
Line width used to make the plotted edge or reference line readable.
Returns
-------
None
Adds an arrow annotation directly to the supplied Matplotlib axes.
"""
start, end = shorten(start, end)
arrow = FancyArrowPatch(
start,
end,
arrowstyle="-|>",
mutation_scale=18,
linewidth=linewidth,
color=color,
linestyle=style,
connectionstyle=f"arc3,rad={rad}",
zorder=2,
)
ax.add_patch(arrow)
# Draw arrows before boxes so line endpoints tuck under the box borders cleanly.
draw_arrow(anchor("X", "upper_right"), anchor("N", "left"), color="#475569", rad=0.03)
draw_arrow(anchor("X", "lower_right"), anchor("D", "left"), color="#475569", rad=-0.04)
draw_arrow(anchor("X", "right"), anchor("Y", "left"), color="#475569", rad=-0.12)
draw_arrow(anchor("X", "upper_right"), anchor("T", "left"), color="#15803d", rad=0.08)
draw_arrow(anchor("D", "upper_right"), anchor("Y", "lower_left"), color="#b45309", rad=0.00)
draw_arrow(anchor("T", "bottom"), anchor("Y", "top"), color="#15803d", style="dashed", rad=-0.04)
draw_arrow(anchor("N", "lower_right"), anchor("H", "upper_left"), color="#7c3aed", rad=-0.05)
draw_arrow(anchor("T", "bottom"), anchor("H", "top"), color="#15803d", rad=0.04)
for spec in nodes.values():
x, y = spec["xy"]
rect = FancyBboxPatch(
(x - box_w / 2, y - box_h / 2),
box_w,
box_h,
boxstyle="round,pad=0.018",
facecolor=spec["color"],
edgecolor="#334155",
linewidth=1.2,
zorder=3,
)
ax.add_patch(rect)
ax.text(x, y, spec["label"], ha="center", va="center", fontsize=11, fontweight="bold", zorder=4)
ax.text(
0.50,
0.08,
"Heterogeneity summaries sit on top of the same identification assumptions as the original causal design.",
ha="center",
va="center",
fontsize=10,
color="#475569",
)
ax.set_title("Teaching Design For Heterogeneous Treatment Effects", pad=18)
plt.tight_layout()
fig.savefig(FIGURE_DIR / f"{NOTEBOOK_PREFIX}_hte_teaching_design.png", dpi=160, bbox_inches="tight")
plt.show()