# Build and label the diagnostic visualization for the Setup section.
from pathlib import Path
import os
import warnings
PROJECT_ROOT = Path.cwd().resolve()
if PROJECT_ROOT.name == "doubleml":
PROJECT_ROOT = PROJECT_ROOT.parents[2]
OUTPUT_DIR = PROJECT_ROOT / "notebooks" / "tutorials" / "doubleml" / "outputs"
DATASET_DIR = OUTPUT_DIR / "datasets"
FIGURE_DIR = OUTPUT_DIR / "figures"
TABLE_DIR = OUTPUT_DIR / "tables"
MATPLOTLIB_CACHE_DIR = OUTPUT_DIR / "matplotlib_cache"
for directory in [DATASET_DIR, FIGURE_DIR, TABLE_DIR, MATPLOTLIB_CACHE_DIR]:
directory.mkdir(parents=True, exist_ok=True)
os.environ.setdefault("MPLCONFIGDIR", str(MATPLOTLIB_CACHE_DIR))
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", message="IProgress not found.*")
warnings.filterwarnings("ignore", message="X does not have valid feature names.*")
import numpy as np
import pandas as pd
pd.set_option("display.max_colwidth", None)
pd.set_option("display.max_columns", None)
pd.set_option("display.width", 0)
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Markdown, display
from matplotlib.ticker import PercentFormatter
import doubleml as dml
from doubleml import DoubleMLData, DoubleMLPLR
from sklearn.base import clone
from sklearn.linear_model import RidgeCV
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
NOTEBOOK_PREFIX = "13"
RANDOM_SEED = 100
TRUE_THETA = 0.80
TREATMENT_COL = "treatment"
OUTCOME_COL = "outcome"
sns.set_theme(style="whitegrid", context="notebook")
plt.rcParams.update({"figure.dpi": 120, "savefig.dpi": 160})
print(f"DoubleML version: {dml.__version__}")13: Sensitivity Analysis for Unobserved Confounding
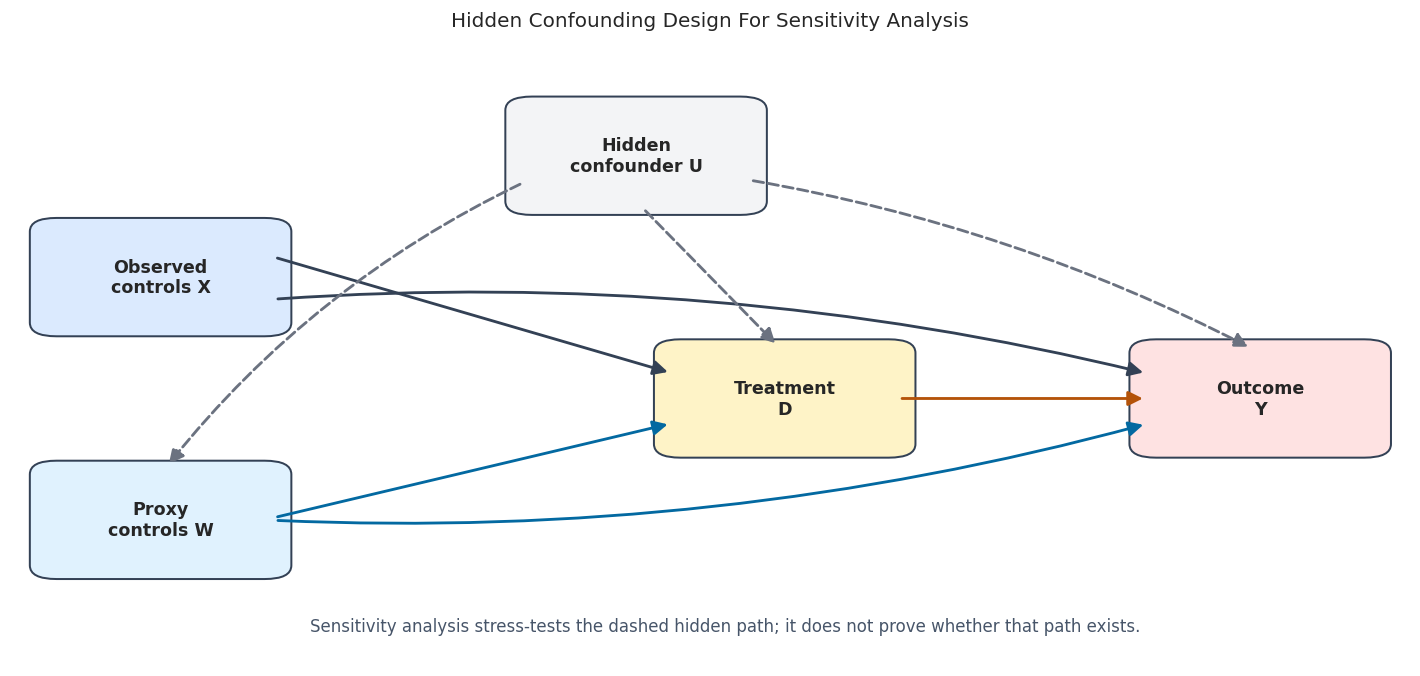
This lesson is about a hard truth in causal inference: good machine learning still needs good identification assumptions. DoubleML can adjust flexibly for observed controls, while it still relies on a version of unconfoundedness given the observed controls. If an important common cause of treatment and outcome is missing, the estimate can be biased.
Sensitivity analysis asks a disciplined question:
How strong would hidden confounding need to be to materially change the conclusion?
DoubleML’s sensitivity tools do not discover the hidden variable. They do not prove that unobserved confounding is absent. Instead, they create a structured stress test. The stress test is controlled by three main ideas:
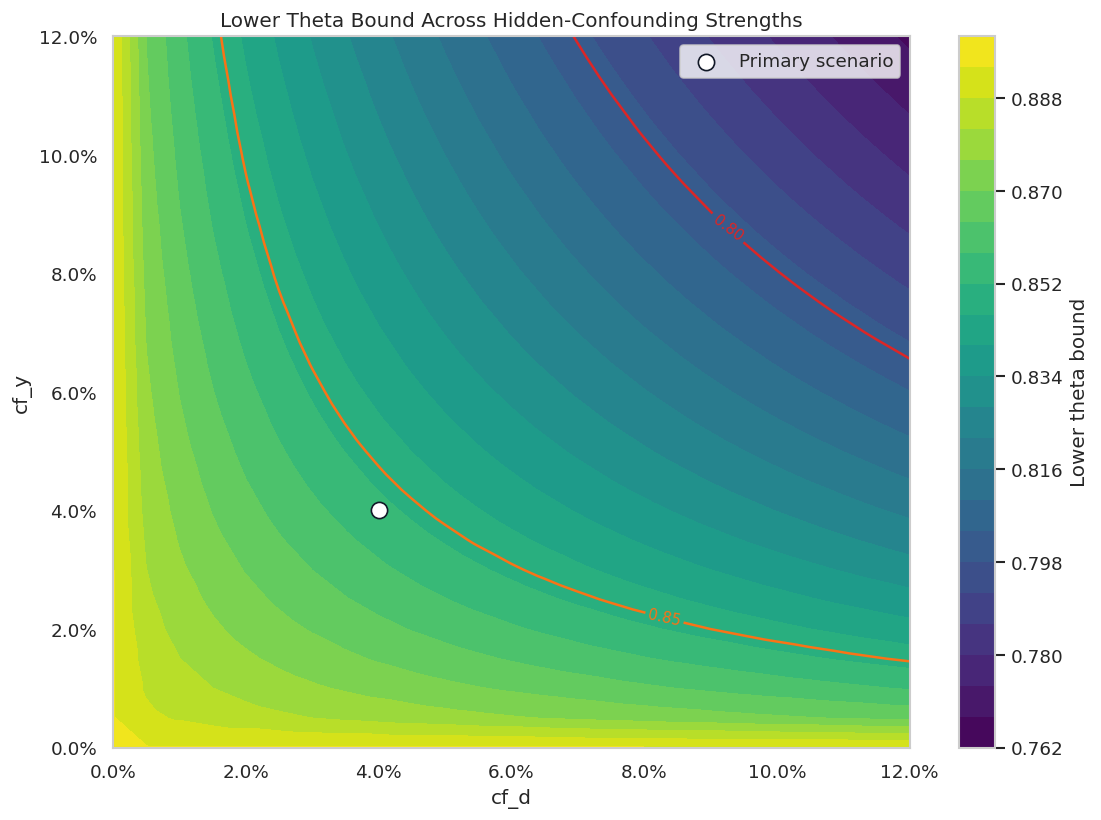
cf_y: how much residual outcome variation a hidden confounder could explain;cf_d: how much the hidden confounder could change the treatment-side score representation;rho: how adversarially the outcome-side and treatment-side hidden components are aligned.
The most conservative setting is usually rho = 1.0, meaning the hidden confounding works in the direction that most weakens the reported conclusion.
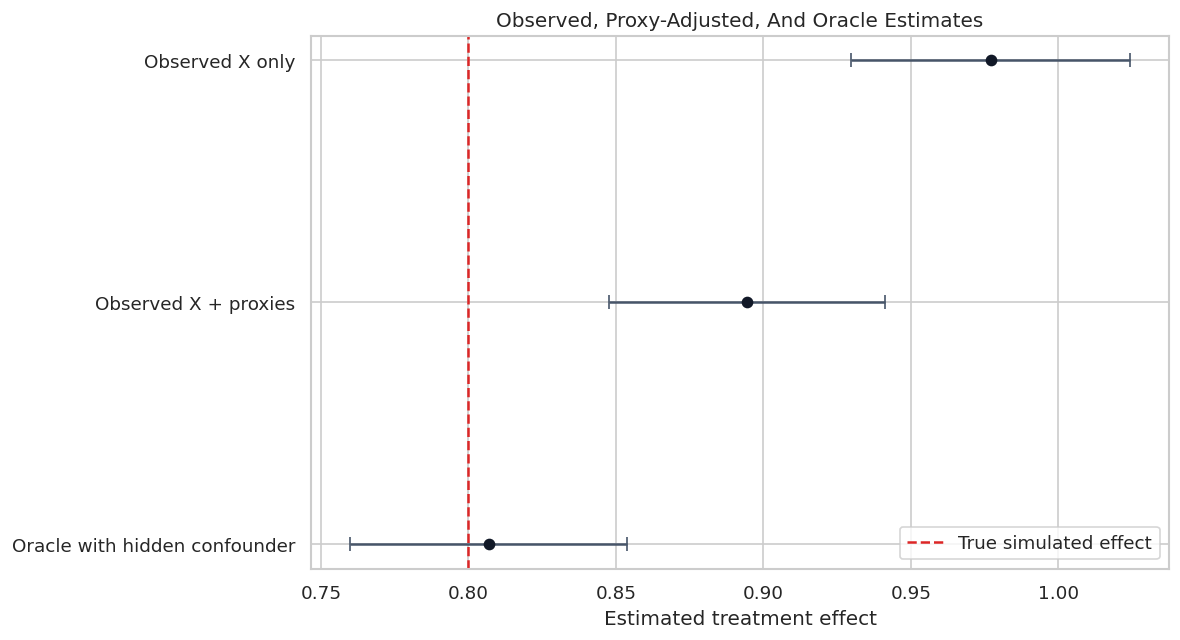
We use a synthetic PLR design where we know the hidden confounder. We fit three models:
- observed controls only,
- observed controls plus imperfect proxy controls,
- an oracle model that includes the hidden confounder.
Only the first two are realistic. The oracle model exists so students can see what hidden confounding is doing. After fitting the realistic proxy-adjusted model, we run DoubleML sensitivity analysis, calibrate the sensitivity parameters using observed proxy benchmarks, and build reporting language that does not overstate what sensitivity analysis can prove.
Expected runtime: usually under one minute. Most cells are fast; the benchmark cell refits a few DoubleML models to calibrate observed-variable benchmarks.
Dataset and Experiment Setup
We use controlled semi-synthetic datasets with known nuisance functions or known treatment effects to study Sensitivity Analysis For Unobserved Confounding. Double machine learning is easiest to understand when the data contain realistic nuisance structure but still give us a benchmark for the target parameter. That lets the lesson separate estimation error from identification failure.
Read each row as a unit with pre-treatment covariates, a treatment or instrument, and an outcome. The learner comparisons are experiments about orthogonalization, cross-fitting, overlap, sample splitting, and decision targets. The experiment centers on confounding and adjustment. The comparison of naive and adjusted estimates is the main diagnostic, more than a software call. The experiment shows a setting where treatment choice is endogenous and identification must come from a source of quasi-random variation.
The estimators are causal only under the stated design assumptions. Flexible machine-learning nuisance models help with prediction bias, but they do not replace causal identification.
Mathematical Foundation
Sensitivity analysis asks how large unobserved confounding would need to be to alter the conclusion. The threat is that an omitted variable \(U\) affects both treatment and outcome,
\[ D \not\perp\!\!\!\perp U \mid X, \qquad Y(d) \not\perp\!\!\!\perp U \mid X. \]
The estimate is stable only under restrictions on the strength of these two relationships. Sensitivity quantities are design diagnostics, not proof that hidden confounding is absent.
Tutorial Workflow
Setup
The code below prepares output folders, imports DoubleML and plotting libraries, and suppresses only known lesson-environment noise. The rest of the lesson keeps code visible by default so the sensitivity workflow can be inspected line by line.
The setup confirms that the lesson is using the local DoubleML installation and the shared tutorial output folder. All saved outputs in this lesson use prefix 13.
Helper Functions
These helpers keep the lesson focused on sensitivity logic. The most important helper is extract_sensitivity_row(), which turns DoubleML’s nested sensitivity_params dictionary into a tidy row.
DoubleML stores robustness values as fractions. The helper records both the fraction and percentage form because the text summary prints percentages.
# Define reusable helpers for the Helper Functions section.
def save_table(df, filename):
"""
Idea: Save a result table to the notebook table directory and return the same DataFrame for display.
Parameters
----------
df : pd.DataFrame
Rows used by this helper.
filename : str
Output filename used by the helper.
Returns
-------
pd.DataFrame
Same table after writing it to the tutorial table directory.
"""
path = TABLE_DIR / filename
df.to_csv(path, index=False)
return path
def save_dataset(df, filename):
"""
Idea: Write the constructed dataset to the tutorial output folder so later notebooks or cells can reuse it.
Parameters
----------
df : pd.DataFrame
Rows used by this helper.
filename : str
Output filename used by the helper.
Returns
-------
pd.DataFrame
Same dataset after writing it to the tutorial dataset directory.
"""
path = DATASET_DIR / filename
df.to_csv(path, index=False)
return path
def model_x_cols(df, include_proxies=True, include_hidden=False):
"""
Idea: Select the covariate columns used by the model while excluding treatment, outcome, and oracle columns.
Parameters
----------
df : pd.DataFrame
Rows used by this helper.
include_proxies : object
Whether proxy variables are included in the simulated design.
include_hidden : object
Whether the hidden confounder is included in the simulated design.
Returns
-------
list[str]
Covariate column names used as model inputs after excluding treatment, outcome, and oracle fields.
"""
cols = [f"x{i:02d}" for i in range(8)]
if include_proxies:
cols += ["proxy_light", "proxy_strong"]
if include_hidden:
cols += ["hidden_intent"]
return cols
def make_dml_data(df, include_proxies=True, include_hidden=False):
"""
Idea: Construct the double machine learning data used in the Helper Functions section, including columns needed for later diagnostics.
Parameters
----------
df : pd.DataFrame
Rows used by this helper.
include_proxies : object
Whether proxy variables are included in the simulated design.
include_hidden : object
Whether the hidden confounder is included in the simulated design.
Returns
-------
DoubleMLData
DoubleMLData object configured with outcome, treatment, and covariate columns for the tutorial estimator.
"""
return DoubleMLData(
df,
y_col=OUTCOME_COL,
d_cols=TREATMENT_COL,
x_cols=model_x_cols(df, include_proxies=include_proxies, include_hidden=include_hidden),
)
def rmse_metric(y_true, y_pred):
"""
Idea: Compute an RMSE value from a fitted learner and evaluation data.
Parameters
----------
y_true : array-like
Reference outcome, oracle value, or known target used for evaluation.
y_pred : array-like
Predicted outcome or estimated value being evaluated.
Returns
-------
float
Root mean squared prediction error for the fitted learner on evaluation data.
"""
mask = ~np.isnan(y_true)
return mean_squared_error(y_true[mask], y_pred[mask]) ** 0.5
def mae_metric(y_true, y_pred):
"""
Idea: Compute mean absolute error from a fitted learner and evaluation data.
Parameters
----------
y_true : array-like
Reference outcome, oracle value, or known target used for evaluation.
y_pred : array-like
Predicted outcome or estimated value being evaluated.
Returns
-------
float
Mean absolute prediction error for the fitted learner on evaluation data.
"""
mask = ~np.isnan(y_true)
return mean_absolute_error(y_true[mask], y_pred[mask])
def fit_plr(df, label, learner, include_proxies=True, include_hidden=False, n_folds=5, n_rep=2):
"""
Idea: Fit the partially linear regression model and return the fitted object or summary needed for interpretation.
Parameters
----------
df : pd.DataFrame
Rows used by this helper.
label : str
Short label attached to a scenario, method, or plotted result.
learner : object
Machine-learning learner used as a nuisance model or comparison model.
include_proxies : object
Whether proxy variables are included in the simulated design.
include_hidden : object
Whether the hidden confounder is included in the simulated design.
n_folds : int
Number of folds used for cross-fitting or validation.
n_rep : object
Number of repeated sample-splitting or simulation repetitions.
Returns
-------
DoubleMLPLR or tuple
Fitted PLR model, sometimes paired with a compact summary row.
"""
model = DoubleMLPLR(
make_dml_data(df, include_proxies=include_proxies, include_hidden=include_hidden),
ml_l=clone(learner),
ml_m=clone(learner),
n_folds=n_folds,
n_rep=n_rep,
)
model.fit()
ci = model.confint(level=0.95).iloc[0]
rmse = model.evaluate_learners(metric=rmse_metric)
row = {
"model": label,
"uses_proxies": include_proxies,
"uses_hidden_confounder": include_hidden,
"theta_hat": float(model.coef[0]),
"se": float(model.se[0]),
"ci_95_lower": float(ci.iloc[0]),
"ci_95_upper": float(ci.iloc[1]),
"true_theta": TRUE_THETA,
"bias_vs_true": float(model.coef[0] - TRUE_THETA),
"rmse_ml_l": float(rmse["ml_l"][0, 0]),
"rmse_ml_m": float(rmse["ml_m"][0, 0]),
}
return model, row
def extract_sensitivity_row(model, scenario, null_hypothesis):
"""
Idea: Extract the sensitivity row from a fitted object or result table so it can be reported consistently.
Parameters
----------
model : object
Fitted model or model specification used by the diagnostic.
scenario : str
Scenario label describing the data-generating or diagnostic condition.
null_hypothesis : object
Null value tested by the confidence interval or test statistic.
Returns
-------
dict[str, float]
Sensitivity-analysis summary row with robustness values and adjusted intervals.
"""
params = model.sensitivity_params
return {
"scenario": scenario,
"cf_y": float(params["input"]["cf_y"]),
"cf_d": float(params["input"]["cf_d"]),
"rho": float(params["input"]["rho"]),
"level": float(params["input"]["level"]),
"null_hypothesis": float(np.asarray(params["input"]["null_hypothesis"]).ravel()[0]),
"theta_hat": float(model.coef[0]),
"theta_lower": float(params["theta"]["lower"][0]),
"theta_upper": float(params["theta"]["upper"][0]),
"ci_lower": float(params["ci"]["lower"][0]),
"ci_upper": float(params["ci"]["upper"][0]),
"rv": float(params["rv"][0]),
"rva": float(params["rva"][0]),
"rv_percent": float(100 * params["rv"][0]),
"rva_percent": float(100 * params["rva"][0]),
"true_theta": TRUE_THETA,
"theta_lower_below_true": bool(float(params["theta"]["lower"][0]) <= TRUE_THETA),
"ci_lower_below_true": bool(float(params["ci"]["lower"][0]) <= TRUE_THETA),
}The helper functions make three choices explicit: which controls are observed, whether proxy variables are included, and whether the hidden confounder is used in an oracle-only model.
Diagnostics and Interpretation
Sensitivity Vocabulary
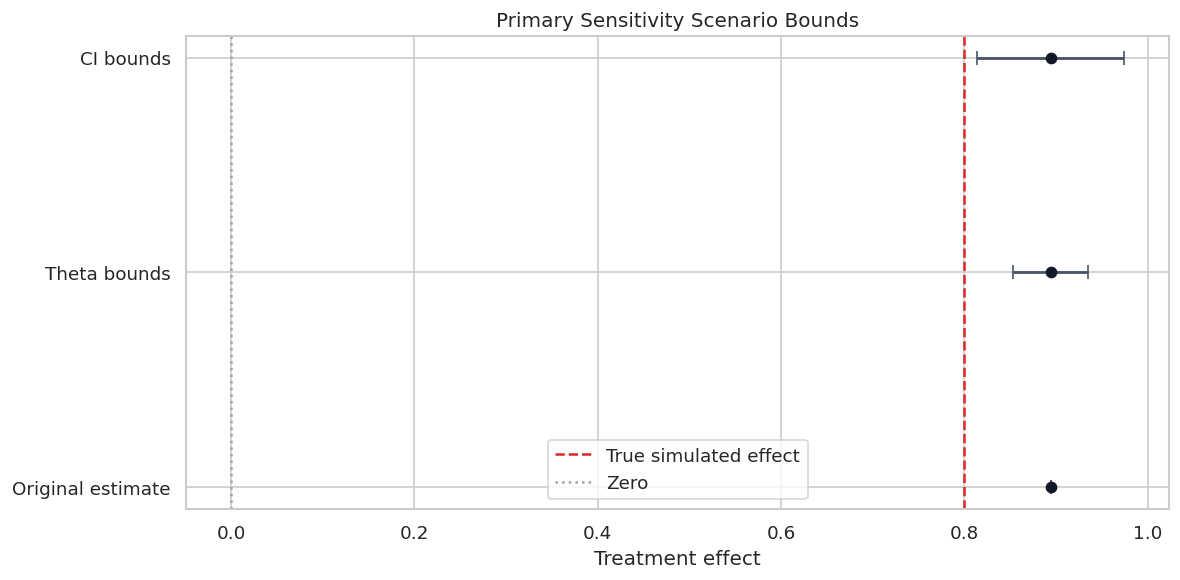
This table defines the main quantities used in DoubleML sensitivity analysis. The names are compact in the API, so it helps to write their meaning before using them.
| term | meaning | practical reading |
|---|---|---|
| cf_y | Share of residual outcome variation that a hidden confounder could explain. | Larger values mean a hidden variable predicts the outcome residual more strongly. |
| cf_d | Share-like strength for how much hidden confounding can affect the treatment-side score representation. | Larger values mean a hidden variable is more connected to treatment assignment after observed controls. |
| rho | Alignment between hidden outcome-side and treatment-side components. | rho = 1 is adversarial for a positive effect; lower absolute values are less extreme. |
| theta bounds | Bounds on the point estimate under a sensitivity scenario. | How far the effect estimate could move under the specified hidden confounding strength. |
| CI bounds | Sensitivity bounds that also include statistical uncertainty. | The conservative uncertainty range under the specified hidden confounding scenario. |
| RV | Robustness value for moving the estimate to the null hypothesis. | How strong confounding needs to be to move the point estimate to the target null. |
| RVa | Robustness value adjusted for statistical uncertainty. | How strong confounding needs to be to make the uncertainty-adjusted conclusion touch the target null. |
The main habit is to treat these values as stress-test parameters. They help structure a discussion about hidden confounding; they do not reveal whether the hidden confounder actually exists.
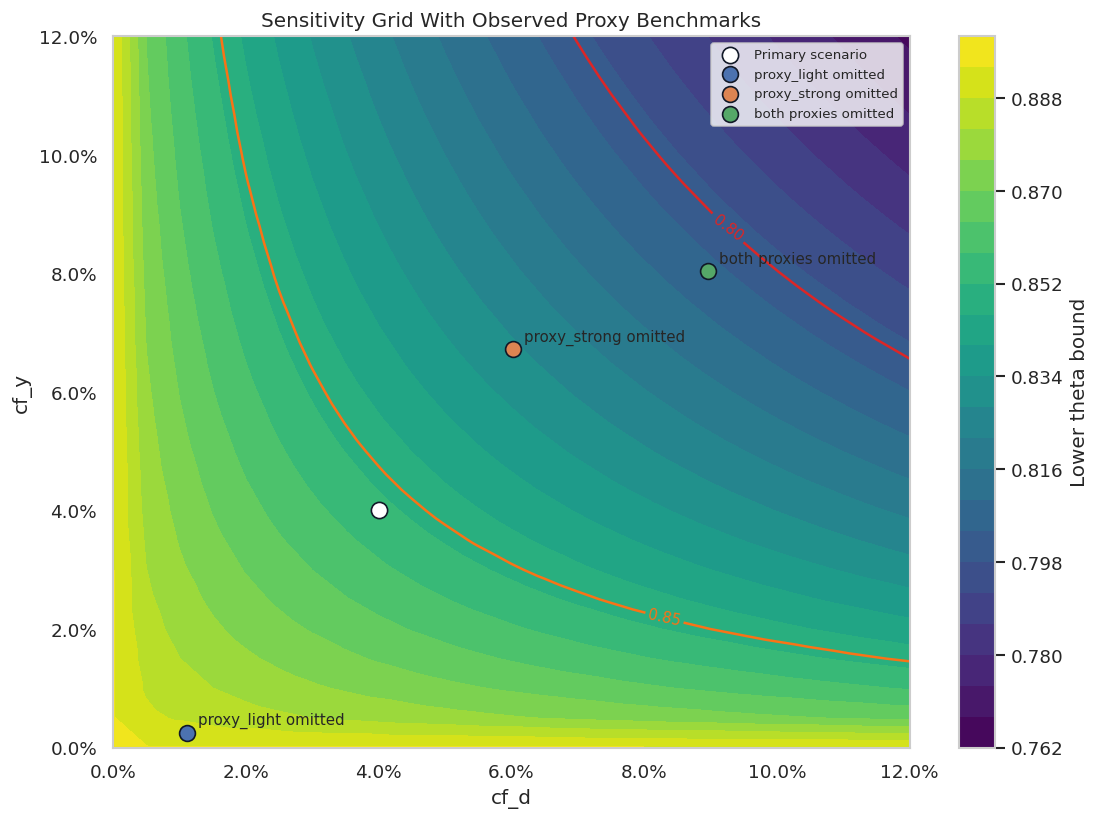
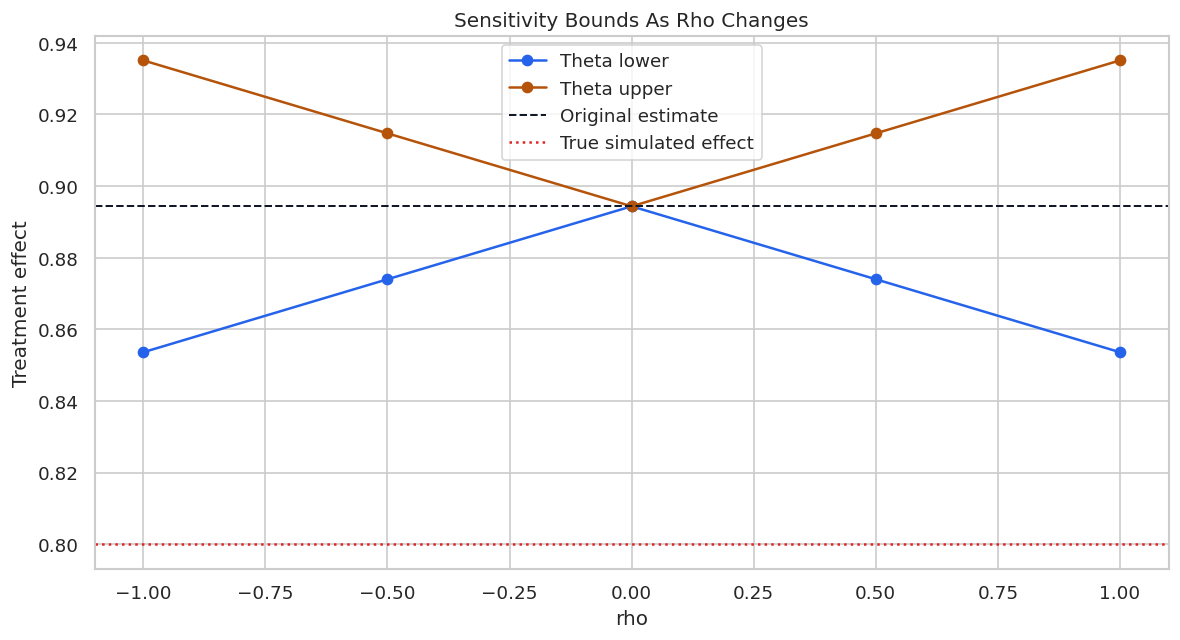
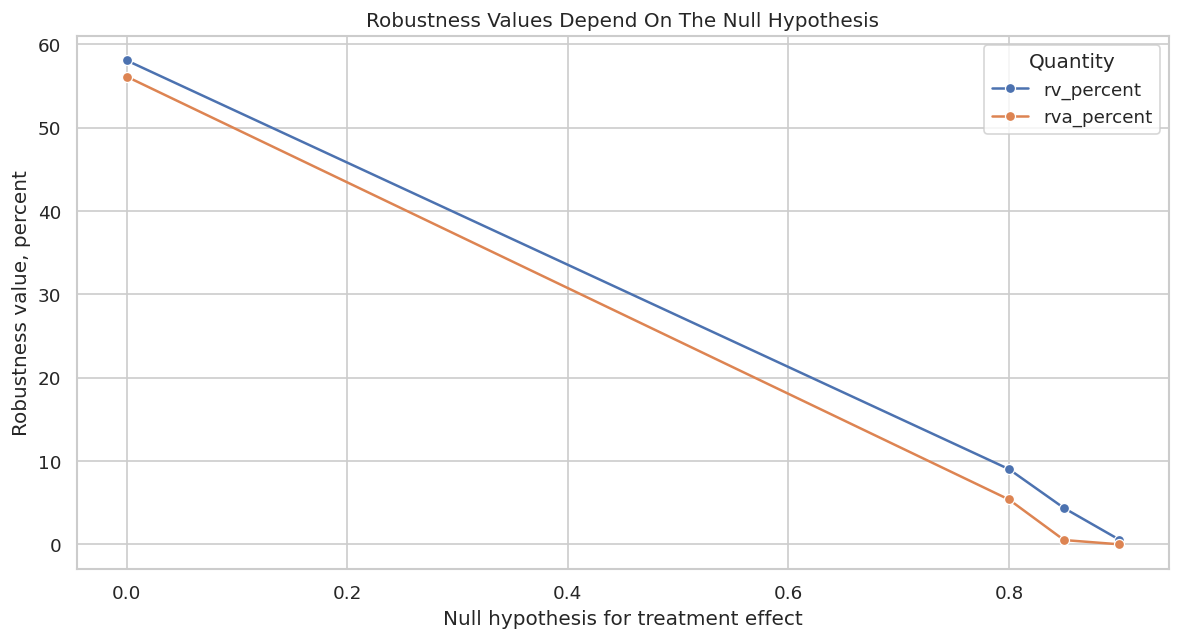
Reporting and Takeaways
Practical Reporting Language
The table below translates common sensitivity findings into careful reporting language. The goal is to avoid overstating what the analysis can prove.
| finding | careful wording | avoid saying |
|---|---|---|
| Point estimate remains positive under modest sensitivity scenario | Under the specified hidden-confounding scenario, the sensitivity-adjusted lower bound remains positive. | Hidden confounding is impossible. |
| Benchmark-calibrated scenario moves the estimate materially | A hidden factor comparable to the benchmarked observed proxies could materially reduce the estimate. | The benchmark proves the true bias size. |
| Robustness value to zero is high | Moving the point estimate to zero would require a hidden confounder of the reported strength under the model assumptions. | The result is automatically causal. |
| RVa is much lower than RV | Accounting for sampling uncertainty makes the conclusion more sensitive than the point estimate alone suggests. | The point-estimate robustness value is enough by itself. |
Careful wording keeps sensitivity analysis in its proper role: a stress test for assumptions, not a replacement for design validation.
This matters because the software can only estimate the intended causal quantity when the variables have been assigned to the right design roles.
Validation Plan
Sensitivity analysis should lead to better data questions. The table below lists concrete follow-up actions an analyst could take after seeing the sensitivity results.
| risk | diagnostic_or_action | expected benefit |
|---|---|---|
| Important unobserved user intent remains after proxy adjustment | Search for richer pre-treatment proxies or historical behavior features. | Reduce plausible cf_y and cf_d by measuring the hidden source more directly. |
| Treatment timing may follow outcome anticipation | Audit feature timestamps and remove post-treatment variables from controls. | Protect the design from bad-control bias and reverse timing. |
| Benchmark variables are weak comparisons for the hidden confounder | Benchmark several observed covariate groups separately and jointly. | Give readers multiple scales for plausible hidden-confounder strength. |
| Sensitivity bounds are close to the decision threshold | Use a stronger design where possible: experiment, instrument, panel design, or negative control. | Shift credibility from modeling assumptions toward design-based evidence. |
A good sensitivity section does not end with a number. It should explain what data or design improvement would reduce the remaining uncertainty.
The lesson is robustness: a publishable conclusion should not hinge on one arbitrary threshold, one lucky sample split, or one narrow tuning choice.
Reporting and Takeaways
A finished analysis should be easy for another careful reader to review. It should state the causal question, target estimand, identification assumptions, main estimate, diagnostics, sensitivity checks, and remaining limitations in plain language. The goal is a clear analytical conclusion supported by the tables and figures already shown in the lesson.
The lesson now has a full DoubleML sensitivity workflow: omitted-confounding setup, realistic and oracle models, sensitivity bounds, observed-variable benchmarks, rho stress testing, robustness values, and reporting guidance.
What Comes Next
The sequence next moves to heterogeneous treatment effects, including GATE, CATE-style summaries, best linear predictors, and careful language around subgroup exploration.