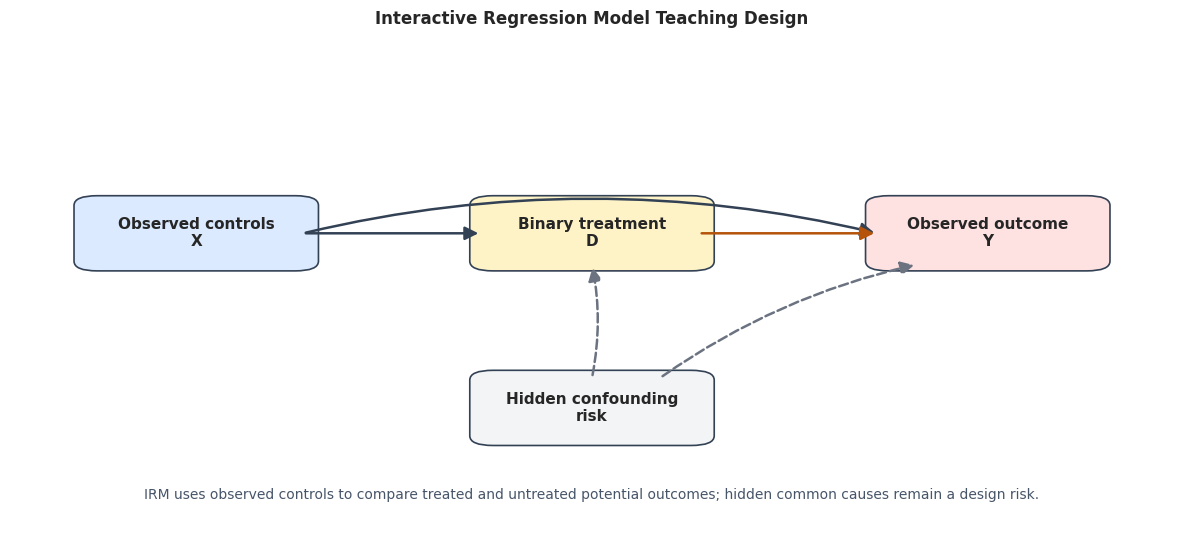
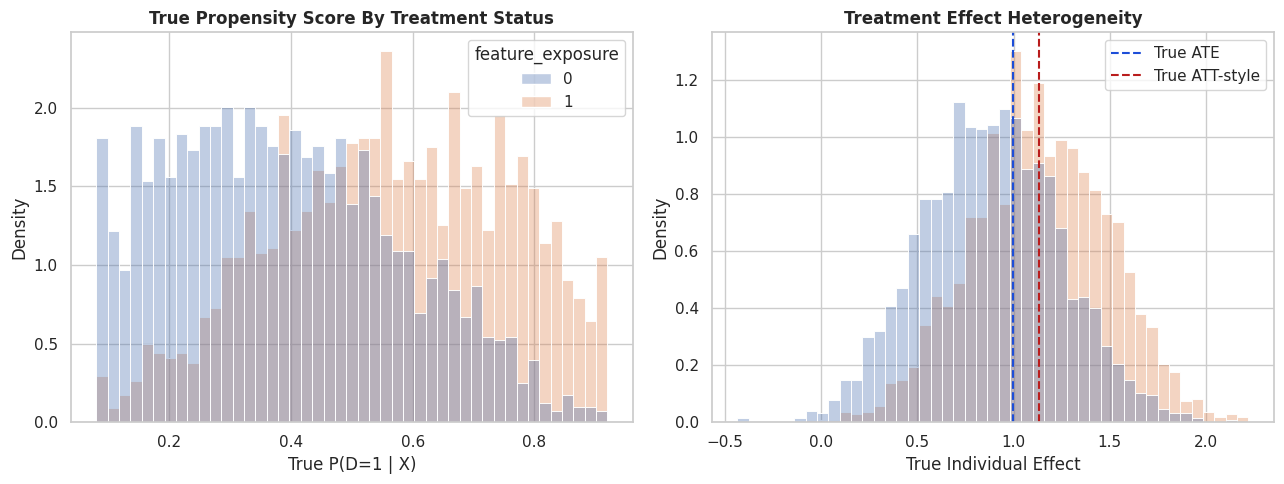
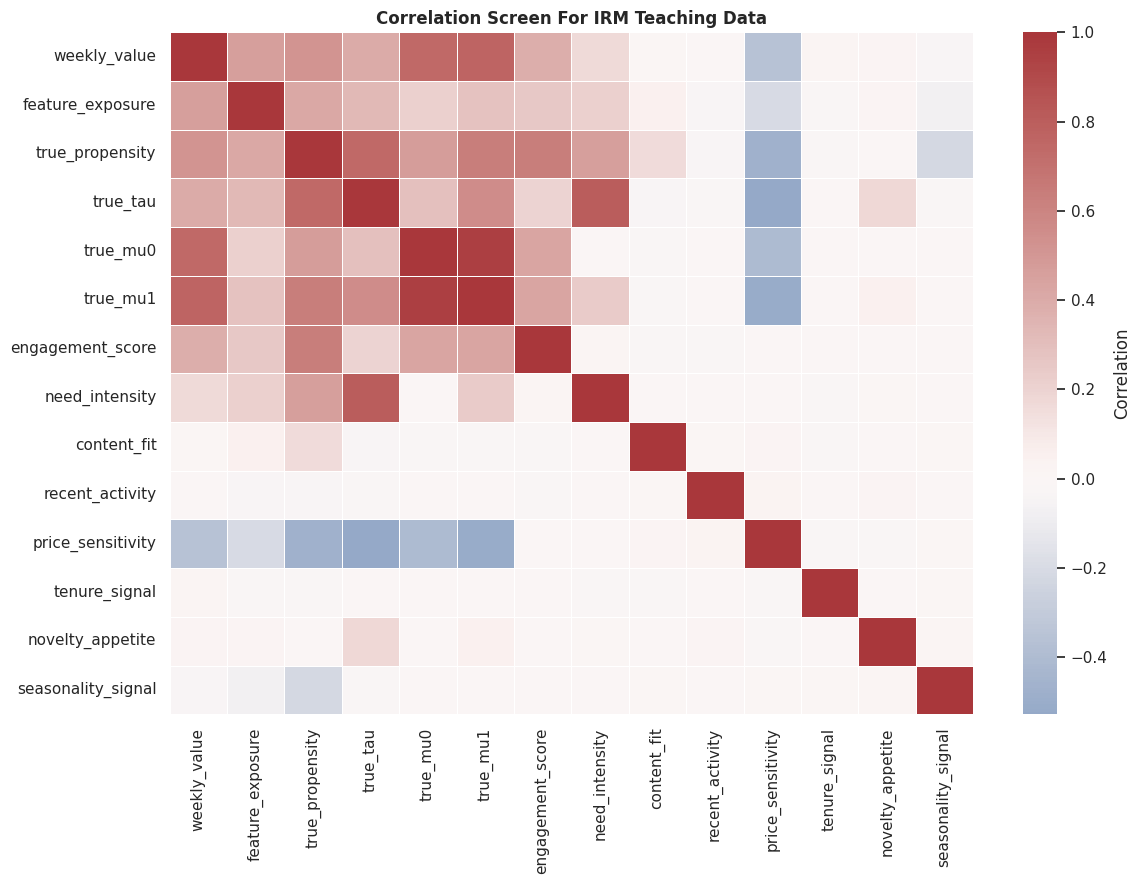
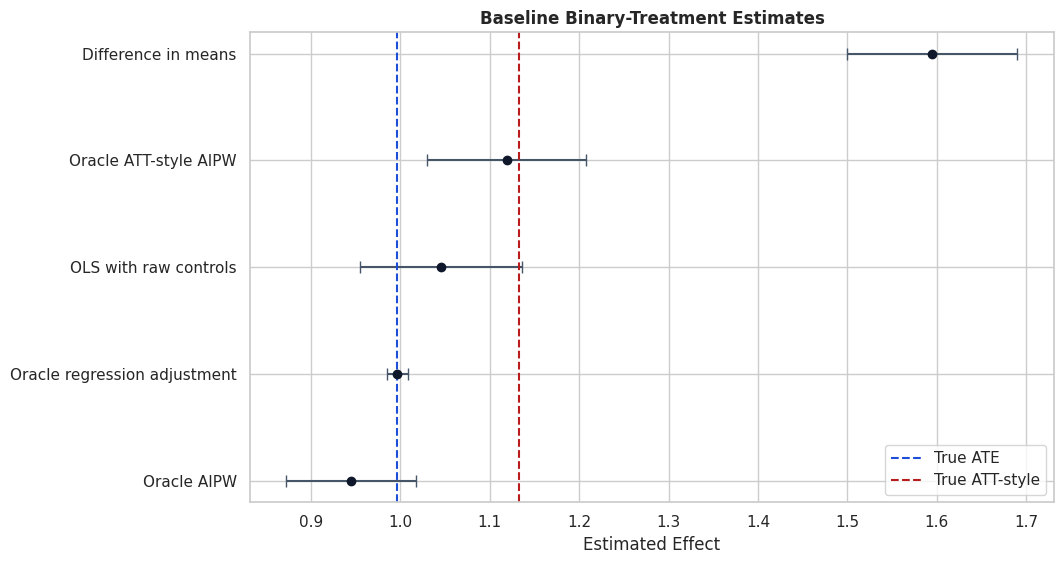
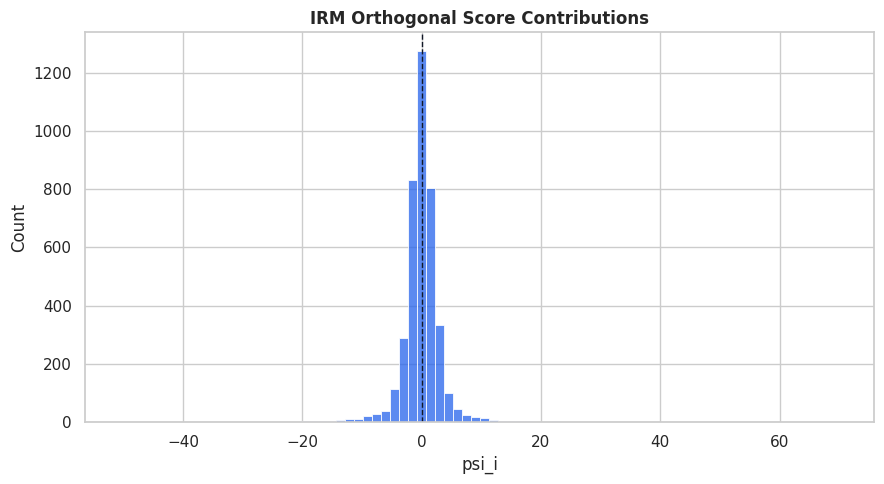
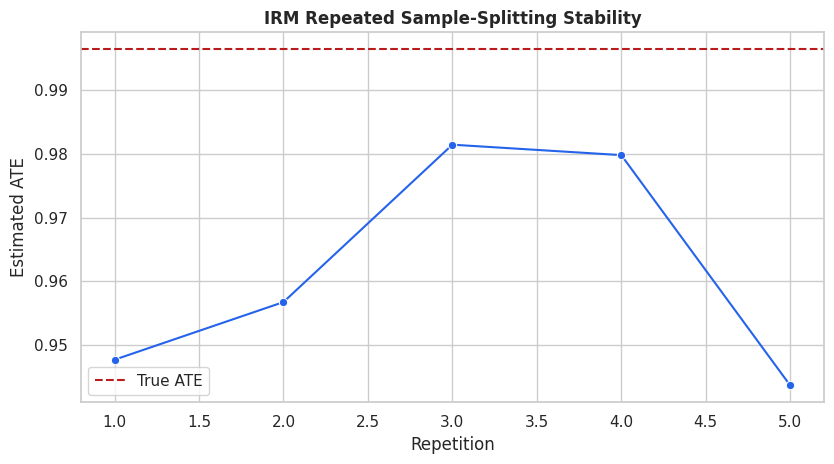
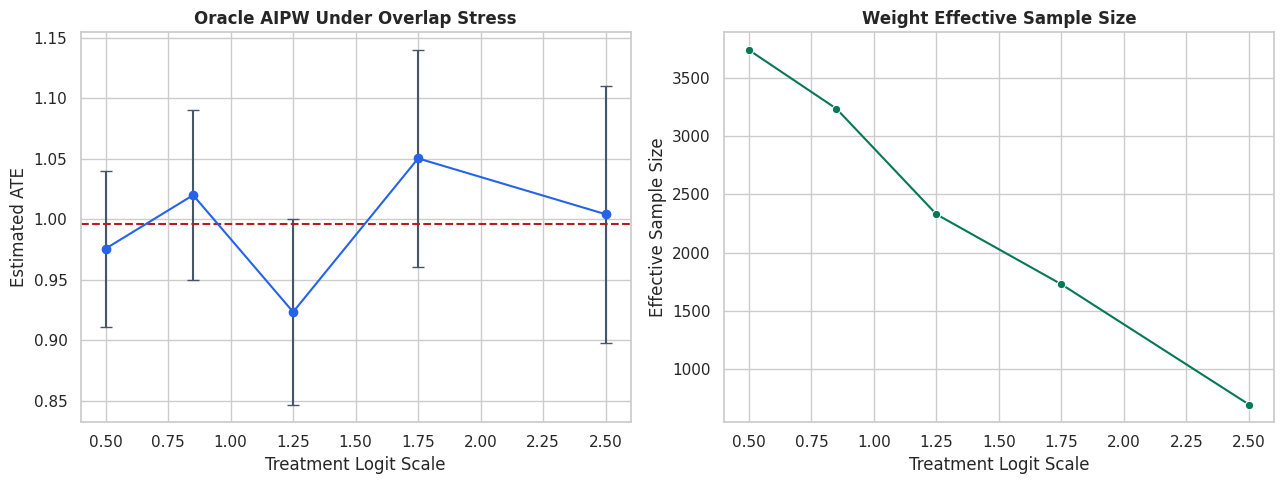
# Define reusable helpers for the Helper Functions section.
def save_table(df, name):
"""
Idea: Save a result table to the notebook table directory and return the same DataFrame for display.
Parameters
----------
df : pd.DataFrame
Rows used by this helper.
name : str
Short name used for the scenario label.
Returns
-------
pd.DataFrame
Same table after writing it to the tutorial table directory.
"""
path = TABLE_DIR / f"{NOTEBOOK_PREFIX}_{name}.csv"
df.to_csv(path, index=False)
return df
def sigmoid(x):
"""
Idea: Map a linear score to a probability on the 0 to 1 scale for treatment assignment or simulation logic.
Parameters
----------
x : str or array-like
First variable, column name, or numeric input in the comparison.
Returns
-------
np.ndarray
Probability-scale values obtained by applying the logistic transform elementwise.
"""
return 1.0 / (1.0 + np.exp(-x))
def rmse(y_true, y_pred):
"""
Idea: Compute root mean squared error between an oracle target and an estimated or predicted value.
Parameters
----------
y_true : array-like
Reference outcome, oracle value, or known target used for evaluation.
y_pred : array-like
Predicted outcome or estimated value being evaluated.
Returns
-------
float
Root mean squared error between the reference values and predictions.
"""
return float(np.sqrt(mean_squared_error(y_true, y_pred)))
def treatment_ols_summary(y, X, treatment_col, label):
"""
Idea: Assemble a summary of the treatment OLS summary with the quantities needed for interpretation.
Parameters
----------
y : str or array-like
Outcome, second variable, or numeric input in the comparison.
X : pd.DataFrame or np.ndarray
Feature matrix containing pre-treatment covariates or effect modifiers.
treatment_col : str
Name of the treatment or intervention column.
label : str
Short label attached to a scenario, method, or plotted result.
Returns
-------
dict[str, float]
Treatment-slope summary row from the fitted OLS model.
"""
X_design = sm.add_constant(X, has_constant="add")
fit = sm.OLS(y, X_design).fit(cov_type="HC1")
row = fit.summary2().tables[1].loc[treatment_col]
return {
"estimator": label,
"target": "raw regression slope",
"theta_hat": float(row["Coef."]),
"std_error": float(row["Std.Err."]),
"ci_95_lower": float(row["[0.025"]),
"ci_95_upper": float(row["0.975]"]),
"p_value": float(row["P>|z|"]),
}
def mean_difference_summary(y, d, label):
"""
Idea: Assemble a summary of the mean difference summary with the quantities needed for interpretation.
Parameters
----------
y : str or array-like
Outcome, second variable, or numeric input in the comparison.
d : object
Treatment or decision indicator used by the causal score.
label : str
Short label attached to a scenario, method, or plotted result.
Returns
-------
dict[str, float]
Treated-control mean-difference summary with estimate, standard error, interval, and target label.
"""
treated = y[d == 1]
untreated = y[d == 0]
theta_hat = float(treated.mean() - untreated.mean())
std_error = float(np.sqrt(treated.var(ddof=1) / len(treated) + untreated.var(ddof=1) / len(untreated)))
return {
"estimator": label,
"target": "unadjusted mean difference",
"theta_hat": theta_hat,
"std_error": std_error,
"ci_95_lower": theta_hat - 1.96 * std_error,
"ci_95_upper": theta_hat + 1.96 * std_error,
"p_value": np.nan,
}
def aipw_ate(y, d, g0_hat, g1_hat, m_hat, label):
"""
Idea: Estimate an ATE with an augmented inverse-propensity weighted signal.
Parameters
----------
y : str or array-like
Outcome, second variable, or numeric input in the comparison.
d : object
Treatment or decision indicator used by the causal score.
g0_hat : object
Estimated control-outcome regression prediction.
g1_hat : object
Estimated treated-outcome regression prediction.
m_hat : object
Estimated treatment or propensity nuisance prediction used by the orthogonal score.
label : str
Short label attached to a scenario, method, or plotted result.
Returns
-------
dict[str, float]
AIPW ATE summary row with estimate, standard error, confidence interval, and p-value fields.
"""
m_hat = np.clip(np.asarray(m_hat), 0.02, 0.98)
score = g1_hat - g0_hat + d * (y - g1_hat) / m_hat - (1 - d) * (y - g0_hat) / (1 - m_hat)
theta_hat = float(np.mean(score))
std_error = float(np.std(score, ddof=1) / np.sqrt(len(score)))
return {
"estimator": label,
"target": "ATE",
"theta_hat": theta_hat,
"std_error": std_error,
"ci_95_lower": theta_hat - 1.96 * std_error,
"ci_95_upper": theta_hat + 1.96 * std_error,
"p_value": np.nan,
}
def aipw_att(y, d, g0_hat, m_hat, label):
"""
Idea: Estimate an ATT with an augmented inverse-propensity weighted signal for treated units.
Parameters
----------
y : str or array-like
Outcome, second variable, or numeric input in the comparison.
d : object
Treatment or decision indicator used by the causal score.
g0_hat : object
Estimated control-outcome regression prediction.
m_hat : object
Estimated treatment or propensity nuisance prediction used by the orthogonal score.
label : str
Short label attached to a scenario, method, or plotted result.
Returns
-------
dict[str, float]
AIPW ATT-style summary row with estimate, standard error, confidence interval, and p-value fields.
"""
m_hat = np.clip(np.asarray(m_hat), 0.02, 0.98)
p_treated = float(np.mean(d))
score = d * (y - g0_hat) / p_treated - (1 - d) * m_hat * (y - g0_hat) / ((1 - m_hat) * p_treated)
theta_hat = float(np.mean(score))
std_error = float(np.std(score, ddof=1) / np.sqrt(len(score)))
return {
"estimator": label,
"target": "ATT-style",
"theta_hat": theta_hat,
"std_error": std_error,
"ci_95_lower": theta_hat - 1.96 * std_error,
"ci_95_upper": theta_hat + 1.96 * std_error,
"p_value": np.nan,
}
def ipw_ate(y, d, m_hat, label):
"""
Idea: Estimate an ATE by reweighting observed outcomes with inverse propensity weights.
Parameters
----------
y : str or array-like
Outcome, second variable, or numeric input in the comparison.
d : object
Treatment or decision indicator used by the causal score.
m_hat : object
Estimated treatment or propensity nuisance prediction used by the orthogonal score.
label : str
Short label attached to a scenario, method, or plotted result.
Returns
-------
dict[str, float]
IPW ATE summary row with estimate, standard error, confidence interval, and p-value fields.
"""
m_hat = np.clip(np.asarray(m_hat), 0.02, 0.98)
score = d * y / m_hat - (1 - d) * y / (1 - m_hat)
theta_hat = float(np.mean(score))
std_error = float(np.std(score, ddof=1) / np.sqrt(len(score)))
return {
"estimator": label,
"target": "ATE",
"theta_hat": theta_hat,
"std_error": std_error,
"ci_95_lower": theta_hat - 1.96 * std_error,
"ci_95_upper": theta_hat + 1.96 * std_error,
"p_value": np.nan,
}
def weighted_effective_sample_size(weights):
"""
Idea: Compute the effective sample size implied by the supplied observation weights.
Parameters
----------
weights : array-like
Observation weights defining the target population or policy objective.
Returns
-------
float
Effective sample size implied by the supplied observation weights.
"""
weights = np.asarray(weights)
return float((weights.sum() ** 2) / np.sum(weights ** 2))
def crossfit_irm_nuisances(X, y, d, outcome_learner, propensity_learner, n_splits=5, random_state=RANDOM_STATE):
"""
Idea: Cross-fit the nuisance models for the crossfit interactive regression model nuisances design so evaluation uses out-of-fold predictions.
Parameters
----------
X : pd.DataFrame or np.ndarray
Feature matrix containing pre-treatment covariates or effect modifiers.
y : str or array-like
Outcome, second variable, or numeric input in the comparison.
d : object
Treatment or decision indicator used by the causal score.
outcome_learner : object
Model used to learn the outcome regression nuisance function.
propensity_learner : object
Model used to estimate treatment propensity scores.
n_splits : object
Number of folds or sample splits used for cross-fitting.
random_state : int
Random-state value used to make sampling or model fitting reproducible.
Returns
-------
tuple[np.ndarray, np.ndarray, np.ndarray]
Out-of-fold control outcome, treated outcome, and propensity predictions.
"""
cv = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
g0_hat = np.zeros(len(y))
g1_hat = np.zeros(len(y))
m_hat = np.zeros(len(y))
for train_idx, test_idx in cv.split(X):
X_train = X.iloc[train_idx]
X_test = X.iloc[test_idx]
y_train = y[train_idx]
d_train = d[train_idx]
g0_model = clone(outcome_learner).fit(X_train[d_train == 0], y_train[d_train == 0])
g1_model = clone(outcome_learner).fit(X_train[d_train == 1], y_train[d_train == 1])
m_model = clone(propensity_learner).fit(X_train, d_train)
g0_hat[test_idx] = g0_model.predict(X_test)
g1_hat[test_idx] = g1_model.predict(X_test)
m_hat[test_idx] = m_model.predict_proba(X_test)[:, 1]
return g0_hat, g1_hat, np.clip(m_hat, 0.02, 0.98)
def prediction_vector(doubleml_model, learner_key):
"""
Idea: Return predictions from a learner as a flat numeric vector with shape compatible with later diagnostics.
Parameters
----------
doubleml_model : object
Model object used for `doubleml` fitting, prediction, or comparison.
learner_key : object
Dictionary key identifying which learner configuration is being evaluated.
Returns
-------
np.ndarray
One-dimensional prediction array aligned with the evaluation rows.
"""
arr = np.asarray(doubleml_model.predictions[learner_key])
if arr.ndim != 3:
raise ValueError(f"Expected a 3D prediction array, got shape {arr.shape}")
return arr[:, 0, 0]
def learner_loss_table(doubleml_model, model_label):
"""
Idea: Assemble a DataFrame for the learner loss table so the result can be displayed and saved consistently.
Parameters
----------
doubleml_model : object
Model object used for `doubleml` fitting, prediction, or comparison.
model_label : str
Display label for `model`.
Returns
-------
pd.DataFrame
Out-of-fold nuisance prediction loss table by learner and nuisance role.
"""
losses = doubleml_model.evaluate_learners()
rows = []
for learner_name, values in losses.items():
arr = np.asarray(values)
rows.append(
{
"model": model_label,
"learner": learner_name,
"mean_loss": float(np.mean(arr)),
"min_loss": float(np.min(arr)),
"max_loss": float(np.max(arr)),
}
)
return pd.DataFrame(rows)