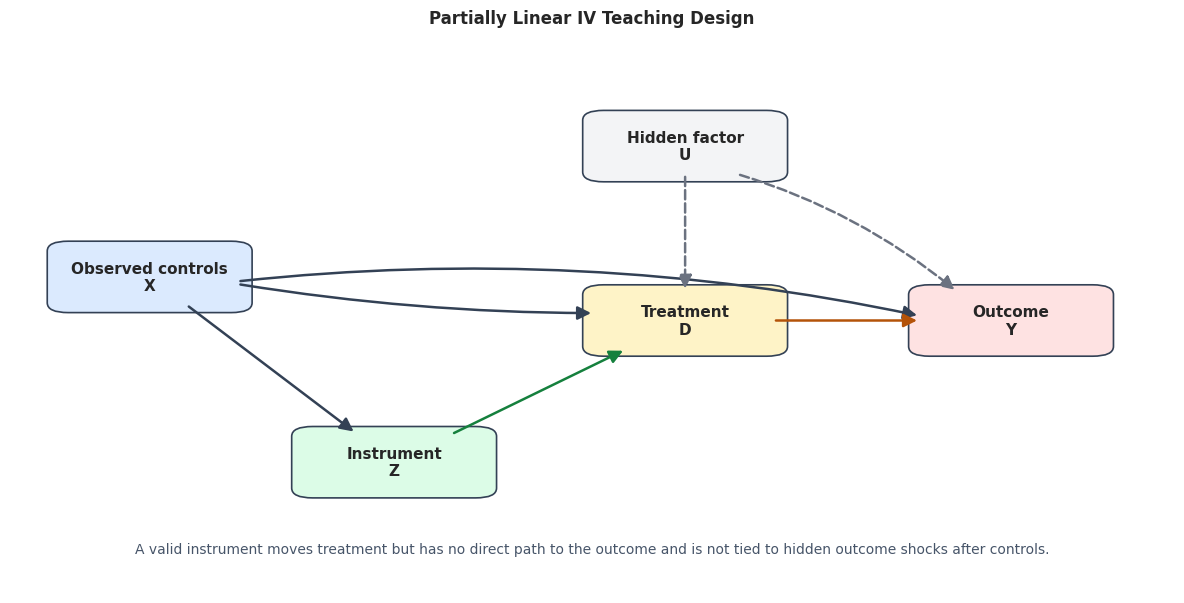
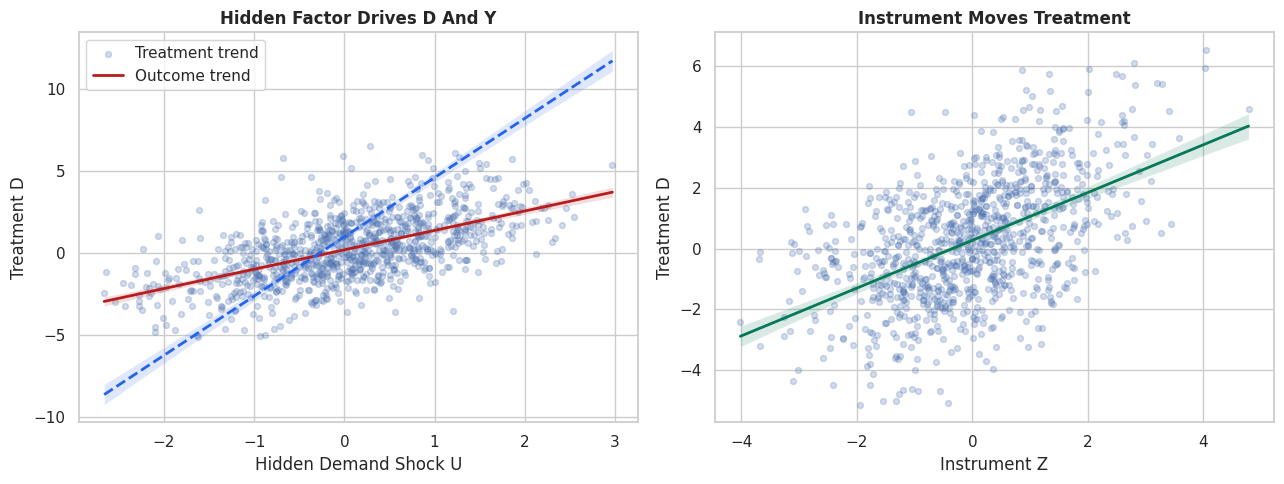
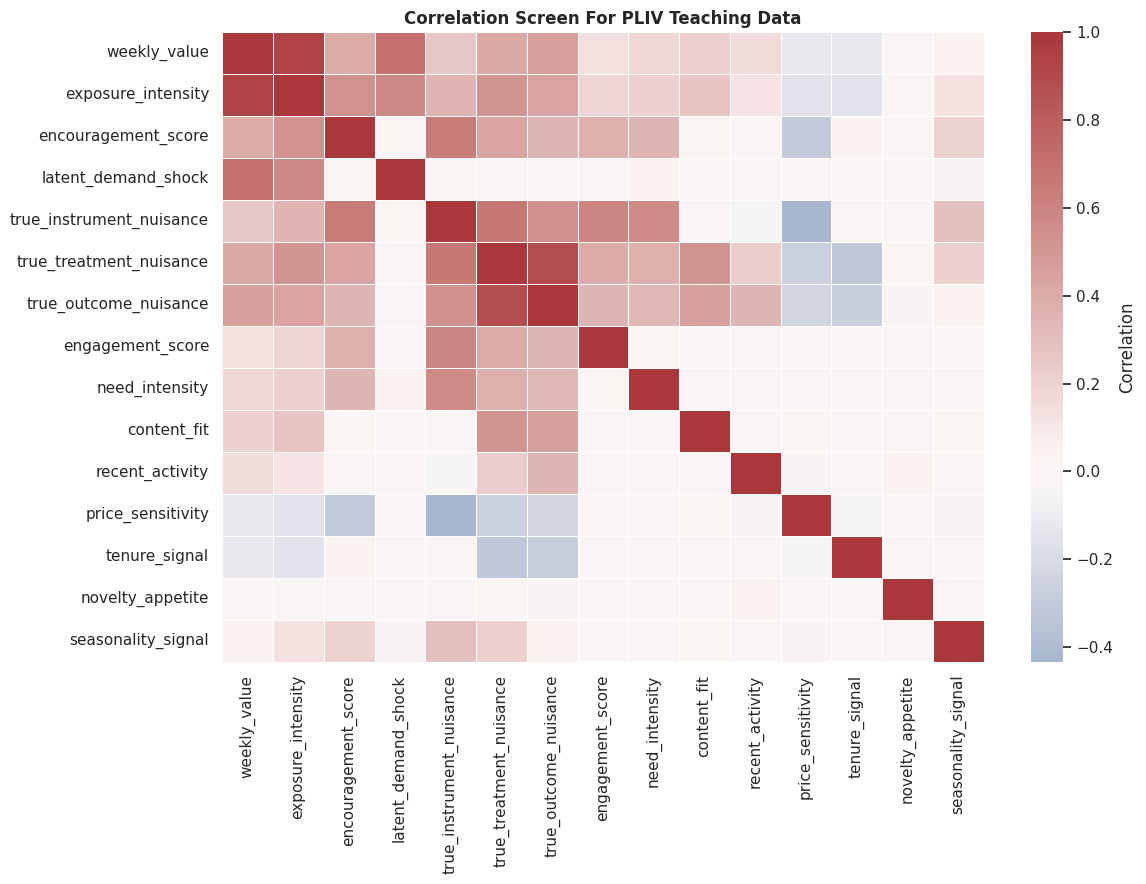
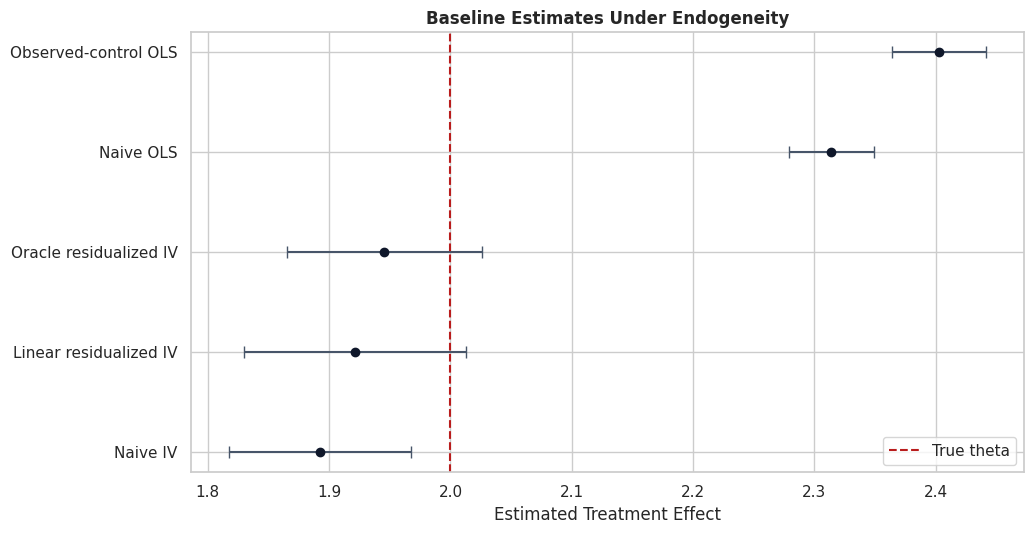
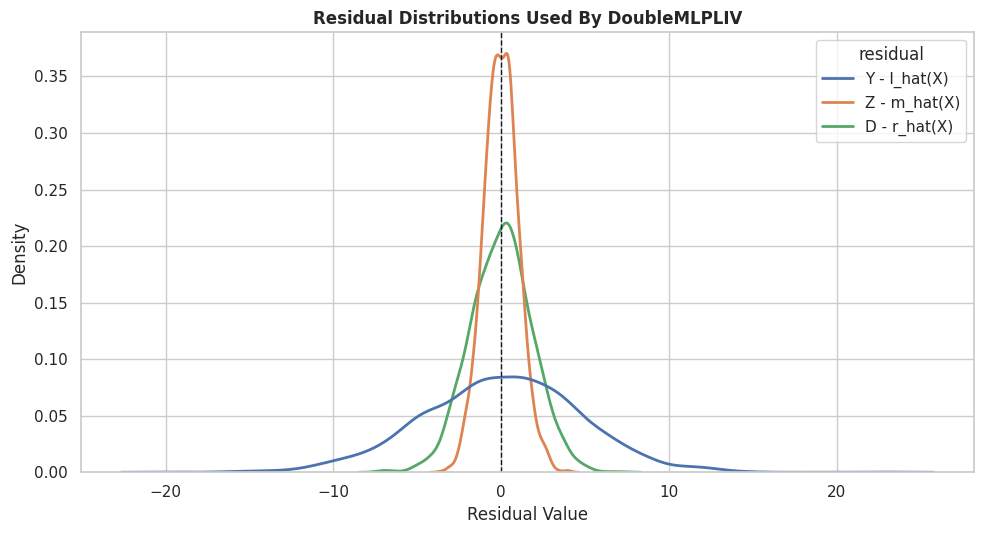
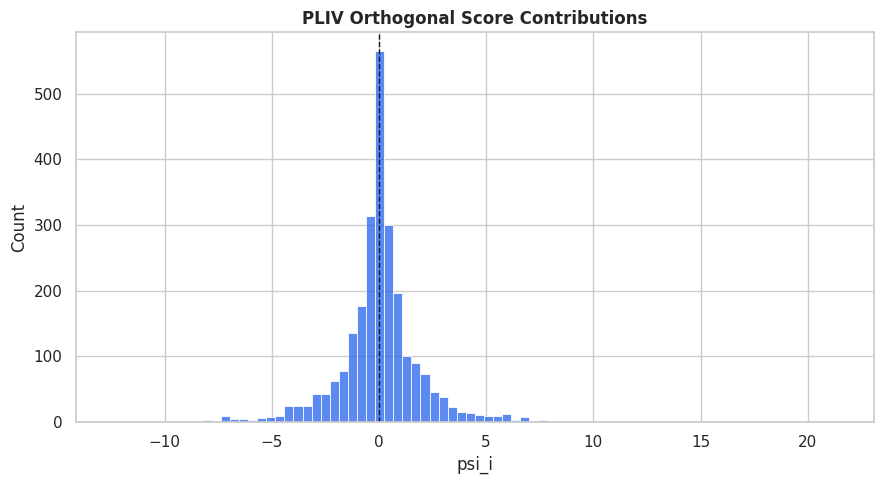
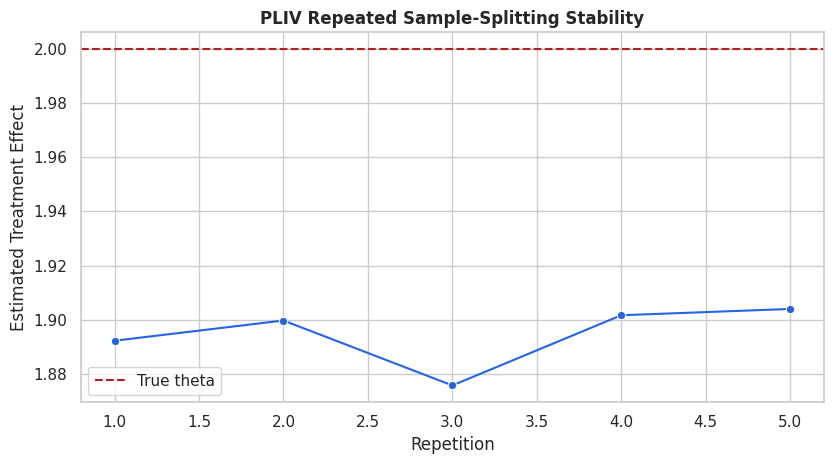
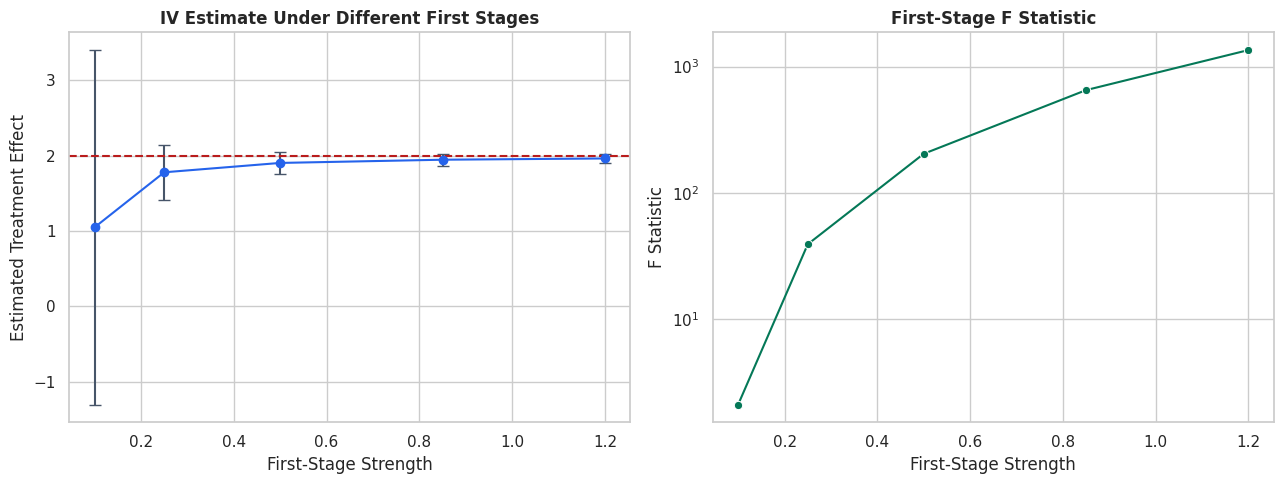
# Define reusable helpers for the Draw The IV Design section.
from matplotlib.patches import FancyBboxPatch, FancyArrowPatch
nodes = {
"X": {"xy": (0.12, 0.58), "label": "Observed controls\nX", "color": "#dbeafe"},
"Z": {"xy": (0.33, 0.24), "label": "Instrument\nZ", "color": "#dcfce7"},
"D": {"xy": (0.58, 0.50), "label": "Treatment\nD", "color": "#fef3c7"},
"Y": {"xy": (0.86, 0.50), "label": "Outcome\nY", "color": "#fee2e2"},
"U": {"xy": (0.58, 0.82), "label": "Hidden factor\nU", "color": "#f3f4f6"},
}
edge_specs = [
("X", "Z", "#334155", "solid", 0.00),
("X", "D", "#334155", "solid", 0.04),
("X", "Y", "#334155", "solid", -0.08),
("Z", "D", "#15803d", "solid", 0.00),
("D", "Y", "#b45309", "solid", 0.00),
("U", "D", "#6b7280", "dashed", 0.00),
("U", "Y", "#6b7280", "dashed", -0.10),
]
fig, ax = plt.subplots(figsize=(12, 6.2))
ax.set_axis_off()
box_w, box_h = 0.14, 0.095
def edge_endpoint(source_xy, target_xy, from_source=True):
"""
Return a point just outside the source or target box boundary.
Parameters
----------
source_xy : tuple[float, float]
Starting coordinate for a drawn edge.
target_xy : tuple[float, float]
Ending coordinate for a drawn edge.
from_source : bool
Whether to compute the boundary point from the source side of the edge.
Returns
-------
tuple[float, float]
Adjusted endpoint coordinate for a directed or partially directed graph edge.
"""
x0, y0 = source_xy
x1, y1 = target_xy
dx, dy = x1 - x0, y1 - y0
scale = 1.0 / max(abs(dx) / (box_w / 2), abs(dy) / (box_h / 2))
if from_source:
return (x0 + dx * scale * 1.08, y0 + dy * scale * 1.08)
return (x1 - dx * scale * 1.12, y1 - dy * scale * 1.12)
for spec in nodes.values():
x, y = spec["xy"]
rect = FancyBboxPatch(
(x - box_w / 2, y - box_h / 2),
box_w,
box_h,
boxstyle="round,pad=0.018",
facecolor=spec["color"],
edgecolor="#334155",
linewidth=1.2,
zorder=3,
)
ax.add_patch(rect)
ax.text(x, y, spec["label"], ha="center", va="center", fontsize=11, fontweight="bold", zorder=4)
for start, end, color, style, rad in edge_specs:
start_xy = edge_endpoint(nodes[start]["xy"], nodes[end]["xy"], from_source=True)
end_xy = edge_endpoint(nodes[start]["xy"], nodes[end]["xy"], from_source=False)
arrow = FancyArrowPatch(
start_xy,
end_xy,
arrowstyle="-|>",
mutation_scale=20,
linewidth=1.8,
color=color,
linestyle=style,
connectionstyle=f"arc3,rad={rad}",
zorder=5,
)
ax.add_patch(arrow)
ax.text(
0.50,
0.08,
"A valid instrument moves treatment but has no direct path to the outcome and is not tied to hidden outcome shocks after controls.",
ha="center",
va="center",
fontsize=10,
color="#475569",
)
ax.set_title("Partially Linear IV Teaching Design", pad=18)
plt.tight_layout()
fig.savefig(FIGURE_DIR / f"{NOTEBOOK_PREFIX}_pliv_design_dag.png", dpi=160, bbox_inches="tight")
plt.show()