01: DML Theory, Orthogonalization, and Cross-Fitting
This lesson explains the theory that makes DoubleML useful. The package is easiest to trust when the mechanics are not mysterious: nuisance functions are estimated with machine learning, the target causal parameter is estimated through an orthogonal score, and cross-fitting keeps nuisance prediction honest.
The running example is a partially linear regression design:
\[
Y = \theta_0 D + g_0(X) + \varepsilon,
\]
where Y is the outcome, D is a treatment or exposure, X is a vector of controls, g_0(X) is an unknown outcome nuisance function, and theta_0 is the causal parameter we want. Treatment assignment is also modeled as
\[
D = m_0(X) + V.
\]
DoubleML estimates g_0(X) and m_0(X) flexibly, but it does not treat those prediction models as the final goal. The final goal is the low-dimensional causal parameter theta_0 and its uncertainty.
Estimated runtime: about 1 minute on a typical laptop.
Learning Goals
By the end, you should be able to:
explain why naive treatment-outcome regression can be biased under confounding;
explain why plugging machine-learning predictions into causal estimators can create regularization bias;
derive the partially linear orthogonal score at an intuitive level;
describe why Neyman orthogonality reduces sensitivity to nuisance-model mistakes;
implement manual cross-fitting for a PLR score;
distinguish DML1-style fold averaging from DML2-style pooled score solving;
connect the manual calculations to DoubleMLPLR.
Dataset and Experiment Setup
We use controlled semi-synthetic datasets with known nuisance functions or known treatment effects to study DML Theory, Orthogonalization, And Cross-Fitting. Double machine learning is easiest to understand when the data contain realistic nuisance structure but still give us a benchmark for the target parameter. That lets the lesson separate estimation error from identification failure.
Read each row as a unit with pre-treatment covariates, a treatment or instrument, and an outcome. The learner comparisons are experiments about orthogonalization, cross-fitting, overlap, sample splitting, and decision targets. The experiment shows why sample splitting matters. The same observations should not be used to both learn nuisance functions and evaluate orthogonal scores.
The estimators are causal only under the stated design assumptions. Flexible machine-learning nuisance models help with prediction bias, but they do not replace causal identification.
Mathematical Foundation
Double machine learning estimates a target parameter \(\theta_0\) through a score \(\psi(W;\theta,\eta)\), where \(\eta\) collects nuisance functions. The key requirement is Neyman orthogonality,
where \(\widehat\eta_{-k(i)}\) is trained on folds that exclude observation \(i\).
The lesson proceeds in seven steps:
set up the environment and output folders;
simulate a high-dimensional confounded PLR dataset with known truth;
compare naive and adjusted baselines;
introduce orthogonal residual scores;
demonstrate nuisance perturbation robustness;
implement sample splitting and cross-fitting manually;
compare manual DML1, manual DML2, and DoubleMLPLR.
Tutorial Workflow
Setup
The code below imports the packages used in the lesson, prepares output directories, and suppresses known non-substantive lesson warnings. We set MPLCONFIGDIR before importing plotting libraries so Matplotlib cache files stay inside the project outputs folder.
# Build and label the diagnostic visualization for the Setup section.from pathlib import Pathimport osimport warningsPROJECT_ROOT = Path.cwd().resolve()if PROJECT_ROOT.name =="doubleml": PROJECT_ROOT = PROJECT_ROOT.parents[2]OUTPUT_DIR = PROJECT_ROOT /"notebooks"/"tutorials"/"doubleml"/"outputs"DATASET_DIR = OUTPUT_DIR /"datasets"FIGURE_DIR = OUTPUT_DIR /"figures"TABLE_DIR = OUTPUT_DIR /"tables"MATPLOTLIB_CACHE_DIR = OUTPUT_DIR /"matplotlib_cache"for directory in [DATASET_DIR, FIGURE_DIR, TABLE_DIR, MATPLOTLIB_CACHE_DIR]: directory.mkdir(parents=True, exist_ok=True)os.environ.setdefault("MPLCONFIGDIR", str(MATPLOTLIB_CACHE_DIR))warnings.filterwarnings("ignore", category=FutureWarning)warnings.filterwarnings("ignore", message="IProgress not found.*")warnings.filterwarnings("ignore", message=".*does not have valid feature names.*")import numpy as npimport pandas as pdpd.set_option("display.max_colwidth", None)pd.set_option("display.max_columns", None)pd.set_option("display.width", 0)import matplotlib.pyplot as pltimport seaborn as snsfrom IPython.display import displayimport doubleml as dmlfrom sklearn.base import clonefrom sklearn.linear_model import LassoCV, LinearRegressionfrom sklearn.metrics import mean_squared_error, r2_scorefrom sklearn.model_selection import KFold, cross_val_predictfrom sklearn.neighbors import KNeighborsRegressorfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScalerNOTEBOOK_PREFIX ="01"RANDOM_SEED =42TRUE_THETA =1.0sns.set_theme(style="whitegrid", context="notebook")plt.rcParams.update({"figure.dpi": 120, "savefig.dpi": 160})print(f"Project root: {PROJECT_ROOT}")print(f"Output folder: {OUTPUT_DIR}")print(f"DoubleML version: {getattr(dml, '__version__', 'not exposed')}")
The setup confirms the environment and creates a stable place for saved outputs. We use LassoCV for the main nuisance learners because the synthetic design below is sparse and high-dimensional.
Version Table
Theory lessons still benefit from version logging. The exact learner behavior, defaults, and output formatting can change across package versions.
from importlib import metadatapackages = ["doubleml", "numpy", "pandas", "scikit-learn", "matplotlib", "seaborn"]version_table = []for package in packages:try: version = metadata.version(package)except metadata.PackageNotFoundError: version =None version_table.append({"package": package, "version": version})version_table = pd.DataFrame(version_table)version_table.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_package_versions.csv", index=False)display(version_table)
package
version
0
doubleml
0.11.2
1
numpy
2.4.4
2
pandas
3.0.2
3
scikit-learn
1.6.1
4
matplotlib
3.10.9
5
seaborn
0.13.2
This small table gives the lesson a reproducibility anchor. If a future run changes slightly, the package versions are one of the first things to check.
Theory Map
Before coding, we summarize the main theory concepts. Each row in the table will appear again in executable form later in the lesson.
concept
plain_language_role
where_it_appears_below
confounding
Controls affect both treatment and outcome, so naive treatment-outcome association is not causal.
naive baseline estimate
nuisance function
A helper prediction function such as E[Y | X] or E[D | X].
Lasso nuisance models
regularization bias
Bias caused when regularized nuisance prediction errors leak into the causal estimate.
in-sample and memorizing learner demos
orthogonal score
A score designed so small nuisance mistakes have reduced first-order impact on theta.
residualized PLR score
cross-fitting
Train nuisance functions on one fold and score held-out observations on another fold.
manual K-fold DML implementation
DML1 versus DML2
DML1 averages fold-specific estimates; DML2 solves one pooled score after cross-fitting.
manual fold table and pooled estimate
The common thread is separation. DoubleML separates causal target estimation from nuisance prediction, and cross-fitting separates nuisance training rows from score-evaluation rows.
The causal implication is indirect but important: these diagnostics tell us whether the modeling stage is stable enough to support the causal estimate.
Simulating a Confounded PLR Dataset
We use a synthetic dataset because it lets us know the true treatment effect. The controls X affect both treatment D and outcome Y, so a naive regression of Y on D will not recover the true effect.
The design is sparse and high-dimensional: there are many controls, but only the first few matter. That gives us a natural setting for regularized nuisance learners.
# Define reusable helpers for the Simulating A Confounded PLR Dataset section.def simulate_sparse_plr(n_samples=500, n_controls=80, theta=TRUE_THETA, seed=RANDOM_SEED):""" Create a sparse high-dimensional PLR dataset with known nuisance functions. Parameters ---------- n_samples : int Number of observations generated, sampled, or evaluated. n_controls : int Number of `controls` used by `simulate_sparse_plr`. theta : object Treatment-effect parameter used in the score or simulation benchmark. seed : int Random seed for reproducible simulation or resampling. Returns ------- tuple Tuple containing observed_df, oracle_df, x_cols. """ rng = np.random.default_rng(seed) x = rng.normal(size=(n_samples, n_controls)) beta_m = np.zeros(n_controls) beta_g = np.zeros(n_controls) beta_m[:8] = [0.80, 0.70, 0.50, 0.40, 0.30, 0.25, 0.20, 0.15] beta_g[:8] = [1.00, 0.80, 0.60, 0.50, 0.40, 0.30, 0.20, 0.20] m0 = x @ beta_m g0 = x @ beta_g d = m0 + rng.normal(scale=1.0, size=n_samples) y = theta * d + g0 + rng.normal(scale=1.0, size=n_samples) l0 = theta * m0 + g0 x_cols = [f"x{i +1}"for i inrange(n_controls)] observed_df = pd.DataFrame(x, columns=x_cols) observed_df.insert(0, "d", d) observed_df.insert(0, "y", y) oracle_df = pd.DataFrame({"m0_x": m0, "g0_x": g0, "l0_x": l0})return observed_df, oracle_df, x_colsplr_df, oracle_df, x_cols = simulate_sparse_plr()plr_df.to_csv(DATASET_DIR /f"{NOTEBOOK_PREFIX}_sparse_plr_observed_data.csv", index=False)oracle_df.to_csv(DATASET_DIR /f"{NOTEBOOK_PREFIX}_sparse_plr_oracle_nuisance.csv", index=False)display(plr_df.head())print(f"Observed shape: {plr_df.shape}")print(f"True theta: {TRUE_THETA:.2f}")
y
d
x1
x2
x3
x4
x5
x6
x7
x8
x9
x10
x11
x12
x13
x14
x15
x16
x17
x18
x19
x20
x21
x22
x23
x24
x25
x26
x27
x28
x29
x30
x31
x32
x33
x34
x35
x36
x37
x38
x39
x40
x41
x42
x43
x44
x45
x46
x47
x48
x49
x50
x51
x52
x53
x54
x55
x56
x57
x58
x59
x60
x61
x62
x63
x64
x65
x66
x67
x68
x69
x70
x71
x72
x73
x74
x75
x76
x77
x78
x79
x80
0
-2.981203
-1.565256
0.304717
-1.039984
0.750451
0.940565
-1.951035
-1.302180
0.127840
-0.316243
-0.016801
-0.853044
0.879398
0.777792
0.066031
1.127241
0.467509
-0.859292
0.368751
-0.958883
0.878450
-0.049926
-0.184862
-0.680930
1.222541
-0.154529
-0.428328
-0.352134
0.532309
0.365444
0.412733
0.430821
2.141648
-0.406415
-0.512243
-0.813773
0.615979
1.128972
-0.113947
-0.840156
-0.824481
0.650593
0.743254
0.543154
-0.665510
0.232161
0.116686
0.218689
0.871429
0.223596
0.678914
0.067579
0.289119
0.631288
-1.457156
-0.319671
-0.470373
-0.638878
-0.275142
1.494941
-0.865831
0.968278
-1.682870
-0.334885
0.162753
0.586222
0.711227
0.793347
-0.348725
-0.462352
0.857976
-0.191304
-1.275686
-1.133287
-0.919452
0.497161
0.142426
0.690485
-0.427253
0.158540
0.625590
-0.309347
1
-2.385550
-2.019338
0.456775
-0.661926
-0.363054
-0.381738
-1.195840
0.486972
-0.469402
0.012494
0.480747
0.446531
0.665385
-0.098485
-0.423298
-0.079718
-1.687334
-1.447112
-1.322700
-0.997247
0.399774
-0.905479
-0.378163
1.299228
-0.356264
0.737516
-0.933618
-0.205438
-0.950022
-0.339033
0.840308
-1.727320
0.434424
0.237736
-0.594150
-1.446058
0.072130
-0.529493
0.232676
0.021852
1.601779
-0.239356
-1.023497
0.179276
0.219997
1.359188
0.835111
0.356871
1.463303
-1.188763
-0.639752
-0.926576
-0.389810
-1.376686
0.635151
-0.222223
-1.470806
-1.015579
0.313514
0.838127
1.996731
2.913862
0.414409
-0.989538
-2.132046
0.267711
-0.812941
-0.415357
-0.612097
-0.140791
1.065980
0.157049
-0.158635
-1.035654
-1.674683
-0.486308
-0.053783
1.767930
0.130275
0.982740
-0.499296
-1.184944
2
-0.904904
0.058417
-0.965117
-0.725226
2.128470
-0.821387
0.838489
-0.902927
0.931573
0.384951
-0.156638
-0.040763
-0.654788
0.446072
-0.454983
-1.225606
-1.277938
0.172588
1.579091
0.159992
-0.118638
0.285826
1.306002
0.219383
-0.410927
1.106289
0.428756
1.535756
0.183234
-1.224469
-1.368159
1.650928
1.723666
-0.179519
-0.383187
1.461444
-1.107046
-0.894727
0.643327
-0.394605
-0.005122
-0.163443
0.337575
1.407482
0.090585
0.643939
-2.050172
-0.048718
-0.843230
-1.218813
-0.878152
-0.334123
0.915903
-1.326393
0.030631
-0.484169
-0.327673
1.002758
0.538115
1.337398
-0.154506
-0.695943
-0.223859
0.242497
0.176573
-1.084388
0.090490
0.228228
2.517474
1.876845
-0.853243
-0.287383
-1.463442
-0.590707
0.315605
1.205854
-0.729084
-0.654146
-2.147289
-0.162666
-1.062414
-0.529439
3
-5.046823
-1.706713
-0.876861
-0.094263
-1.757728
-1.467045
2.129247
-1.287423
-1.096786
1.836914
2.905067
-1.171567
-0.368249
0.341556
1.728698
-0.986857
-0.245278
0.777338
0.434766
-0.376156
-0.133823
-1.374896
-0.238174
-0.266387
0.232170
-0.555327
0.471539
1.012716
0.155429
0.351756
0.053155
0.000084
-0.721558
0.316494
-0.097287
2.093168
1.573355
0.385847
-0.763057
-1.112411
1.191143
0.262749
0.480143
-1.744586
0.927438
0.454420
-1.110431
-0.471525
0.263717
0.052467
-0.292171
-0.103488
-0.251977
0.152563
1.471492
-2.566658
-0.236850
0.176512
0.295994
-0.371915
-1.756722
0.327995
1.727350
-1.533861
0.863828
-0.328525
-0.061324
-1.052899
-0.334456
1.300045
0.582655
1.732312
1.177412
0.439087
1.743935
0.438993
0.827988
-0.296571
0.066546
-0.697424
0.989584
-1.178304
4
1.938564
-0.441727
0.782350
-0.190651
1.171247
0.750869
1.820646
0.730775
-1.572040
-0.066953
-1.172007
-0.518280
1.511228
0.637534
-0.698930
-1.013717
0.032782
-1.216560
-0.671140
0.312009
1.155312
0.608761
-2.291290
0.304367
0.072034
0.413890
1.616210
-2.063238
-0.591103
0.590906
-1.581594
1.475949
0.368357
0.846584
-0.570944
0.813764
1.068472
0.232878
0.234401
0.270343
-0.863345
-0.147529
-0.152523
0.383394
0.999824
-1.058536
-0.125009
1.481456
-0.743588
-0.822250
0.202306
0.844385
0.011426
1.328961
0.856794
0.841820
0.554117
2.327653
-0.205162
-2.003522
1.604254
-0.457699
0.107880
1.309551
-1.602260
-1.251647
-1.601278
-0.794136
0.439637
0.524188
0.276274
-1.412766
-2.310103
0.054354
-0.471776
0.459386
0.701954
0.138241
0.760133
0.229211
0.530065
-0.704673
Observed shape: (500, 82)
True theta: 1.00
The observed data has the columns an analyst would see: outcome, treatment, and controls. The oracle nuisance columns are saved separately only for learning; real datasets do not include true nuisance functions.
The next step documents the variable roles. This matters because DoubleML uses column roles to define the score. A role mistake is not a small syntax issue; it changes the estimand.
Pre-treatment controls used for nuisance adjustment.
3
m0_x, g0_x, l0_x
oracle teaching columns
3
True nuisance values saved separately for theory checks only.
Only y, d, and the x columns will be passed to DoubleML. The oracle columns are useful for the theory demonstrations but would be unavailable in an applied analysis.
Why Naive Regression Fails
The simplest mistake is to regress outcome on treatment while ignoring controls. Because the controls affect both treatment and outcome, the treatment coefficient absorbs part of the control effect.
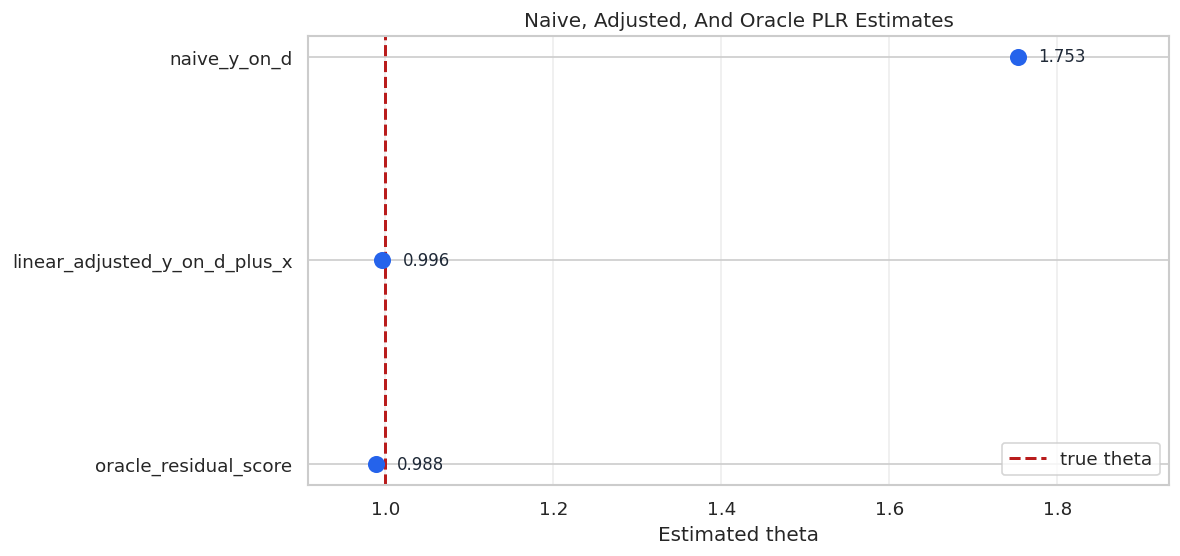
We compare three estimates:
naive regression of y on d only;
full linear regression of y on d and all controls;
oracle residual score using the true nuisance functions, available only because this is synthetic data.
# Define reusable helpers for the Why Naive Regression Fails section.def residual_score_theta(y, d, l_hat, m_hat):""" Solve the PLR partialling-out score using supplied nuisance predictions. Parameters ---------- y : str or array-like Second variable, outcome, or numeric input in the local calculation. d : object Treatment indicator used in the orthogonal score or simulation. l_hat : array-like Estimated outcome nuisance prediction. m_hat : array-like Estimated treatment or propensity nuisance prediction. Returns ------- np.ndarray Residual vector aligned with the original observations. """ y_resid = y - l_hat d_resid = d - m_hat denominator = np.mean(d_resid * d_resid)if denominator <1e-12:return np.nanreturn np.mean(d_resid * y_resid) / denominatornaive_model = LinearRegression().fit(plr_df[["d"]], plr_df["y"])linear_adjusted_model = LinearRegression().fit(plr_df[["d"] + x_cols], plr_df["y"])oracle_theta = residual_score_theta( y=plr_df["y"].to_numpy(), d=plr_df["d"].to_numpy(), l_hat=oracle_df["l0_x"].to_numpy(), m_hat=oracle_df["m0_x"].to_numpy(),)baseline_estimates = pd.DataFrame( [ {"method": "naive_y_on_d", "estimate": float(naive_model.coef_[0])}, {"method": "linear_adjusted_y_on_d_plus_x", "estimate": float(linear_adjusted_model.coef_[0])}, {"method": "oracle_residual_score", "estimate": float(oracle_theta)}, ])baseline_estimates["true_theta"] = TRUE_THETAbaseline_estimates["error"] = baseline_estimates["estimate"] - TRUE_THETAbaseline_estimates.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_baseline_estimates.csv", index=False)display(baseline_estimates.round(4))
method
estimate
true_theta
error
0
naive_y_on_d
1.7526
1.0
0.7526
1
linear_adjusted_y_on_d_plus_x
0.9960
1.0
-0.0040
2
oracle_residual_score
0.9884
1.0
-0.0116
The naive estimate is far from the true effect because it ignores confounding. The oracle residual score is close because it removes the true control-driven parts of outcome and treatment before estimating the treatment effect.
This plot shows the same comparison visually. The vertical dashed line is the true effect, available only in this controlled worked example.
The visual makes the confounding problem concrete. DoubleML is designed for the middle ground where the oracle functions are unknown, but flexible learners can estimate useful nuisance functions from controls.
Diagnostics and Interpretation
The Orthogonal PLR Score
The partialling-out score for PLR can be written as:
The key is more than residualization. The key is that the score is orthogonal: near the truth, small errors in l or m have reduced first-order impact on theta.
The next table turns the score into a set of operational pieces. These are the pieces that DoubleML automates internally.
piece
role
why_it_matters
Y - l_hat(X)
outcome residual
Removes the part of the outcome explained by controls.
D - m_hat(X)
treatment residual
Removes the part of treatment assignment explained by controls.
mean(treatment_residual * outcome_residual)
score numerator
Measures remaining treatment-outcome movement after residualization.
mean(treatment_residual ** 2)
score denominator
Measures remaining treatment variation after adjustment.
numerator / denominator
theta estimate
Solves the sample analog of the orthogonal moment condition.
This table is the simplest mental model for PLR DML: estimate nuisance functions, residualize outcome and treatment, then regress the residualized outcome on the residualized treatment.
Orthogonality by Perturbation
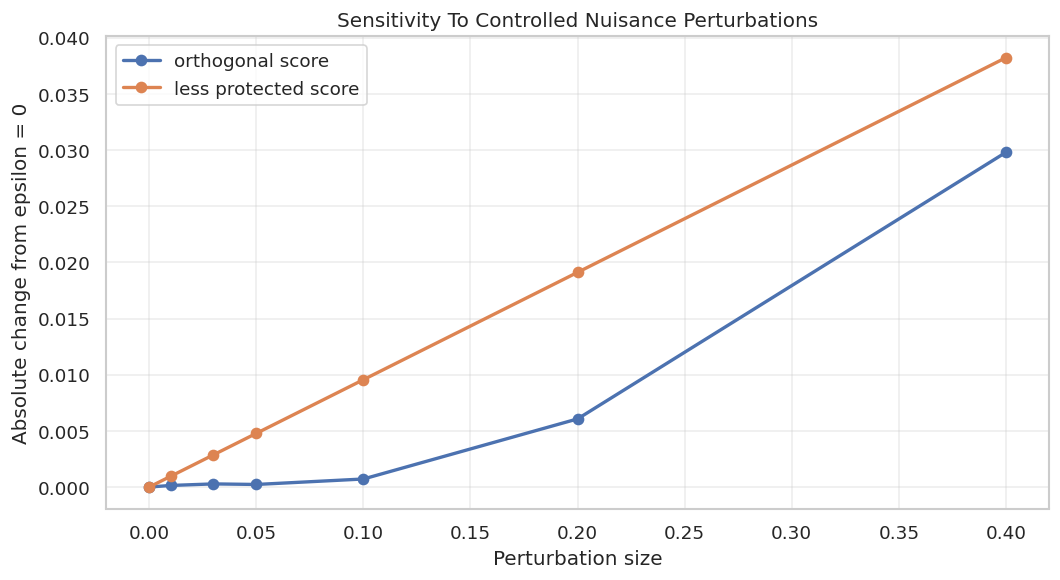
Orthogonality can feel abstract, so we demonstrate it numerically. We start from the true nuisance functions and add controlled perturbations. Then we compare:
the orthogonal residual score, which residualizes both outcome and treatment;
a non-orthogonal residual score, which residualizes the outcome but does not residualize the treatment.
The orthogonal score should move more slowly as the nuisance perturbation grows.
# Define reusable helpers for the Orthogonality By Perturbation section.x_matrix = plr_df[x_cols].to_numpy()y_array = plr_df["y"].to_numpy()d_array = plr_df["d"].to_numpy()l0_array = oracle_df["l0_x"].to_numpy()m0_array = oracle_df["m0_x"].to_numpy()perturb_l =0.60* x_matrix[:, 0] -0.30* x_matrix[:, 3] +0.20* x_matrix[:, 9]perturb_m =-0.40* x_matrix[:, 1] +0.25* x_matrix[:, 2] -0.15* x_matrix[:, 10]def non_orthogonal_theta(y, d, l_hat):""" A deliberately less protected score: outcome residualized, treatment not residualized. Parameters ---------- y : str or array-like Second variable, outcome, or numeric input in the local calculation. d : object Treatment indicator used in the orthogonal score or simulation. l_hat : array-like Estimated outcome nuisance prediction. Returns ------- float Treatment-effect estimate from the nonorthogonal score used for comparison with the DML score. """ y_resid = y - l_hatreturn np.mean(d * y_resid) / np.mean(d * d)perturbation_rows = []base_non_orthogonal = non_orthogonal_theta(y_array, d_array, l0_array)base_orthogonal = residual_score_theta(y_array, d_array, l0_array, m0_array)for epsilon in [0.00, 0.01, 0.03, 0.05, 0.10, 0.20, 0.40]: l_perturbed = l0_array + epsilon * perturb_l m_perturbed = m0_array + epsilon * perturb_m orthogonal_estimate = residual_score_theta(y_array, d_array, l_perturbed, m_perturbed) non_orthogonal_estimate = non_orthogonal_theta(y_array, d_array, l_perturbed) perturbation_rows.append( {"epsilon": epsilon,"orthogonal_estimate": orthogonal_estimate,"orthogonal_change_from_epsilon_0": orthogonal_estimate - base_orthogonal,"non_orthogonal_estimate": non_orthogonal_estimate,"non_orthogonal_change_from_epsilon_0": non_orthogonal_estimate - base_non_orthogonal, } )perturbation_table = pd.DataFrame(perturbation_rows)perturbation_table.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_orthogonality_perturbation_table.csv", index=False)display(perturbation_table.round(5))
epsilon
orthogonal_estimate
orthogonal_change_from_epsilon_0
non_orthogonal_estimate
non_orthogonal_change_from_epsilon_0
0
0.00
0.98837
0.00000
0.41262
0.00000
1
0.01
0.98851
0.00014
0.41167
-0.00096
2
0.03
0.98865
0.00028
0.40976
-0.00287
3
0.05
0.98860
0.00023
0.40784
-0.00478
4
0.10
0.98766
-0.00072
0.40307
-0.00955
5
0.20
0.98231
-0.00606
0.39351
-0.01911
6
0.40
0.95858
-0.02980
0.37440
-0.03822
The orthogonal estimate changes more slowly near zero perturbation. The point is not that nuisance errors do not matter. They do. The point is that the score is designed to reduce first-order sensitivity around the correct nuisance functions.
The next plot shows the perturbation result. A flatter curve near zero is the numerical fingerprint of the orthogonal score.
The less protected score reacts more sharply to the same nuisance perturbation. This is why orthogonal scores are central to DoubleML.
The causal implication is indirect but important: these diagnostics tell us whether the modeling stage is stable enough to support the causal estimate.
Regularization Bias and Memorizing Learners
Orthogonality helps with nuisance errors, but it does not license careless prediction. If a nuisance learner memorizes the training data and we evaluate it on the same rows, residuals can become artificially tiny. That can make the residual score unstable or meaningless.
The code below compares in-sample and cross-fitted residualization using a deliberately memorizing 1-nearest-neighbor learner.
The in-sample 1-nearest-neighbor learner nearly memorizes the outcome and treatment, leaving almost no residual treatment variation. Cross-fitting prevents the exact same row from being used for its own nuisance prediction, so the residual score becomes defined again, although the learner is still not a great choice here.
Cross-Fitting with a Sensible Sparse Learner
Now we use LassoCV, which matches the sparse linear structure of the synthetic data. We compute nuisance predictions both in-sample and out-of-fold so the difference is explicit.
# Fit or evaluate the model objects used in the Cross-Fitting With A Sensible Sparse Learner section.lasso_learner = make_pipeline( StandardScaler(), LassoCV(cv=5, random_state=RANDOM_SEED, n_jobs=-1, max_iter=20_000),)in_sample_l_lasso = clone(lasso_learner).fit(plr_df[x_cols], plr_df["y"]).predict(plr_df[x_cols])in_sample_m_lasso = clone(lasso_learner).fit(plr_df[x_cols], plr_df["d"]).predict(plr_df[x_cols])cf_l_lasso = cross_val_predict(clone(lasso_learner), plr_df[x_cols], plr_df["y"], cv=kf, n_jobs=-1)cf_m_lasso = cross_val_predict(clone(lasso_learner), plr_df[x_cols], plr_df["d"], cv=kf, n_jobs=-1)lasso_residual_table = pd.DataFrame( [ {"approach": "in_sample_lasso_residualization","theta_estimate": residual_score_theta(y_array, d_array, in_sample_l_lasso, in_sample_m_lasso),"ml_l_r2": r2_score(y_array, in_sample_l_lasso),"ml_m_r2": r2_score(d_array, in_sample_m_lasso), }, {"approach": "cross_fitted_lasso_residualization","theta_estimate": residual_score_theta(y_array, d_array, cf_l_lasso, cf_m_lasso),"ml_l_r2": r2_score(y_array, cf_l_lasso),"ml_m_r2": r2_score(d_array, cf_m_lasso), }, ])lasso_residual_table["true_theta"] = TRUE_THETAlasso_residual_table["absolute_error"] = (lasso_residual_table["theta_estimate"] - TRUE_THETA).abs()lasso_residual_table.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_lasso_residualization_table.csv", index=False)display(lasso_residual_table.round(4))
approach
theta_estimate
ml_l_r2
ml_m_r2
true_theta
absolute_error
0
in_sample_lasso_residualization
1.0084
0.8111
0.6249
1.0
0.0084
1
cross_fitted_lasso_residualization
0.9861
0.7888
0.5743
1.0
0.0139
The cross-fitted estimate is based on out-of-fold predictions. Its nuisance R^2 values are lower than the in-sample values because held-out prediction is harder, but that honesty is exactly the point.
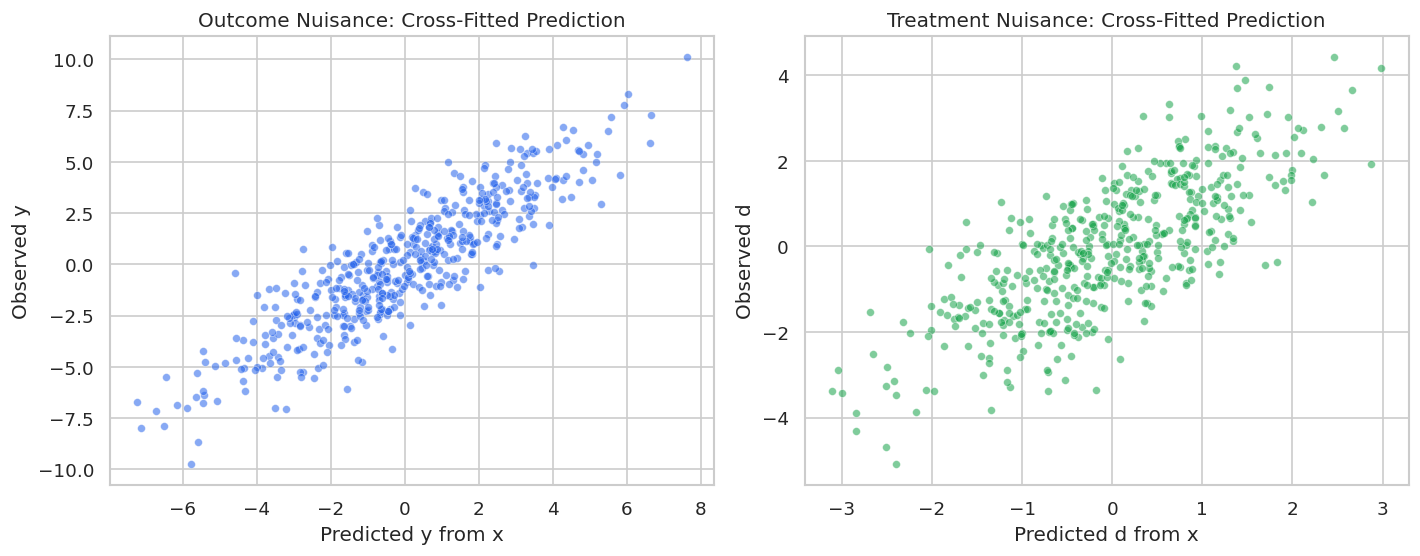
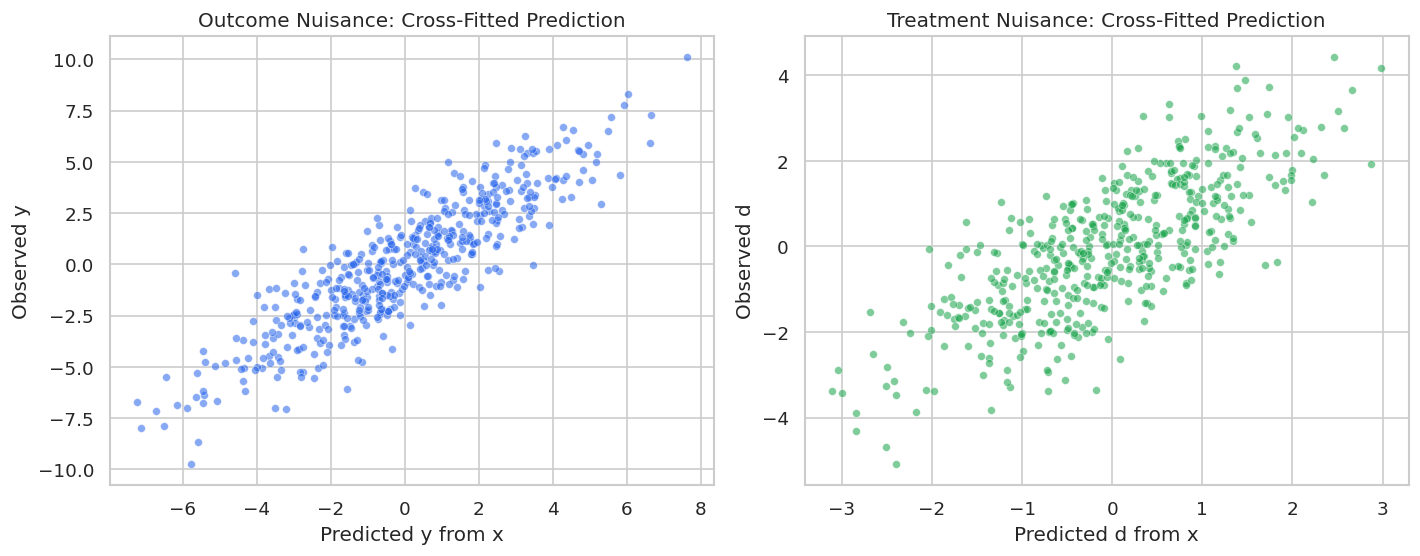
The next figure shows observed versus cross-fitted nuisance predictions. We are not trying to maximize predictive performance at all costs; we are checking that the nuisance learners capture meaningful control-driven signal.
fig, axes = plt.subplots(1, 2, figsize=(12, 4.8))sns.scatterplot(x=cf_l_lasso, y=y_array, s=22, alpha=0.55, color="#2563eb", ax=axes[0])axes[0].set_title("Outcome Nuisance: Cross-Fitted Prediction")axes[0].set_xlabel("Predicted y from x")axes[0].set_ylabel("Observed y")sns.scatterplot(x=cf_m_lasso, y=d_array, s=22, alpha=0.55, color="#16a34a", ax=axes[1])axes[1].set_title("Treatment Nuisance: Cross-Fitted Prediction")axes[1].set_xlabel("Predicted d from x")axes[1].set_ylabel("Observed d")plt.tight_layout()fig.savefig(FIGURE_DIR /f"{NOTEBOOK_PREFIX}_cross_fitted_lasso_nuisance_predictions.png", dpi=160, bbox_inches="tight")plt.show()
Both nuisance predictions contain signal. The treatment nuisance is particularly important because residual treatment variation is what identifies the partially linear effect after adjustment.
Sample Splitting Mechanics
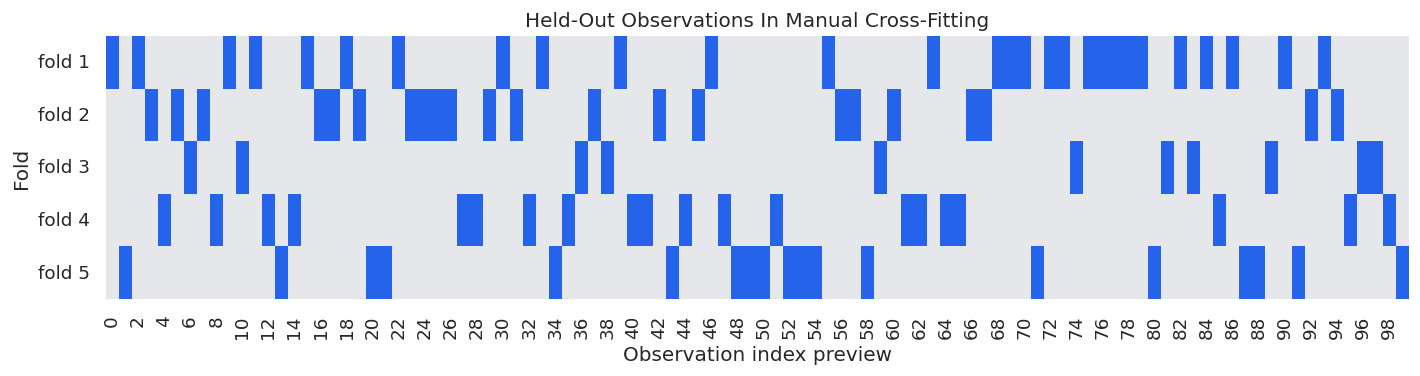
Cross-fitting uses repeated train and held-out roles. The code below records the fold sizes used in the manual calculations above. Every observation appears in exactly one held-out fold for this single split.
The fold table is simple but important. Reporting folds and random seeds helps make DML analyses reproducible.
The causal implication is indirect but important: these diagnostics tell us whether the modeling stage is stable enough to support the causal estimate.
This heatmap shows the held-out assignment for the first 100 rows. Each row is a fold; dark cells mark observations scored in that fold.
The dark cells move across folds so each observation gets one held-out nuisance prediction. That held-out prediction is what enters the orthogonal score.
The causal implication is indirect but important: these diagnostics tell us whether the modeling stage is stable enough to support the causal estimate.
DML1 versus DML2
DML1 and DML2 use the same basic score but aggregate folds differently.
DML1: solve the score separately in each fold, then average the fold-specific estimates.
DML2: stack all cross-fitted residuals and solve one pooled score.
Many modern DoubleML workflows report a DML2-style pooled estimate. We compute both manually here because the distinction helps clarify what cross-fitting is doing.
The fold estimates vary because each held-out fold has its own residual distribution. DML1 averages those fold estimates; DML2 solves one pooled score across all held-out predictions.
The next plot shows fold-level variation and compares it with the pooled DML2 estimate and the true synthetic effect.
Fold variability is a useful reminder that sample splitting adds randomness. Later lessons revisit repeated cross-fitting and split sensitivity more carefully.
The causal implication is indirect but important: these diagnostics tell us whether the modeling stage is stable enough to support the causal estimate.
Connecting Manual DML to DoubleMLPLR
Now we fit DoubleMLPLR using the same observed dataset and a Lasso nuisance learner. The package handles sample splitting, nuisance fitting, score solving, standard errors, and confidence intervals.
The printed object summarizes the data roles, score, learners, and resampling plan. This is the package-level version of the manual workflow above.
The causal implication is indirect but important: these diagnostics tell us whether the modeling stage is stable enough to support the causal estimate.
The code below extracts the DoubleML summary and compares it with the manual DML calculations.
The DoubleML estimate is close to the manual cross-fitted residual estimate because both are solving the same PLR score idea. DoubleML additionally reports standard errors, p-values, and confidence intervals.
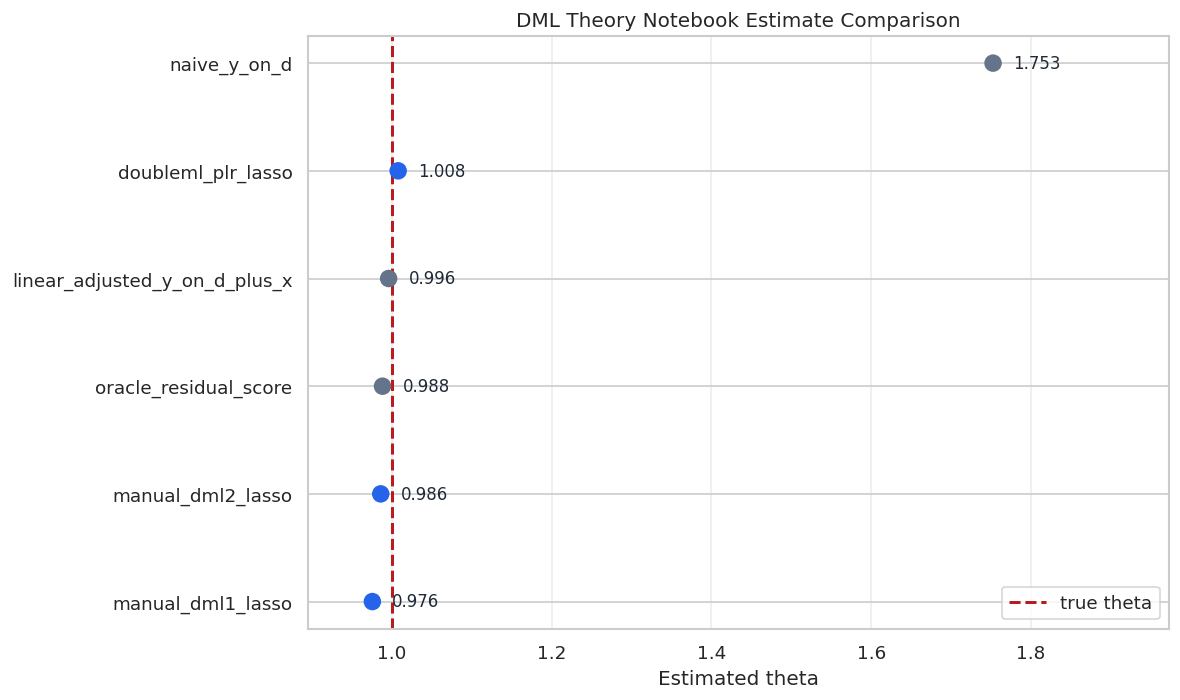
We collect all major estimates in one comparison table. This is a useful reporting habit because it separates confounding bias, adjustment behavior, and DML behavior.
The table shows the main lesson of the lesson: the naive estimate is not a causal estimate in this design, while the residualized and cross-fitted estimates aim at the true treatment effect.
The comparison plot places all estimates against the true synthetic effect. This type of plot is helpful in simulations because it shows which procedures are targeting the right quantity.
The cross-fitted DML estimates cluster near the true value. The naive estimate remains far away because it does not address the confounding built into the simulation.
Inspecting Score Elements
DoubleML stores score-related arrays after fitting. These are advanced internal outputs, but seeing their shapes helps connect the package object to the theory. For one treatment and one repeated split, the score arrays have an observation dimension plus treatment and repetition dimensions.
score_diagnostics = pd.DataFrame( [ {"object": "psi", "shape": str(np.asarray(plr_model.psi).shape), "description": "Score values evaluated at the fitted theta."}, {"object": "psi_deriv", "shape": str(np.asarray(plr_model.psi_deriv).shape), "description": "Score derivative values used for standard errors."}, ])score_diagnostics.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_score_diagnostics.csv", index=False)display(score_diagnostics)
object
shape
description
0
psi
(500, 1, 1)
Score values evaluated at the fitted theta.
1
psi_deriv
(500, 1, 1)
Score derivative values used for standard errors.
Most users can ignore these arrays during routine work. They are still a useful bridge between the mathematical score and the fitted DoubleML object.
Nuisance Losses and Prediction Quality
The final theory point is that nuisance quality matters, even with orthogonal scores. Orthogonality reduces first-order sensitivity, but very poor nuisance models can still hurt finite-sample performance.
DoubleML reports nuisance losses. We also compute simple out-of-fold prediction quality from the stored nuisance predictions.
mean squared error for regression nuisance learner
1
ml_m
1.046
mean squared error for regression nuisance learner
The loss table gives a quick check of nuisance fit. These losses should be read as diagnostics that describe nuisance-model behavior.
The causal implication is indirect but important: these diagnostics tell us whether the modeling stage is stable enough to support the causal estimate.
The code below reads DoubleML’s stored nuisance predictions and computes simple RMSE and R2 diagnostics for each nuisance role.
doubleml_pred_l = np.asarray(plr_model.predictions["ml_l"]).squeeze()doubleml_pred_m = np.asarray(plr_model.predictions["ml_m"]).squeeze()prediction_quality = pd.DataFrame( [ {"nuisance_role": "ml_l predicts y from x","rmse": mean_squared_error(y_array, doubleml_pred_l) **0.5,"r2": r2_score(y_array, doubleml_pred_l), }, {"nuisance_role": "ml_m predicts d from x","rmse": mean_squared_error(d_array, doubleml_pred_m) **0.5,"r2": r2_score(d_array, doubleml_pred_m), }, ])prediction_quality.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_doubleml_nuisance_prediction_quality.csv", index=False)display(prediction_quality.round(4))
nuisance_role
rmse
r2
0
ml_l predicts y from x
1.451
0.7840
1
ml_m predicts d from x
1.046
0.5686
The nuisance learners capture meaningful signal from the controls. We want useful residualization for the target causal score, even when prediction is imperfect.
Reporting and Takeaways
Reporting Checklist for DML Theory
A theory lesson still needs a reporting checklist. These are the items that should appear whenever you use DoubleML in a real analysis.
check
status_here
why_it_matters
Target parameter named
theta in a PLR design
The estimand must be clear before choosing learners.
Identification assumptions stated
controls are sufficient by construction in synthetic data
DoubleML does not create identification by itself.
Nuisance roles documented
ml_l for outcome nuisance and ml_m for treatment nuisance
Different DoubleML classes require different nuisance roles.
Cross-fitting plan documented
5-fold split with fixed random seed
Resampling choices can affect finite-sample estimates.
Baselines compared
naive, linear adjusted, oracle, manual DML, DoubleML
Baselines reveal what the DML workflow is correcting.
Nuisance diagnostics reported
losses and out-of-fold prediction quality saved
Poor nuisance fit can still matter.
Uncertainty reported
DoubleML standard errors and confidence interval saved
A causal estimate without uncertainty is incomplete.
The checklist separates theory, implementation, and reporting. That separation is the habit that makes DoubleML work credible.
For the broader lesson, the estimate should be interpreted together with the identifying assumptions and diagnostics that make it credible.
Closing Notes
The core theory has three moving parts:
residualize outcome and treatment using nuisance functions;
use an orthogonal score so small nuisance errors have reduced first-order impact;
use cross-fitting so nuisance predictions are evaluated out of sample.
The sequence next moves from theory to data setup through DoubleMLData, variable roles, and design-specific data containers.