We start the DoubleML tutorial series. It is more theoretical than a quick API demo because DoubleML is more than another prediction package. It is a framework for causal effect estimation when the identifying assumptions are supplied by the analyst and flexible machine-learning models are used for nuisance adjustment.
The key idea is double / debiased machine learning. We want to estimate a causal parameter such as an average treatment effect or a partially linear treatment effect. At the same time, we may need high-dimensional or nonlinear models for nuisance functions such as outcome regression, treatment regression, propensity scores, or instrument first stages. Naively plugging flexible machine-learning predictions into a causal estimator can create regularization bias. DoubleML reduces that problem by using Neyman-orthogonal score functions and cross-fitting.
In plain language:
the causal design says what effect is identifiable;
the nuisance learners estimate the adjustment functions needed by that design;
orthogonal scores make the final estimate less sensitive to small nuisance-model errors;
cross-fitting keeps each observation’s nuisance prediction out of the model that was trained on that observation;
inference then attaches standard errors, confidence intervals, and hypothesis tests to the effect estimate.
Estimated runtime: less than 1 minute on a typical laptop.
Orientation and Learning Goals
By the end, you should be able to:
explain the difference between causal identification and machine-learning nuisance estimation;
describe why DoubleML uses orthogonal scores and cross-fitting;
recognize the main DoubleML data containers and model classes;
build a small DoubleMLData object;
fit a minimal DoubleMLPLR model and read its output;
understand the role of the later lessons in this tutorial series.
Dataset and Experiment Setup
This opening lesson is an orientation to DoubleML, so the examples are deliberately compact. They expose workflow mechanics and assumptions before richer applied analyses. They show how the package represents data, models, graphs, estimands, estimators, diagnostics, and saved outputs before the later lessons use richer designs.
When a small dataset appears here, read it as a smoke test for the workflow and a way to locate where assumptions enter. The important experiment is procedural: can the environment run, can the objects be created, and can the reader see where assumptions will enter in later lessons?
Mathematical Foundation
Double machine learning estimates a target parameter \(\theta_0\) through a score \(\psi(W;\theta,\eta)\), where \(\eta\) collects nuisance functions. The key requirement is Neyman orthogonality,
where \(\widehat\eta_{-k(i)}\) is trained on folds that exclude observation \(i\).
DoubleML Orientation and Setup
Where DoubleML Fits
DoubleML belongs in the causal effect-estimation part of the workflow. It does not discover a causal graph for you. It also does not make unconfoundedness, instrument validity, parallel trends, or selection assumptions true. Those assumptions come from the study design.
A useful way to place it is:
Formulate a causal question.
Choose an identification strategy: unconfoundedness, IV, DID, RDD, sample selection, or another design.
Define the estimand: ATE, ATT, LATE, PLR coefficient, GATE, QTE, and so on.
Use DoubleML to estimate the identified parameter with flexible nuisance models and valid uncertainty quantification.
Stress-test the result with diagnostics, sensitivity checks, and design-specific caveats.
This first lesson focuses on steps 3 and 4 at a high level. The later lessons go deeper model by model.
Setup
The code below imports the scientific Python stack, prepares output folders, configures Matplotlib to write cache files inside the repository, and imports DoubleML. Keeping the setup explicit makes the lesson easier to rerun from different working directories.
# Build and label the diagnostic visualization for the Setup section.from pathlib import Pathimport inspectimport osimport warningsPROJECT_ROOT = Path.cwd().resolve()if PROJECT_ROOT.name =="doubleml": PROJECT_ROOT = PROJECT_ROOT.parents[2]OUTPUT_DIR = PROJECT_ROOT /"notebooks"/"tutorials"/"doubleml"/"outputs"DATASET_DIR = OUTPUT_DIR /"datasets"FIGURE_DIR = OUTPUT_DIR /"figures"TABLE_DIR = OUTPUT_DIR /"tables"MATPLOTLIB_CACHE_DIR = OUTPUT_DIR /"matplotlib_cache"for directory in [DATASET_DIR, FIGURE_DIR, TABLE_DIR, MATPLOTLIB_CACHE_DIR]: directory.mkdir(parents=True, exist_ok=True)os.environ.setdefault("MPLCONFIGDIR", str(MATPLOTLIB_CACHE_DIR))warnings.filterwarnings("ignore", category=FutureWarning)warnings.filterwarnings("ignore", message=".*does not have valid feature names.*")warnings.filterwarnings("ignore", message="IProgress not found.*")import numpy as npimport pandas as pdpd.set_option("display.max_colwidth", None)pd.set_option("display.max_columns", None)pd.set_option("display.width", 0)import matplotlib.pyplot as pltimport seaborn as snsfrom matplotlib.patches import FancyArrowPatch, FancyBboxPatchfrom IPython.display import displayimport doubleml as dmlimport doubleml.datasets as dml_datasetsfrom sklearn.base import clonefrom sklearn.ensemble import RandomForestRegressorfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_squared_error, r2_scorefrom sklearn.model_selection import KFoldfrom sklearn.preprocessing import StandardScalerNOTEBOOK_PREFIX ="00"RANDOM_SEED =42sns.set_theme(style="whitegrid", context="notebook")plt.rcParams.update({"figure.dpi": 120, "savefig.dpi": 160})print(f"Project root: {PROJECT_ROOT}")print(f"Output folder: {OUTPUT_DIR}")print(f"DoubleML version: {getattr(dml, '__version__', 'not exposed')}")
The environment is now ready. The lesson saves every generated table and figure with the 00_ prefix so outputs from different tutorial lessons do not collide.
Package Versions
Version logging is boring until it saves you. DoubleML analysis depends on the DoubleML package, the learners passed into it, and the numerical stack underneath. The code below records the package versions used in the run.
from importlib import metadatapackages = ["doubleml","numpy","pandas","scipy","scikit-learn","matplotlib","seaborn","statsmodels","lightgbm","xgboost",]version_rows = []for package in packages:try: version = metadata.version(package) status ="installed"except metadata.PackageNotFoundError: version =None status ="missing" version_rows.append({"package": package, "status": status, "version": version})version_table = pd.DataFrame(version_rows)version_table.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_package_versions.csv", index=False)display(version_table)
package
status
version
0
doubleml
installed
0.11.2
1
numpy
installed
2.4.4
2
pandas
installed
3.0.2
3
scipy
installed
1.17.1
4
scikit-learn
installed
1.6.1
5
matplotlib
installed
3.10.9
6
seaborn
installed
0.13.2
7
statsmodels
installed
0.14.6
8
lightgbm
installed
4.6.0
9
xgboost
installed
3.2.0
The important dependency is doubleml. Tree learners such as LightGBM and XGBoost are useful later, but the first executable example below uses scikit-learn random forests so it stays simple and reproducible.
What Problem DoubleML Solves
Suppose we observe outcome Y, treatment D, and controls X. A common causal target is the effect of D on Y after adjusting for X. If X is high-dimensional or the adjustment functions are nonlinear, we may want machine learning to estimate those adjustment functions.
The problem is that machine-learning predictions are regularized, tuned, and estimated from data. If we plug them into a causal estimator too directly, the final causal estimate can inherit first-order bias from nuisance-model errors.
DoubleML solves this by combining two ideas:
Neyman orthogonality: construct a score where small first-stage nuisance errors have only second-order impact on the target parameter.
Cross-fitting: estimate nuisance functions on one fold and evaluate their predictions on held-out observations, so the final score uses out-of-sample nuisance predictions.
For the partially linear regression model, a simplified structural form is:
\[
Y = \theta_0 D + g_0(X) + \varepsilon, \quad E[\varepsilon \mid X, D] = 0
\]
and the treatment equation is:
\[
D = m_0(X) + V, \quad E[V \mid X] = 0.
\]
Here g_0(X) and m_0(X) are nuisance functions. The causal parameter of interest is theta_0, not the prediction model itself.
The next table turns the notation into a reusable glossary. This is worth doing early because DoubleML object names (ml_l, ml_m, ml_g, ml_r) are compact and can feel cryptic before the roles are clear.
term
symbol_or_name
meaning
example_in_plr
target parameter
theta
The causal effect or causal estimand we want to estimate.
Effect of treatment d on outcome y after adjusting for x.
outcome nuisance function
l(X) or g(X)
A prediction function for the outcome component explained by controls.
Predict y from x.
treatment nuisance function
m(X)
A prediction function for treatment assignment or treatment intensity explained by controls.
Predict d from x.
orthogonal score
psi(W; theta, eta)
A moment equation designed to be insensitive to small nuisance errors around the truth.
Use residualized outcome and residualized treatment.
cross-fitting
K-fold nuisance prediction
Fit nuisance learners on training folds and predict nuisance values on held-out folds.
Each row gets out-of-fold predictions for y and d.
nuisance learner
ml_l, ml_m, ml_g, ml_r
A machine-learning model used to estimate a nuisance function, not the final causal target directly.
Random forest, Lasso, boosting, or another sklearn-style estimator.
The glossary makes one conceptual boundary clear: nuisance models are helpers. They may be sophisticated predictors, but the final object of interest is still the causal parameter and its uncertainty.
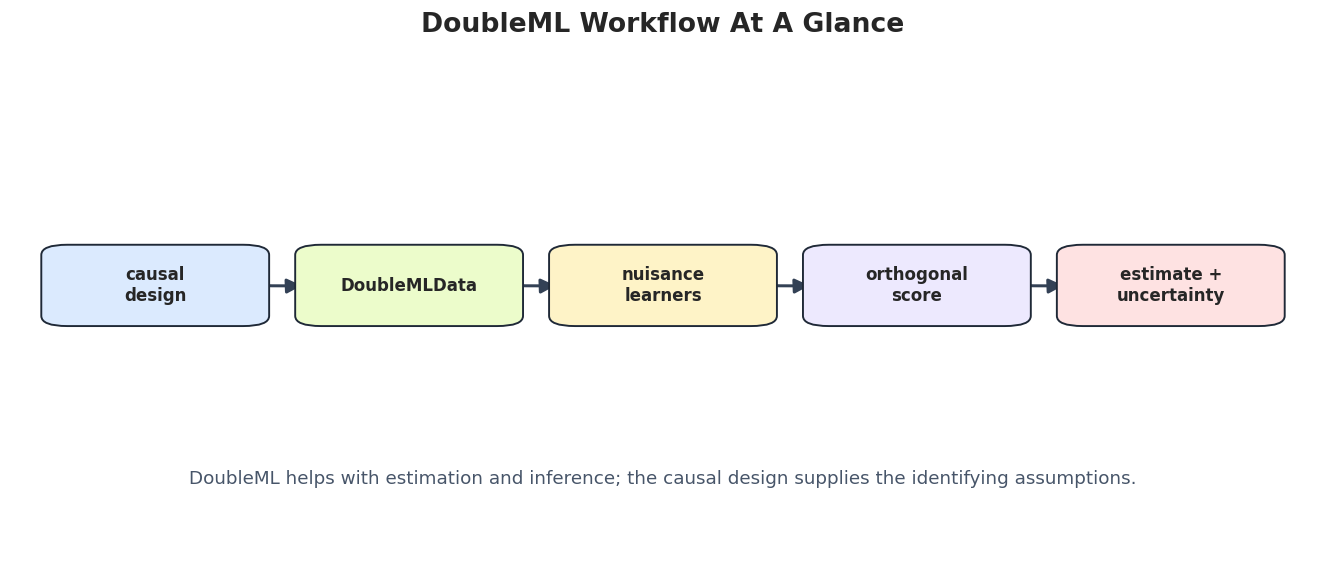
Visual Workflow
This figure summarizes the DoubleML workflow. We start with a causal design and a structured dataset, pass learner objects into a model class, let DoubleML create cross-fitted nuisance predictions, solve the orthogonal score, and then report estimates with uncertainty and caveats.
# Define reusable helpers for the Visual Workflow section.def draw_workflow_box(ax, center, label, color):""" Idea: Draw a labeled workflow step in a teaching flowchart. Parameters ---------- ax : matplotlib.axes.Axes Axes object that receives the drawing commands. center : object Center coordinate used to position a plotted box or annotation. label : str Short label attached to a scenario, method, or plotted result. color : str Plot color used to identify this element. Returns ------- None Adds one labeled workflow box directly to the supplied Matplotlib axes. """ x, y = center width, height =0.135, 0.12 box = FancyBboxPatch( (x - width /2, y - height /2), width, height, boxstyle="round,pad=0.02", facecolor=color, edgecolor="#1f2937", linewidth=1.15, zorder=3, ) ax.add_patch(box) ax.text(x, y, label, ha="center", va="center", fontsize=10, fontweight="bold", zorder=4)def draw_arrow(ax, start, end):""" Idea: Draw a routed arrow between diagram nodes while keeping the arrowhead visible. Parameters ---------- ax : matplotlib.axes.Axes Axes object that receives the drawing commands. start : tuple[float, float] Starting coordinate for a plotted element. end : tuple[float, float] Ending coordinate for a plotted element. Returns ------- None Adds an arrow annotation directly to the supplied Matplotlib axes. """ arrow = FancyArrowPatch( start, end, arrowstyle="-|>", mutation_scale=18, linewidth=1.8, color="#334155", connectionstyle="arc3,rad=0.02", zorder=2, ) ax.add_patch(arrow)workflow_nodes = [ ((0.11, 0.56), "causal\ndesign", "#dbeafe"), ((0.305, 0.56), "DoubleMLData", "#ecfccb"), ((0.50, 0.56), "nuisance\nlearners", "#fef3c7"), ((0.695, 0.56), "orthogonal\nscore", "#ede9fe"), ((0.89, 0.56), "estimate +\nuncertainty", "#fee2e2"),]fig, ax = plt.subplots(figsize=(14, 5.5))ax.set_axis_off()ax.set_xlim(0, 1)ax.set_ylim(0, 1)for center, label, color in workflow_nodes: draw_workflow_box(ax, center, label, color)for left, right inzip(workflow_nodes[:-1], workflow_nodes[1:]): draw_arrow(ax, (left[0][0] +0.080, left[0][1]), (right[0][0] -0.080, right[0][1]))ax.text(0.5,0.18,"DoubleML helps with estimation and inference; the causal design supplies the identifying assumptions.", ha="center", va="center", fontsize=11, color="#475569",)ax.set_title("DoubleML Workflow At A Glance", pad=18, fontsize=16, fontweight="bold")fig.savefig(FIGURE_DIR /f"{NOTEBOOK_PREFIX}_doubleml_workflow.png", dpi=160, bbox_inches="tight")plt.show()
The central warning in the caption is that DoubleML gives a principled estimation engine once the design and estimand are defensible. The design still carries the causal claim.
Core Objects and Model Families
DoubleML uses a small set of recurring object types. The most important split is between data containers and model classes.
Data containers define which columns are outcome, treatment, controls, instruments, clusters, panels, or design-specific variables.
Model classes define the causal score, nuisance roles, resampling, and inference procedure.
Learners are ordinary scikit-learn-style estimators that DoubleML clones and fits inside cross-fitting.
The next step introspects the installed DoubleML version so the class list reflects this exact environment.
# Fit or evaluate the model objects used in the Core Object Tour section.core_class_names = ["DoubleMLData","DoubleMLClusterData","DoubleMLPanelData","DoubleMLDIDData","DoubleMLRDDData","DoubleMLSSMData","DoubleMLPLR","DoubleMLPLIV","DoubleMLIRM","DoubleMLIIVM","DoubleMLDID","DoubleMLDIDCS","DoubleMLSSM","DoubleMLAPO","DoubleMLAPOS","DoubleMLQTE","DoubleMLCVAR","DoubleMLBLP","DoubleMLPolicyTree",]class_rows = []for class_name in core_class_names:ifhasattr(dml, class_name): cls =getattr(dml, class_name)try: signature =str(inspect.signature(cls))except (TypeError, ValueError): signature ="signature not available" class_rows.append( {"class_name": class_name,"available": True,"signature": signature, } )else: class_rows.append({"class_name": class_name, "available": False, "signature": None})class_table = pd.DataFrame(class_rows)class_table.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_core_class_signatures.csv", index=False)display(class_table)
The class names hint at the breadth of the package. The early lessons focus on DoubleMLData, DoubleMLPLR, DoubleMLPLIV, DoubleMLIRM, and DoubleMLIIVM because those are the cleanest foundations for most learners.
Model Family Map
This table connects common causal designs to DoubleML classes. The exact details vary by model, but the pattern is stable: define the design, specify variable roles, pass learners for nuisance functions, fit, and report uncertainty.
design_or_estimand
main_class
typical_target
key_nuisance_roles
later_lesson
Partially linear regression with continuous treatment
DoubleMLPLR
Partially linear treatment coefficient
Outcome regression and treatment regression
03_partially_linear_regression_plr.ipynb
Partially linear IV with continuous treatment
DoubleMLPLIV
IV-based treatment coefficient
Outcome, treatment, and instrument-related nuisance functions
04_partially_linear_iv_pliv.ipynb
Binary treatment under unconfoundedness
DoubleMLIRM
ATE or ATT-style effect
Potential outcome regressions and propensity score
05_interactive_regression_model_irm.ipynb
Binary treatment with instrument
DoubleMLIIVM
Local treatment effect for instrument-induced treatment changes
Outcome, treatment, and instrument propensity functions
06_interactive_iv_model_iivm.ipynb
Difference-in-differences
DoubleMLDID or DoubleMLDIDCS
Average treatment effect in a DID design
Outcome trends and treatment/group assignment functions
Group, conditional, weighted, or distributional causal summaries
Model-specific nuisance functions and score components
14 and 15 lessons
This table is a compass for the tutorial series. If you know your design, you can usually identify the relevant DoubleML class and the nuisance learners that must be supplied.
Data Backend Mini Example
Before fitting a model, DoubleML needs to know which columns play which roles. The simplest container is DoubleMLData, which works for standard cross-sectional designs. We will create a small synthetic dataset with one outcome, one continuous treatment, and several controls.
The data-generating process below includes confounding by construction: controls affect both the treatment and the outcome. A naive regression of outcome on treatment alone will therefore mix the treatment effect with differences in controls.
# Define reusable helpers for the Data Backend Mini Example section.def simulate_plr_data(n_samples=1200, theta=1.50, seed=RANDOM_SEED):""" Simulate a partially linear regression design with nonlinear confounding. Parameters ---------- n_samples : int Number of observations generated, sampled, or evaluated. theta : object Treatment-effect parameter used in the score or simulation benchmark. seed : int Random seed for reproducible simulation or resampling. Returns ------- pd.DataFrame Dataset table for simulate PLR data, with the variables needed by the tutorial design. """ rng = np.random.default_rng(seed) x1 = rng.normal(size=n_samples) x2 = rng.normal(size=n_samples) x3 = rng.uniform(-1.5, 1.5, size=n_samples) x4 = rng.binomial(1, 0.45, size=n_samples) x5 = rng.normal(size=n_samples) m_x =0.80* x1 -0.55* x2 +0.35* np.sin(2* x3) +0.45* x4 d = m_x + rng.normal(scale=1.0, size=n_samples) g_x =0.70* x1 +0.45* x2**2-0.55* np.cos(x3) +0.35* x4 -0.25* x5 y = theta * d + g_x + rng.normal(scale=1.0, size=n_samples)return pd.DataFrame( {"y": y,"d": d,"x1": x1,"x2": x2,"x3": x3,"x4": x4,"x5": x5, } )plr_df = simulate_plr_data()plr_df.to_csv(DATASET_DIR /f"{NOTEBOOK_PREFIX}_synthetic_plr_data.csv", index=False)display(plr_df.head())print(f"Rows: {plr_df.shape[0]:,}")print(f"Columns: {plr_df.shape[1]:,}")
y
d
x1
x2
x3
x4
x5
0
1.275139
1.010518
0.304717
-1.322541
0.472002
0
2.241838
1
-1.287305
-0.245512
-1.039984
-0.486194
0.660648
0
-2.240704
2
-1.578987
-0.952198
0.750451
0.420227
0.424642
0
-0.388334
3
2.805975
-0.007625
0.940565
-0.102397
0.870729
0
-0.003689
4
-5.392201
-2.086379
-1.951035
-0.650564
0.374282
0
-0.781142
Rows: 1,200
Columns: 7
The first rows show the column names that we will pass into DoubleMLData. The true treatment effect in this synthetic example is 1.50, which gives us a ground truth for the smoke test. In real data, the true effect is not available.
The next table defines each variable. A variable dictionary is more than documentation; it prevents role confusion. In causal work, mistakenly treating a post-treatment variable as a control or forgetting an instrument role can change the estimand.
column
role
plain_language_meaning
y
outcome
Final outcome generated by treatment and controls.
d
treatment
Continuous treatment or exposure whose effect is targeted.
x1
control
Continuous confounder affecting treatment and outcome.
x2
control
Continuous confounder with nonlinear outcome relationship.
x3
control
Continuous confounder with sinusoidal treatment relationship.
x4
control
Binary control affecting treatment and outcome.
x5
control
Outcome-related control included in the adjustment set.
The roles line up with the PLR setup: one outcome, one treatment, and a set of pre-treatment controls. Later lessons will add instruments, panel variables, sample-selection variables, and running variables for RDD.
Now we create the DoubleML data object. Notice that this object does not fit a model. It only stores the analysis matrix and the role assignment.
================== DoubleMLData Object ==================
------------------ Data summary ------------------
Outcome variable: y
Treatment variable(s): ['d']
Covariates: ['x1', 'x2', 'x3', 'x4', 'x5']
Instrument variable(s): None
No. Observations: 1200
------------------ DataFrame info ------------------
<class 'pandas.DataFrame'>
RangeIndex: 1200 entries, 0 to 1199
Columns: 7 entries, y to x5
dtypes: float64(6), int64(1)
memory usage: 65.8 KB
The printed summary is a quick sanity check: the outcome, treatment, controls, and number of observations should match the variable dictionary. If this object is wrong, every downstream estimate inherits that mistake.
Minimal PLR Smoke Test
Quick Data Audit
Before running DoubleML, inspect the basic distribution of each column and the relationship between treatment and controls. This serves a different role than a replacement for identification thinking. It catches practical problems such as missingness, constant columns, extreme values, and weak treatment variation.
The audit shows no missingness and enough variation in every variable. The binary column x4 has two unique values, which is expected.
The later estimates should be read in light of this sample construction, since data quality and composition set the boundary for any causal claim.
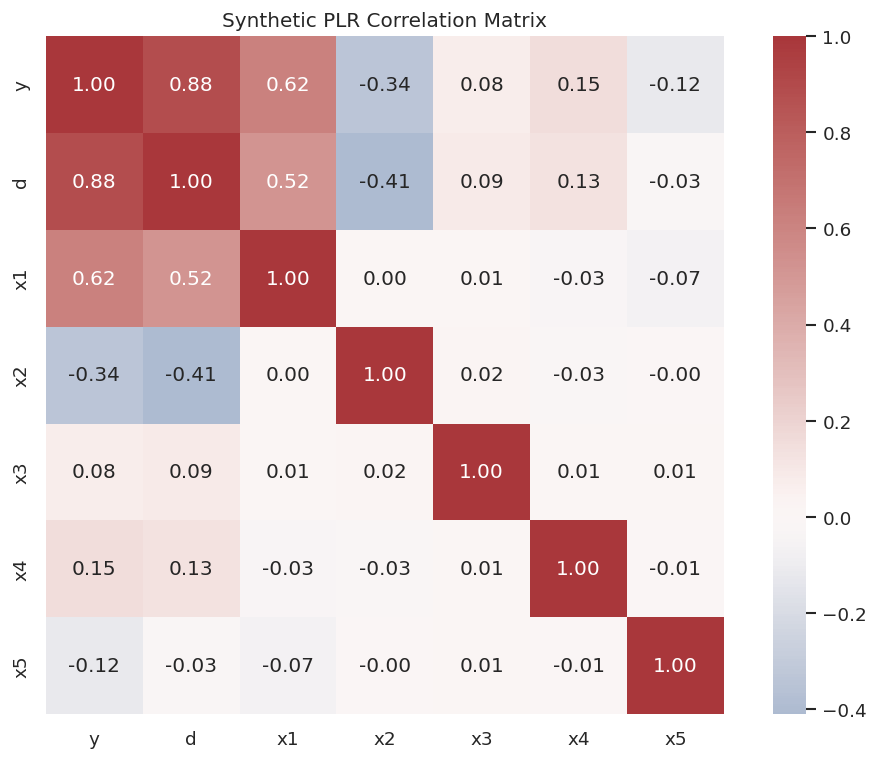
This correlation plot is a lightweight way to see confounding pressure. If controls are related to the treatment and outcome, adjustment is needed. The plot does not prove the adjustment set is valid; it simply shows why naive treatment-outcome association is not enough.
The treatment is correlated with several controls, and the outcome is correlated with both treatment and controls. That is the setting where a well-specified causal adjustment workflow matters.
Cross-Fitting Intuition
Cross-fitting is easier to understand visually than verbally. In each fold, nuisance learners train on the training portion and predict nuisance values only for the held-out portion. After rotating across folds, every row has out-of-fold nuisance predictions.
The final causal estimate is then computed from those held-out nuisance predictions, not from in-sample predictions that could overfit each observation.
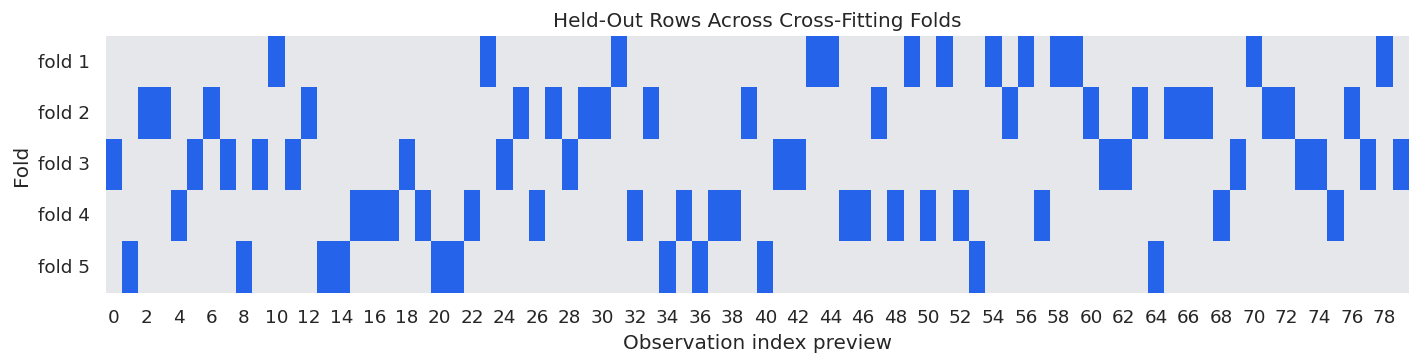
Each row appears in a held-out fold exactly once for a single 5-fold split. DoubleML can also repeat sample splitting, which is covered later in the tutorial series.
The next figure shows the fold assignment for the first 80 rows. Dark cells are held-out rows for a given fold. Each column is one observation, and each row is one nuisance-training fold.
The visual reinforces the core discipline: the row being scored is not used to train its nuisance prediction. That separation is one of the reasons DoubleML can use flexible learners while still supporting inference.
A Minimal DoubleMLPLR Smoke Test
We now fit a small DoubleMLPLR model. In PLR, DoubleML needs:
ml_l: learner for the outcome nuisance function, roughly predicting Y from X;
ml_m: learner for the treatment nuisance function, roughly predicting D from X;
a score, here partialling out;
cross-fitting settings, here 5 folds and 1 repeated split.
The random forests below are modest so the lesson runs quickly.
Before fitting, the object summary already documents the data roles, score, learners, and resampling plan. This is useful because it catches mismatches before compute time is spent.
The code below fits the model and extracts the main estimate table. Since the data is synthetic, we also add the true effect and the estimation error.
The coefficient is close to the synthetic truth. In real applications, we do not know the truth, so the same table would be read together with uncertainty, design assumptions, sensitivity checks, and diagnostics.
Naive Baselines versus DoubleML
A good library tour should show what DoubleML is protecting us from. The next step compares three estimates:
naive regression of Y on D only;
linear regression of Y on D and the raw controls;
DoubleML PLR with flexible nuisance models and cross-fitting.
The first baseline ignores confounding. The second adjusts linearly but cannot fully match the nonlinear data-generating process. DoubleML uses flexible learners for the nuisance functions while targeting a low-dimensional causal parameter.
# Fit or evaluate the model objects used in the Naive Baselines Versus DoubleML section.naive_model = LinearRegression().fit(plr_df[["d"]], plr_df["y"])linear_adjusted_model = LinearRegression().fit(plr_df[["d"] + x_cols], plr_df["y"])comparison_table = pd.DataFrame( [ {"method": "naive_y_on_d","estimate": float(naive_model.coef_[0]),"absolute_error_vs_truth": abs(float(naive_model.coef_[0]) - TRUE_THETA),"uses_controls": False,"uses_cross_fitting": False, }, {"method": "linear_adjusted_y_on_d_plus_x","estimate": float(linear_adjusted_model.coef_[0]),"absolute_error_vs_truth": abs(float(linear_adjusted_model.coef_[0]) - TRUE_THETA),"uses_controls": True,"uses_cross_fitting": False, }, {"method": "doubleml_plr_random_forest_nuisance","estimate": float(plr_model.coef[0]),"absolute_error_vs_truth": abs(float(plr_model.coef[0]) - TRUE_THETA),"uses_controls": True,"uses_cross_fitting": True, }, ])comparison_table.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_naive_vs_doubleml_estimates.csv", index=False)display(comparison_table.round(4))
method
estimate
absolute_error_vs_truth
uses_controls
uses_cross_fitting
0
naive_y_on_d
1.7958
0.2958
False
False
1
linear_adjusted_y_on_d_plus_x
1.4919
0.0081
True
False
2
doubleml_plr_random_forest_nuisance
1.4965
0.0035
True
True
The contrast shows the purpose of the package. DoubleML is not trying to beat every prediction benchmark; it is using prediction tools to estimate a causal effect with reduced nuisance-induced bias.
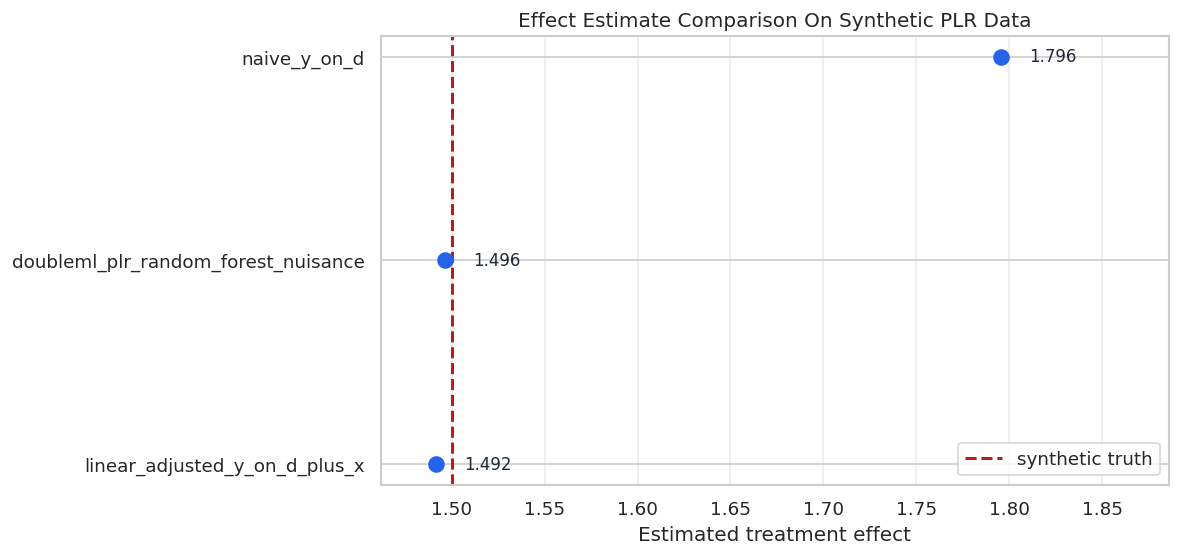
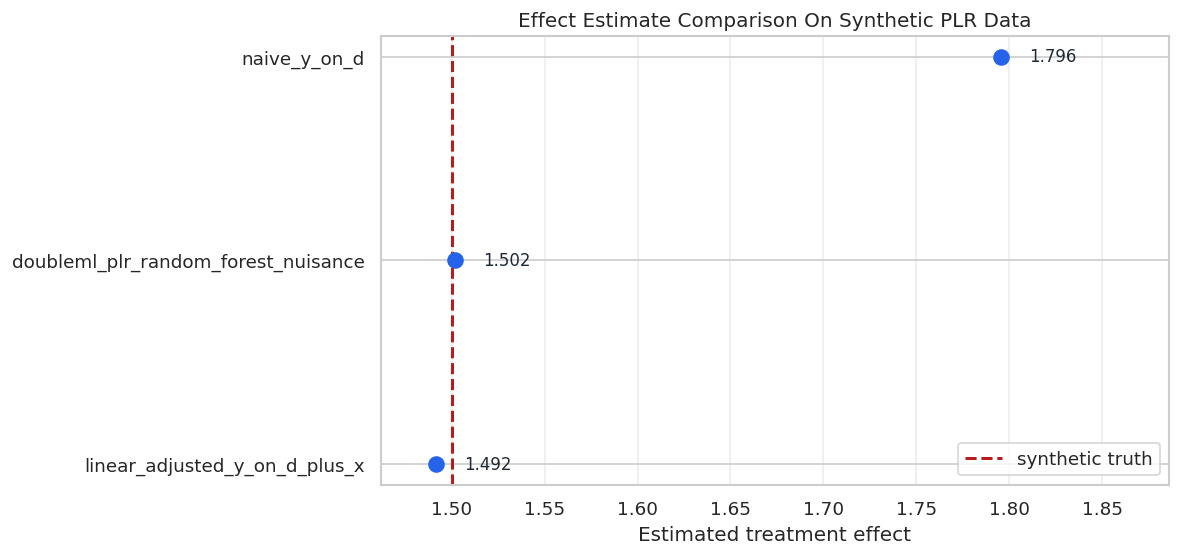
The plot below places the estimates next to the true synthetic effect. This style of plot is useful in tutorials and simulations because it makes bias visible. In real data, the vertical truth line would be unavailable.
The DoubleML estimate lands close to the synthetic truth in this run. The naive estimate is visibly inflated because treatment assignment is confounded by controls that also affect the outcome.
Nuisance Predictions and Losses
DoubleML stores nuisance predictions and nuisance losses. These are diagnostic supports for the final causal result. They help diagnose whether the nuisance learners are doing something reasonable. Bad nuisance models can still damage finite-sample performance even when the score is orthogonal.
nuisance_loss_rows = []for learner_name, loss_array in plr_model.nuisance_loss.items(): nuisance_loss_rows.append( {"learner_role": learner_name,"loss_value": float(np.asarray(loss_array).ravel()[0]),"loss_type": "mean squared error for this regression learner", } )nuisance_loss_table = pd.DataFrame(nuisance_loss_rows)nuisance_loss_table.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_plr_nuisance_losses.csv", index=False)display(nuisance_loss_table.round(4))
learner_role
loss_value
loss_type
0
ml_l
1.9680
mean squared error for this regression learner
1
ml_m
1.0907
mean squared error for this regression learner
The two nuisance losses summarize how well the learners predicted the outcome nuisance and treatment nuisance. They are useful diagnostics, and the causal score and identification assumptions still determine how much the causal estimate can be trusted.
The next step extracts out-of-fold nuisance predictions and compares them with the observed variables. This gives a quick check that the nuisance learners learned meaningful signal from the covariates.
pred_l = np.asarray(plr_model.predictions["ml_l"]).squeeze()pred_m = np.asarray(plr_model.predictions["ml_m"]).squeeze()prediction_quality = pd.DataFrame( [ {"nuisance_role": "ml_l predicts y from x","rmse": mean_squared_error(plr_df["y"], pred_l) **0.5,"r2": r2_score(plr_df["y"], pred_l), }, {"nuisance_role": "ml_m predicts d from x","rmse": mean_squared_error(plr_df["d"], pred_m) **0.5,"r2": r2_score(plr_df["d"], pred_m), }, ])prediction_quality.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_plr_nuisance_prediction_quality.csv", index=False)display(prediction_quality.round(4))
nuisance_role
rmse
r2
0
ml_l predicts y from x
1.9680
0.5348
1
ml_m predicts d from x
1.0907
0.4066
The nuisance models capture real signal, especially for treatment assignment. That makes sense because the synthetic treatment equation was generated from controls. Later lessons will spend much more time on learner choice and tuning.
This scatter plot visualizes observed versus out-of-fold predicted nuisance values. The plots are diagnostic aids, not final causal evidence.
The treatment nuisance has a clearer relationship because treatment assignment was strongly driven by controls. The outcome nuisance is harder because the outcome also contains the treatment effect and noise.
Built-In Dataset Functions
This installed DoubleML version exposes dataset fetch helpers. We will list them and save their signatures, but we will not fetch data in this first lesson. Keeping the first tutorial offline-friendly makes it more reliable for students and for automated execution.
Data set on the Pennsylvania Reemployment Bonus experiment.
False
The fetch helpers are useful for examples, but synthetic data is better for this opening lesson because we can know the true effect and show what DoubleML is recovering.
What DoubleML Does and Does Not Do
This is the most important conceptual boundary in the lesson. DoubleML can make effect estimation more robust to nuisance-model complexity, but it cannot repair a bad design. The table below separates package responsibilities from analyst responsibilities.
task
main_owner
doubleml_role
Define the causal question
analyst
None directly; the package fits models after the question is specified.
Choose an identification strategy
analyst
Provides model classes for several strategies, but does not validate assumptions by itself.
Assign variable roles
analyst
Stores roles in data backend objects and uses them during fitting.
Estimate nuisance functions
DoubleML plus supplied learners
Clones learners, fits cross-fitted nuisance models, and stores predictions/losses.
Solve orthogonal score
DoubleML
Computes target estimates using model-specific orthogonal moments.
Quantify uncertainty
DoubleML
Reports standard errors, confidence intervals, p-values, and bootstrap tools where available.
Write credible conclusions
analyst
Supplies estimates and diagnostics that must be reported with design caveats.
The analyst owns the design. DoubleML owns a lot of the estimation mechanics. The best work keeps both responsibilities visible.
The table is useful because it compresses the evidence into a form that can be compared, audited, and tied back to the causal question.
Tutorial Series Roadmap
The remaining lessons turn this overview into a full hands-on sequence. This roadmap is written as a practical learning path: start with theory and data roles, then core model families, then inference, diagnostics, advanced APIs, and an end-to-end case study.
lesson
theme
main_skill
00_environment_and_library_tour.ipynb
Orientation
Understand what DoubleML is for and run a first PLR smoke test.
Diagnose overlap, leakage, weak instruments, and bad controls.
18_end_to_end_doubleml_case_study.ipynb
Case study
Combine the full workflow into a concise written conclusion.
The next natural lesson is the theory lesson. It will slow down on orthogonality and cross-fitting so the package mechanics feel motivated and auditable.
Reporting and Takeaways
Starter Report Checklist
Even a first smoke test should end with a reporting checklist. This keeps the tutorial grounded in applied causal analysis with package mechanics in service of the design.
check
status_in_this_lesson
why_it_matters
Causal question stated
synthetic PLR effect of d on y
The target parameter must be clear before fitting.
Variable roles defined
y, d, x1-x5 dictionary saved
Data-role mistakes change the analysis.
Identification assumptions stated
PLR synthetic design with controls sufficient by construction
DoubleML estimation still relies on design assumptions.
Nuisance learners documented
random forest settings printed and saved through model object
Learner choices affect finite-sample behavior.
Cross-fitting documented
5-fold cross-fitting preview saved
Out-of-fold nuisance prediction is central to DML.
Estimate and uncertainty reported
PLR summary table saved
A point estimate without uncertainty is incomplete.
Limitations stated
synthetic truth available only because this is a tutorial
Real analyses do not get a known true effect.
This checklist is small now, but the later lessons will expand it with overlap diagnostics, sensitivity analysis, learner tuning, sample splitting uncertainty, and design-specific checks.
Reusable Analysis Template
The last substantive output is a small markdown template. It gives students a simple structure for writing up a DoubleML result without skipping the design assumptions.
The template is compact. It keeps the final communication centered on the causal design, more than the package output.
For the broader lesson, the estimate should be interpreted together with the identifying assumptions and diagnostics that make it credible.
Closing Notes
The main takeaway is that DoubleML is an estimation framework for causal designs with flexible nuisance learning. The theory protects the target parameter from first-stage prediction mistakes, but it does not remove the need for careful design.
The sequence next goes deeper into core theory, including regularization bias, orthogonal scores, sample splitting, and cross-fitting.