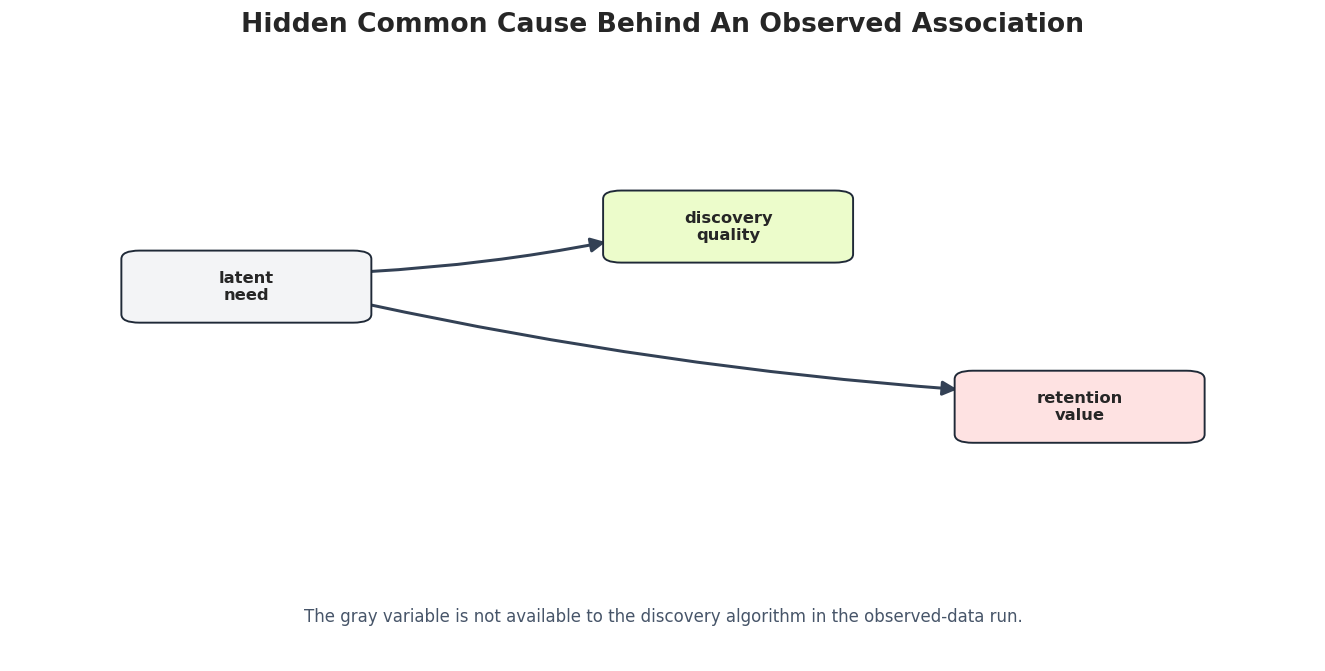
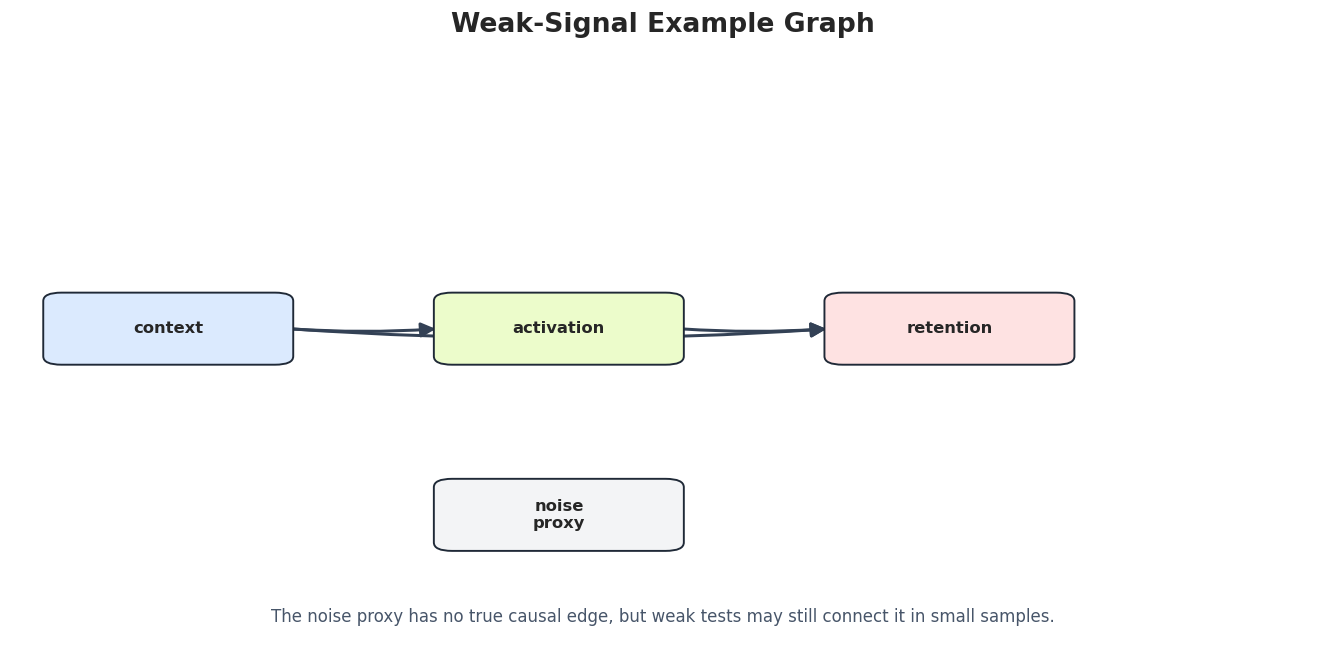
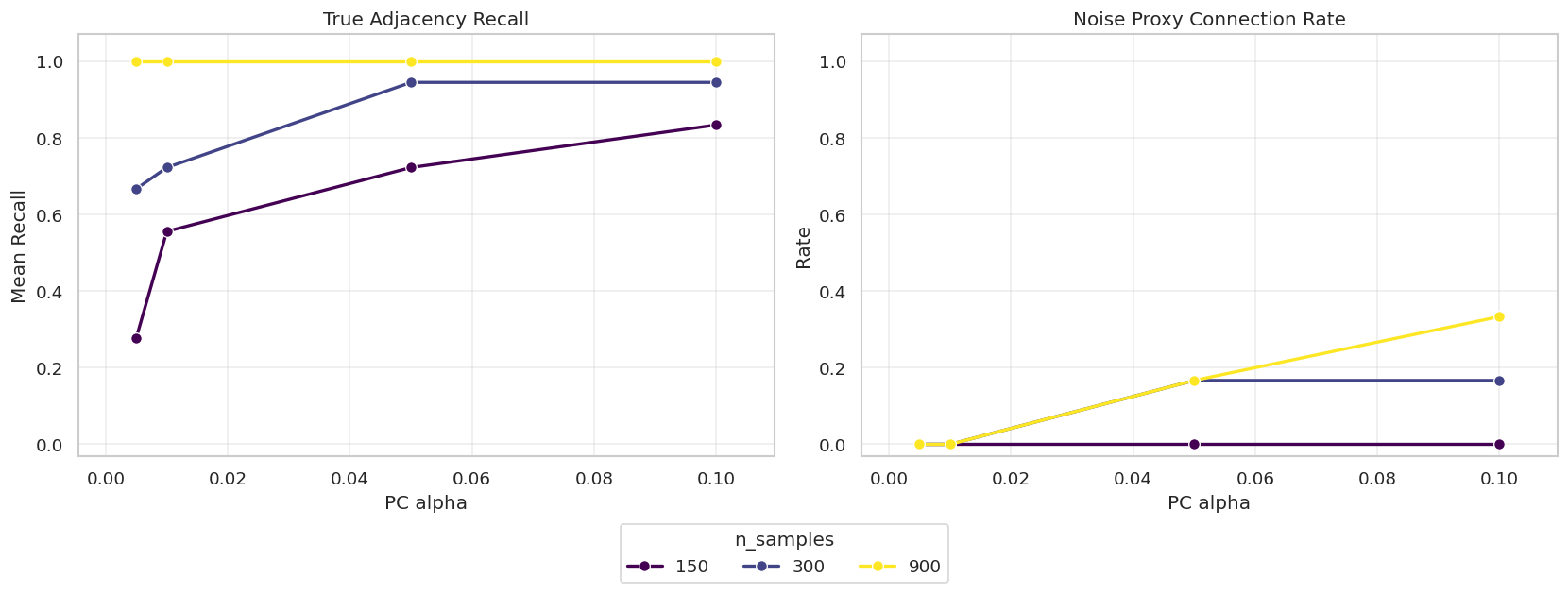
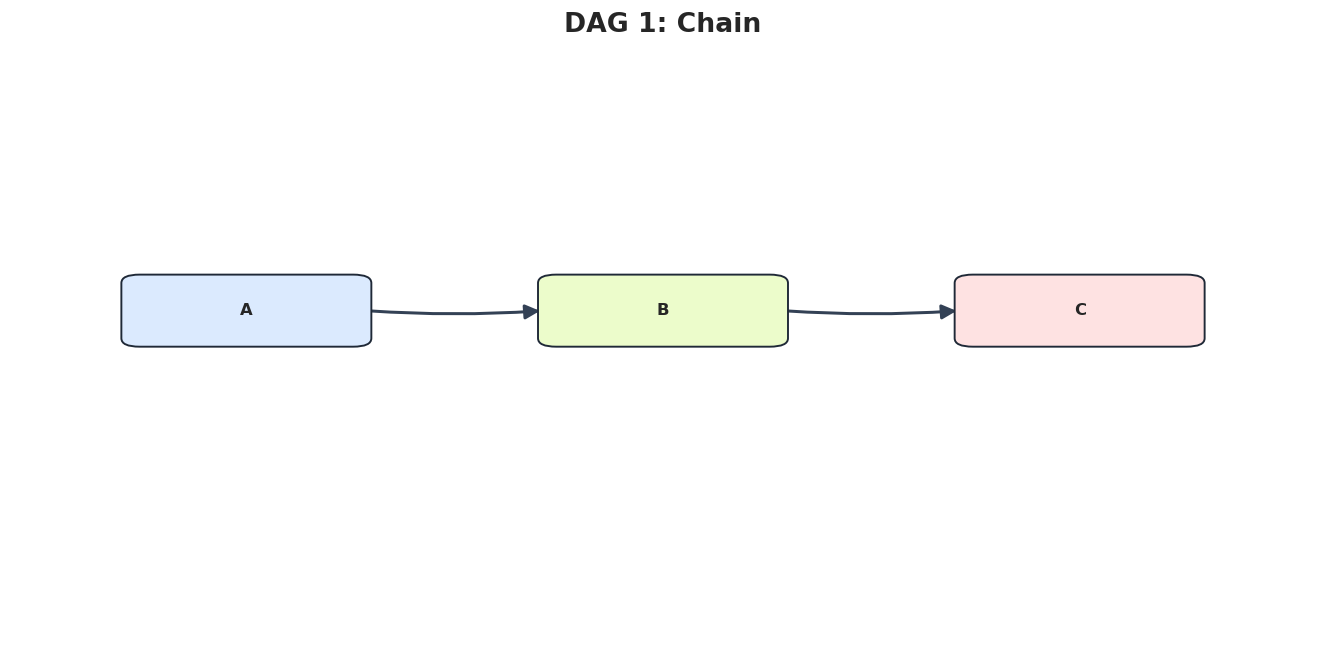
# Define reusable helpers for the Reusable Graph And Evaluation Helpers section.
def trim_edge_to_box(start, end, box_w=0.16, box_h=0.09, gap=0.012):
"""
Shorten an edge so arrows land outside rounded boxes rather than under labels.
Parameters
----------
start : tuple[float, float]
Starting coordinate of the arrow or edge segment.
end : tuple[float, float]
Ending coordinate of the arrow or edge segment.
box_w : float
Width of the node box used to trim edge endpoints.
box_h : float
Height of the node box used to trim edge endpoints.
gap : float
Extra spacing between an edge endpoint and a node boundary.
Returns
-------
tuple[tuple[float, float], tuple[float, float]]
Start and end coordinates trimmed so the edge stops at box boundaries.
"""
x0, y0 = start
x1, y1 = end
dx = x1 - x0
dy = y1 - y0
distance = (dx**2 + dy**2) ** 0.5
if distance == 0:
return start, end
ux, uy = dx / distance, dy / distance
candidates = []
if abs(ux) > 1e-9:
candidates.append((box_w / 2) / abs(ux))
if abs(uy) > 1e-9:
candidates.append((box_h / 2) / abs(uy))
offset = min(candidates) + gap
return (x0 + ux * offset, y0 + uy * offset), (x1 - ux * offset, y1 - uy * offset)
def draw_box_graph(edge_df, node_specs, title, path, note=None, highlight_edges=None):
"""
Draw a compact causal graph using the notebook's rounded-box figure style.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
node_specs : object
Node-position and label specifications used to draw the graph.
title : str
Title shown above the plot.
path : str or pathlib.Path
Optional output path for the figure.
note : str or None
Optional explanatory note shown in the plot.
highlight_edges : pd.DataFrame or collection
Edges associated with `highlight`.
Returns
-------
None
Draws the graph diagram directly on the Matplotlib axes and saves it when requested.
"""
highlight_edges = highlight_edges or set()
fig, ax = plt.subplots(figsize=(14, 6.5))
ax.set_axis_off()
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
for row in edge_df.itertuples(index=False):
if row.source not in node_specs or row.target not in node_specs:
continue
start, end = trim_edge_to_box(node_specs[row.source]["xy"], node_specs[row.target]["xy"])
edge_type = getattr(row, "edge_type", "-->")
edge_key = (row.source, row.target)
color = "#7c3aed" if edge_key in highlight_edges else "#334155"
arrowstyle = "-|>" if edge_type == "-->" else "-"
linestyle = "--" if edge_type in {"o-o", "<->"} else "solid"
linewidth = 2.4 if edge_key in highlight_edges else 1.8
arrow = FancyArrowPatch(
start,
end,
arrowstyle=arrowstyle,
mutation_scale=18,
linewidth=linewidth,
color=color,
linestyle=linestyle,
connectionstyle="arc3,rad=0.035",
zorder=2,
)
ax.add_patch(arrow)
for variable, spec in node_specs.items():
x, y = spec["xy"]
rect = FancyBboxPatch(
(x - 0.082, y - 0.046),
0.164,
0.092,
boxstyle="round,pad=0.014",
facecolor=spec.get("color", "#dbeafe"),
edgecolor="#1f2937",
linewidth=1.15,
zorder=4,
)
ax.add_patch(rect)
ax.text(x, y, spec.get("label", variable), ha="center", va="center", fontsize=9.8, fontweight="bold", zorder=5)
if note:
ax.text(0.5, 0.07, note, ha="center", va="center", fontsize=10, color="#475569")
ax.set_title(title, pad=16, fontsize=16, fontweight="bold")
fig.savefig(path, dpi=160, bbox_inches="tight")
plt.show()
def make_edge_table(edges, run="manual"):
"""
Idea: Construct the edge table used in the Reusable Graph And Evaluation Helpers section, including columns needed for later diagnostics.
Parameters
----------
edges : object
Collection of graph edges to draw, compare, or convert into a table.
run : object
Run index used to label a repeated simulation or benchmark.
Returns
-------
pd.DataFrame
Dataset table for make edge table, with the variables needed by the tutorial design.
"""
return pd.DataFrame(
[{"run": run, "source": source, "edge_type": edge_type, "target": target} for source, edge_type, target in edges],
columns=["run", "source", "edge_type", "target"],
)
def parse_causallearn_edge(edge):
"""
Idea: Convert a causal-learn graph edge object into plain endpoint labels for tabular auditing.
Parameters
----------
edge : object
Single graph edge being parsed, drawn, or evaluated.
Returns
-------
tuple[str, str, str]
Source node, endpoint mark, and target node parsed from a causal-learn edge.
"""
text = str(edge).strip()
edge_tokens = [" --> ", " <-- ", " <-> ", " o-> ", " <-o ", " o-o ", " --- "]
for token in edge_tokens:
if token in text:
left, right = text.split(token)
if token == " <-- ":
return {"source": right.strip(), "edge_type": "-->", "target": left.strip()}
if token == " <-o ":
return {"source": right.strip(), "edge_type": "o->", "target": left.strip()}
return {"source": left.strip(), "edge_type": token.strip(), "target": right.strip()}
raise ValueError(f"Could not parse edge: {text}")
def graph_to_edge_table(graph, label):
"""
Idea: Convert a causal-learn graph object into a DataFrame of edge endpoints and method labels.
Parameters
----------
graph : object
Graph object returned by the causal discovery or causal modeling library.
label : str
Short label attached to a scenario, method, or plotted result.
Returns
-------
pd.DataFrame
Edge table with source, target, edge mark, and method metadata.
"""
rows = [parse_causallearn_edge(edge) for edge in graph.get_graph_edges()]
edge_table = pd.DataFrame(rows, columns=["source", "edge_type", "target"])
edge_table.insert(0, "run", label)
return edge_table
def standardize_frame(df):
"""
Idea: Compute the frame needed in the Reusable Graph And Evaluation Helpers section and return it in a form the next cells can inspect.
Parameters
----------
df : pd.DataFrame
Rows used by this helper.
Returns
-------
pd.DataFrame
Standardized copy of the input DataFrame with the original column names preserved.
"""
return pd.DataFrame(StandardScaler().fit_transform(df), columns=df.columns)
def run_pc_edges(df, alpha=0.05, label="PC"):
"""
Idea: Run PC and convert the learned graph into a comparable edge table.
Parameters
----------
df : pd.DataFrame
Rows used by this helper.
alpha : float
Significance level, transparency value, or tuning parameter used by the diagnostic.
label : str
Short label attached to a scenario, method, or plotted result.
Returns
-------
pd.DataFrame
Edge table recovered by PC for the requested dataset.
"""
started = time.perf_counter()
graph = pc(
df.to_numpy(),
alpha=alpha,
indep_test="fisherz",
stable=True,
verbose=False,
show_progress=False,
node_names=list(df.columns),
).G
elapsed = time.perf_counter() - started
return graph_to_edge_table(graph, label), elapsed
def run_fci_edges(df, alpha=0.05, label="FCI"):
"""
Idea: Run FCI and convert the learned graph into a comparable edge table.
Parameters
----------
df : pd.DataFrame
Rows used by this helper.
alpha : float
Significance level, transparency value, or tuning parameter used by the diagnostic.
label : str
Short label attached to a scenario, method, or plotted result.
Returns
-------
pd.DataFrame
Edge table recovered by FCI for the requested dataset.
"""
started = time.perf_counter()
graph, _ = fci(
df.to_numpy(),
independence_test_method="fisherz",
alpha=alpha,
verbose=False,
show_progress=False,
node_names=list(df.columns),
)
elapsed = time.perf_counter() - started
return graph_to_edge_table(graph, label), elapsed
def skeleton_pairs(edge_df):
"""
Idea: Reduce an edge table to unordered node pairs so skeleton recovery can be evaluated.
Parameters
----------
edge_df : pd.DataFrame
Graph edges or edge-level diagnostics to summarize.
Returns
-------
set[tuple[str, str]]
Unordered node pairs representing the learned graph skeleton.
"""
if edge_df.empty:
return set()
return {tuple(sorted((row.source, row.target))) for row in edge_df.itertuples(index=False)}
def directed_pairs(edge_df):
"""
Idea: Extract directed edge pairs from an edge table so orientation recovery can be evaluated.
Parameters
----------
edge_df : pd.DataFrame
Graph edges or edge-level diagnostics to summarize.
Returns
-------
set[tuple[str, str]]
Ordered source-target pairs representing directed learned edges.
"""
if edge_df.empty:
return set()
return {(row.source, row.target) for row in edge_df.itertuples(index=False) if row.edge_type == "-->"}