A single causal discovery run is rarely enough. Discovery algorithms make assumptions about independence tests, scores, linearity, noise, hidden variables, sample size, and tuning choices. If a learned graph changes completely when one of those choices changes, the graph should be treated as a fragile hypothesis.
We build a compact benchmarking workflow for causal-learn. We will simulate data from a known observed DAG, run several algorithm families, and then stress-test the learned graphs across sample size, noise, tuning settings, nonlinearity, and hidden confounding.
The goal is to learn how to report causal discovery results honestly: what was stable, what changed, and which assumptions each method needed.
Estimated runtime: about 2-5 minutes. Most cells are fast; the repeated benchmark grids do several PC, GES, and DirectLiNGAM fits.
Learning Goals
By the end, you should be able to:
design a small benchmark with known graph truth;
compare constraint-based, score-based, and functional causal discovery methods;
separate skeleton recovery from edge direction recovery;
run sample-size, noise, tuning, and seed stability checks;
recognize when hidden confounding or nonlinear structure breaks an observed-DAG benchmark;
produce compact benchmark tables and figures suitable for a causal discovery report.
Dataset and Experiment Setup
We use synthetic graph-discovery datasets with known structural equations and known graph truth to study Benchmarking, Stability, And Sensitivity. Known graph truth lets us see when an algorithm recovers edges, misses edges, or invents edges under violated assumptions.
Read each row as a draw from a structural causal system. Columns are observed variables, and in some lessons omitted latent variables, environments, time ordering, or non-Gaussian mechanisms are deliberately introduced. The experiment shows a setting where treatment choice is endogenous and identification must come from a source of quasi-random variation. The experiment asks how much the conclusion changes when assumptions are weakened, altered, or attacked by plausible failure modes.
The goal is to learn what each discovery method assumes and how its output should be audited.
Mathematical Foundation
Causal discovery produces an estimated graph \(\widehat G\). A compact benchmark compares it with a reference graph \(G\) through structural Hamming distance,
The reporting goal is to show which edges are stable, which assumptions matter, and which conclusions remain tentative.
We will work in this order:
Set up imports, outputs, algorithms, and graph helpers.
Define a reusable six-variable teaching DAG.
Simulate baseline data and draw the true graph.
Run PC, GES, and DirectLiNGAM on the same baseline data.
Compare skeleton and direction metrics.
Run sample-size and seed stability checks.
Run noise and tuning sensitivity checks.
Run stress scenarios: Gaussian noise, nonlinear effects, and hidden confounding.
Run a targeted FCI check under hidden confounding.
Save reporting guidance.
Diagnostics and Interpretation
Benchmarking Philosophy
Causal discovery benchmarking has a subtle trap: a method can look excellent on data generated exactly from its assumptions and weak elsewhere. That does not make the method bad. It means the benchmark must say what assumptions were tested.
We use three representative methods:
PC: constraint-based discovery using conditional independence tests;
GES: score-based search using a decomposable graph score;
DirectLiNGAM: functional causal discovery for linear non-Gaussian models.
We evaluate two graph layers separately. Skeleton metrics ask whether the right variables are adjacent, ignoring arrow direction. Directed metrics ask whether arrows point the same way as the true DAG. This separation matters because PC and GES often return partially directed equivalence-class graphs, while LiNGAM returns a directed graph.
Setup
The code below imports the scientific stack, causal-learn algorithms, and plotting utilities. It also applies the same local BIC-score compatibility wrapper used in earlier lessons, which keeps GES working cleanly in this Python and NumPy environment without editing the installed package on disk.
# Build and label the diagnostic visualization for the Setup section.from pathlib import Pathimport osimport reimport timeimport warningsPROJECT_ROOT = Path.cwd().resolve()if PROJECT_ROOT.name =="causal_learn": PROJECT_ROOT = PROJECT_ROOT.parents[2]OUTPUT_DIR = PROJECT_ROOT /"notebooks"/"tutorials"/"causal_learn"/"outputs"DATASET_DIR = OUTPUT_DIR /"datasets"FIGURE_DIR = OUTPUT_DIR /"figures"TABLE_DIR = OUTPUT_DIR /"tables"MATPLOTLIB_CACHE_DIR = OUTPUT_DIR /"matplotlib_cache"for directory in [DATASET_DIR, FIGURE_DIR, TABLE_DIR, MATPLOTLIB_CACHE_DIR]: directory.mkdir(parents=True, exist_ok=True)os.environ.setdefault("MPLCONFIGDIR", str(MATPLOTLIB_CACHE_DIR))warnings.filterwarnings("ignore", category=FutureWarning)warnings.filterwarnings("ignore", message="IProgress not found.*")warnings.filterwarnings("ignore", message="Using 'local_score_BIC_from_cov' instead for efficiency")import numpy as npimport pandas as pdpd.set_option("display.max_colwidth", None)pd.set_option("display.max_columns", None)pd.set_option("display.width", 0)import matplotlib.pyplot as pltimport seaborn as snsfrom matplotlib.patches import FancyArrowPatch, FancyBboxPatchfrom IPython.display import displayfrom sklearn.preprocessing import StandardScalerfrom causallearn.search.ConstraintBased.PC import pcfrom causallearn.search.ConstraintBased.FCI import fciimport causallearn.search.ScoreBased.GES as ges_modulefrom causallearn.search.ScoreBased.GES import gesfrom causallearn.search.FCMBased.lingam.direct_lingam import DirectLiNGAMNOTEBOOK_PREFIX ="15"RANDOM_SEED =42sns.set_theme(style="whitegrid", context="notebook")plt.rcParams.update({"figure.dpi": 120, "savefig.dpi": 160})print(f"Project root: {PROJECT_ROOT}")print(f"Outputs: {OUTPUT_DIR}")
The setup confirms where the lesson writes files. All generated outputs in this lesson use the 15_ prefix.
This reproducibility check keeps the run auditable before causal interpretation begins. It makes the run consistent enough for later graphs, tables, and estimates to be checked against the same environment.
Package Versions
Benchmark results are easier to reproduce when package versions are saved alongside the output tables.
The exact versions are now saved. This matters because graph search and numerical thresholds can shift slightly across library releases.
This reproducibility check keeps the run auditable before causal interpretation begins. It makes the run consistent enough for later graphs, tables, and estimates to be checked against the same environment.
GES BIC Compatibility Wrapper
This wrapper keeps the GES BIC score numerically safe when recent NumPy versions return one-element matrix objects. The score formula is unchanged; we only convert a one-element result into a Python scalar.
def local_score_BIC_from_cov(Data, i, PAi, parameters=None):""" Safe local BIC score used by GES in this lesson. Parameters ---------- Data : array-like Data matrix passed by causal-learn into the local score function. i : int Target variable index for the local score calculation. PAi : list[int] Parent indices proposed for the target variable in the local score. parameters : dict Score-function parameters supplied by causal-learn. Returns ------- float BIC-style local score for one target variable and candidate parent set. """ cov, n = Data lambda_value =1.0if parameters isNoneor parameters.get("lambda_value") isNoneelse parameters.get("lambda_value") parent_indices =list(PAi)iflen(parent_indices) ==0: residual_variance = cov[i, i]else: yX = cov[np.ix_([i], parent_indices)] XX = cov[np.ix_(parent_indices, parent_indices)] beta = np.linalg.solve(XX, yX.T) residual_variance = cov[i, i] -float((yX @ beta).item()) residual_variance =max(float(residual_variance), 1e-12)returnfloat(-(n /2) * np.log(residual_variance) - (len(parent_indices) +1) * lambda_value * np.log(n) /2)ges_module.local_score_BIC_from_cov = local_score_BIC_from_covprint("GES BIC score wrapper is active.")
GES BIC score wrapper is active.
The wrapper is active for this lesson session only. It does not modify the installed package files.
For the discovery workflow, this result should be read as evidence about graph recovery under the stated assumptions.
Define the Benchmark DAG
The benchmark graph has six variables and six directed edges. It is small enough to run many times, but rich enough to include a collider, a chain, and a downstream variable with two parents.
This truth table is used by all benchmark metrics. The same true graph is reused across stress scenarios so we can see when violated assumptions create extra or missing observed relationships.
Simulate Data from the DAG
The simulator can generate several regimes from the same graph:
linear Laplace noise for a baseline that favors DirectLiNGAM;
linear Gaussian noise for Markov-equivalence-focused methods;
nonlinear transformations for a simple functional misspecification check;
hidden common causes that violate causal sufficiency.
The hidden-confounding regime should be read carefully: once a hidden common cause exists, the observed DAG is no longer a complete causal graph.
# Define reusable helpers for the Simulate Data From The DAG section.def draw_noise(rng, family, scale, n_samples):""" Idea: Generate noise from the requested family so robustness checks can compare data-generating conditions. Parameters ---------- rng : np.random.Generator Random generator that makes the simulation reproducible. family : object Noise family or model family used for the scenario. scale : float Scale parameter for noise or plotting. n_samples : int Number of sampled rows or simulated units. Returns ------- np.ndarray Noise vector drawn from the requested distribution and scale. """if family =="laplace":return rng.laplace(loc=0.0, scale=scale, size=n_samples)if family =="gaussian":return rng.normal(loc=0.0, scale=scale, size=n_samples)if family =="student_t":return rng.standard_t(df=4, size=n_samples) * scale / np.sqrt(2)raiseValueError(f"Unknown noise family: {family}")def simulate_benchmark_data( n_samples=600, seed=RANDOM_SEED, noise_family="laplace", noise_scale=1.0, nonlinear=False, hidden_strength=0.0,):""" Simulate the six-variable benchmark graph. Parameters ---------- n_samples : int Number of observations generated, sampled, or evaluated. seed : int Random seed for reproducible simulation or resampling. noise_family : object Noise distribution family used in the benchmark simulation. noise_scale : object Noise scale used to control signal-to-noise difficulty in the simulation. nonlinear : object Whether nonlinear mechanisms are included in the simulated graph. hidden_strength : object Strength of the hidden confounder injected into the simulation. Returns ------- pd.DataFrame Benchmark dataset with known graph structure, noise family, and recovery target. """ rng = np.random.default_rng(seed) hidden = draw_noise(rng, noise_family, scale=1.0, n_samples=n_samples) need = draw_noise(rng, noise_family, noise_scale, n_samples) + hidden_strength * hidden intent = draw_noise(rng, noise_family, noise_scale, n_samples) + hidden_strength * hiddenif nonlinear: match =0.70* np.tanh(need) +0.60* intent + draw_noise(rng, noise_family, noise_scale, n_samples) engagement =0.75* np.tanh(match) + draw_noise(rng, noise_family, noise_scale, n_samples)else: match =0.70* need +0.60* intent + draw_noise(rng, noise_family, noise_scale, n_samples) engagement =0.75* match + draw_noise(rng, noise_family, noise_scale, n_samples) support =-0.65* engagement + draw_noise(rng, noise_family, noise_scale, n_samples) renewal =0.65* engagement -0.45* support + draw_noise(rng, noise_family, noise_scale, n_samples) + hidden_strength * hidden raw = pd.DataFrame( {"need": need,"intent": intent,"match": match,"engagement": engagement,"support": support,"renewal": renewal, } ) scaled = pd.DataFrame(StandardScaler().fit_transform(raw), columns=VARIABLES)return scaledbaseline_df = simulate_benchmark_data(n_samples=600, seed=RANDOM_SEED, noise_family="laplace")baseline_df.to_csv(DATASET_DIR /f"{NOTEBOOK_PREFIX}_baseline_linear_laplace.csv", index=False)display(baseline_df.head())
need
intent
match
engagement
support
renewal
0
-0.051522
0.054419
0.135313
0.193165
0.428653
-0.282088
1
0.463170
0.028769
0.415003
0.733303
-0.370460
-0.020052
2
1.054700
0.731401
0.225194
0.504820
-0.687442
0.540102
3
0.359936
0.349238
0.593094
1.194669
-0.439526
0.480990
4
1.687358
-2.190891
0.231224
0.628663
-1.310662
1.701560
The baseline data are standardized because PC, GES, and DirectLiNGAM all work more cleanly when variables are on comparable scales.
For causal discovery, the result is a statement about recoverable structure under assumptions, not a free-standing proof of cause and effect.
Baseline Data Audit
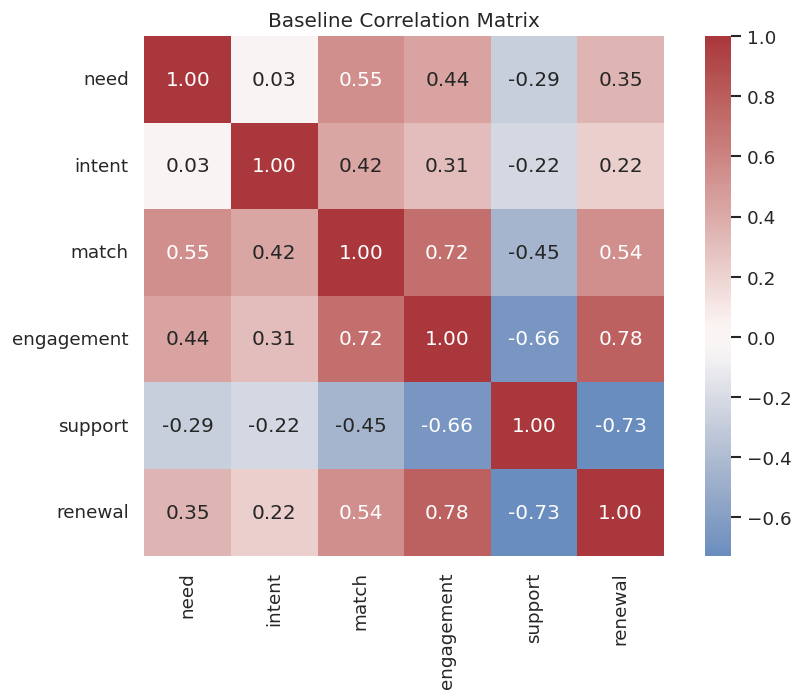
Before benchmarking algorithms, check the basic shape and correlation structure of the baseline data.
The correlation matrix shows strong relationships along the graph paths, but correlation alone cannot decide which adjacencies are direct or which way arrows point.
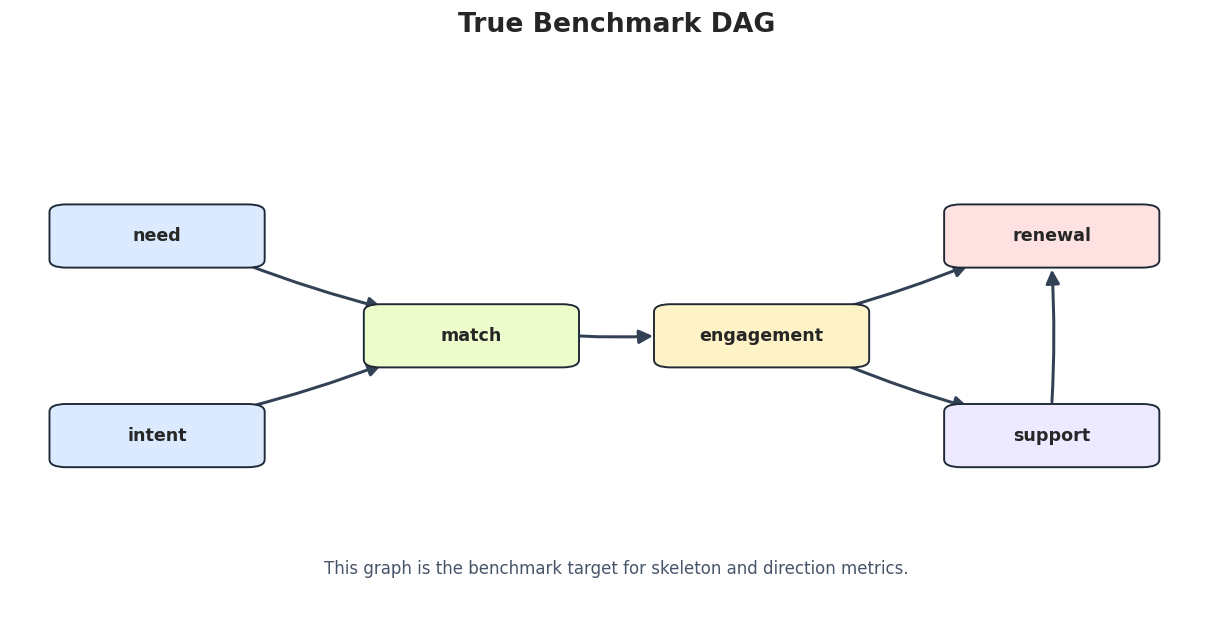
Draw the True DAG
The figure below is the benchmark target. The same box-and-arrow style is used across the tutorial series to keep graph outputs readable.
# Define reusable helpers for the Draw The True DAG section.def trim_edge_to_box(start, end, box_w=0.15, box_h=0.085, gap=0.012):""" Idea: Trim an arrow segment so graph edges stop at the border of each plotted node. Parameters ---------- start : tuple[float, float] Starting coordinate for a plotted element. end : tuple[float, float] Ending coordinate for a plotted element. box_w : object Width of the plotted node box. box_h : object Height of the plotted node box. gap : float Spacing used to keep plotted elements from overlapping. Returns ------- tuple[tuple[float, float], tuple[float, float]] Start and end coordinates trimmed so the edge stops at box boundaries. """ x0, y0 = start x1, y1 = end dx = x1 - x0 dy = y1 - y0 distance = (dx**2+ dy**2) **0.5if distance ==0:return start, end ux, uy = dx / distance, dy / distance candidates = []ifabs(ux) >1e-9: candidates.append((box_w /2) /abs(ux))ifabs(uy) >1e-9: candidates.append((box_h /2) /abs(uy)) offset =min(candidates) + gapreturn (x0 + ux * offset, y0 + uy * offset), (x1 - ux * offset, y1 - uy * offset)def draw_box_graph(edge_df, title, path, note=None):""" Idea: Render a small graph from an edge table using boxed nodes and visible arrows. Parameters ---------- edge_df : pd.DataFrame Graph edges or edge-level diagnostics to summarize. title : str Title shown on the resulting plot or report. path : str or pathlib.Path Input or output path. note : object Short annotation shown below or beside the plotted figure. Returns ------- None Draws the graph diagram directly on the Matplotlib axes and saves it when requested. """ positions = {"need": (0.12, 0.68),"intent": (0.12, 0.32),"match": (0.38, 0.50),"engagement": (0.62, 0.50),"support": (0.86, 0.32),"renewal": (0.86, 0.68), } colors = {"need": "#dbeafe","intent": "#dbeafe","match": "#ecfccb","engagement": "#fef3c7","support": "#ede9fe","renewal": "#fee2e2", } fig, ax = plt.subplots(figsize=(13, 6)) ax.set_axis_off() ax.set_xlim(0, 1) ax.set_ylim(0, 1)for row in edge_df.itertuples(index=False):if row.source notin positions or row.target notin positions:continue start, end = trim_edge_to_box(positions[row.source], positions[row.target]) edge_type = row.edge_type color ="#334155"if edge_type =="-->"else"#64748b" arrowstyle ="-|>"if edge_type =="-->"else"-" arrow = FancyArrowPatch( start, end, arrowstyle=arrowstyle, mutation_scale=17, linewidth=1.8, color=color, connectionstyle="arc3,rad=0.03", zorder=2, ) ax.add_patch(arrow)for variable, (x, y) in positions.items(): rect = FancyBboxPatch( (x -0.075, y -0.043),0.15,0.086, boxstyle="round,pad=0.014", facecolor=colors[variable], edgecolor="#1f2937", linewidth=1.15, zorder=4, ) ax.add_patch(rect) ax.text(x, y, variable, ha="center", va="center", fontsize=10.5, fontweight="bold", zorder=5)if note: ax.text(0.5, 0.08, note, ha="center", va="center", fontsize=10, color="#475569") ax.set_title(title, pad=16, fontsize=16, fontweight="bold") fig.savefig(path, dpi=160, bbox_inches="tight") plt.show()draw_box_graph( true_edge_table,"True Benchmark DAG", FIGURE_DIR /f"{NOTEBOOK_PREFIX}_true_benchmark_dag.png", note="This graph is the benchmark target for skeleton and direction metrics.",)
This DAG is simple, but it contains enough structure to test adjacency recovery, collider handling, and downstream parent selection.
For causal discovery, the result is a statement about recoverable structure under assumptions, not a free-standing proof of cause and effect.
Graph Parsing and Metrics
The next helpers standardize graph outputs from PC, GES, FCI, and DirectLiNGAM. We score two layers:
skeleton metrics: whether the correct variable pairs are adjacent;
directed metrics: whether directed arrows match the true direction.
Partially directed or undirected edges count for skeleton recovery but not for directed recovery.
# Define reusable helpers for the Graph Parsing And Metrics section.def parse_causallearn_edge(edge):""" Idea: Convert a causal-learn graph edge object into plain endpoint labels for tabular auditing. Parameters ---------- edge : object Single graph edge being parsed, drawn, or evaluated. Returns ------- tuple[str, str, str] Source node, endpoint mark, and target node parsed from a causal-learn edge. """ text =str(edge).strip() edge_tokens = [" --> ", " <-- ", " <-> ", " o-> ", " <-o ", " o-o ", " --- "]for token in edge_tokens:if token in text: left, right = text.split(token)if token ==" <-- ":return {"source": right.strip(), "edge_type": "-->", "target": left.strip()}if token ==" <-o ":return {"source": right.strip(), "edge_type": "o->", "target": left.strip()}return {"source": left.strip(), "edge_type": token.strip(), "target": right.strip()}raiseValueError(f"Could not parse edge: {text}")def graph_to_edge_table(graph, label):""" Idea: Convert a causal-learn graph object into a DataFrame of edge endpoints and method labels. Parameters ---------- graph : object Graph object returned by the causal discovery or causal modeling library. label : str Short label attached to a scenario, method, or plotted result. Returns ------- pd.DataFrame Edge table with source, target, edge mark, and method metadata. """ rows = [parse_causallearn_edge(edge) for edge in graph.get_graph_edges()] edge_table = pd.DataFrame(rows, columns=["source", "edge_type", "target"]) edge_table.insert(0, "run", label)return edge_tabledef lingam_to_edge_table(adjacency_matrix, label, threshold=0.12):""" Idea: Convert a LiNGAM adjacency matrix into a directed edge table using a coefficient threshold. Parameters ---------- adjacency_matrix : np.ndarray Matrix whose nonzero entries represent candidate directed edges. label : str Short label attached to a scenario, method, or plotted result. threshold : float Cutoff used to decide whether a signal or edge is retained. Returns ------- pd.DataFrame Directed edge table from LiNGAM coefficients above the threshold. """ rows = []for target in VARIABLES:for source in VARIABLES:if source == target:continue coefficient =float(adjacency_matrix[VAR_INDEX[target], VAR_INDEX[source]])ifabs(coefficient) >= threshold: rows.append( {"run": label,"source": source,"edge_type": "-->","target": target,"coefficient": coefficient,"abs_coefficient": abs(coefficient), } )return pd.DataFrame(rows, columns=["run", "source", "edge_type", "target", "coefficient", "abs_coefficient"])def skeleton_pairs(edge_df):""" Idea: Reduce an edge table to unordered node pairs so skeleton recovery can be evaluated. Parameters ---------- edge_df : pd.DataFrame Graph edges or edge-level diagnostics to summarize. Returns ------- set[tuple[str, str]] Unordered node pairs representing the learned graph skeleton. """if edge_df.empty:returnset()return {tuple(sorted((row.source, row.target))) for row in edge_df.itertuples(index=False)}def directed_pairs(edge_df):""" Idea: Extract directed edge pairs from an edge table so orientation recovery can be evaluated. Parameters ---------- edge_df : pd.DataFrame Graph edges or edge-level diagnostics to summarize. Returns ------- set[tuple[str, str]] Ordered source-target pairs representing directed learned edges. """if edge_df.empty:returnset()return {(row.source, row.target) for row in edge_df.itertuples(index=False) if row.edge_type =="-->"}TRUE_DIRECTED =set(TRUE_EDGES)TRUE_SKELETON = {tuple(sorted(edge)) for edge in TRUE_EDGES}def summarize_against_truth(edge_df, label, scenario="baseline"):""" Idea: Summarize the against truth into a compact table for interpretation in the Graph Parsing And Metrics section. Parameters ---------- edge_df : pd.DataFrame Graph edges or edge-level diagnostics to summarize. label : str Short label attached to a scenario, method, or plotted result. scenario : str Scenario label describing the data-generating or diagnostic condition. Returns ------- pd.DataFrame Graph-recovery summary table with edge counts, precision, recall, missing edges, and extra edges. """ learned_skeleton = skeleton_pairs(edge_df) learned_directed = directed_pairs(edge_df) skeleton_tp = learned_skeleton & TRUE_SKELETON skeleton_fp = learned_skeleton - TRUE_SKELETON skeleton_fn = TRUE_SKELETON - learned_skeleton directed_tp = learned_directed & TRUE_DIRECTED directed_fp = learned_directed - TRUE_DIRECTED directed_fn = TRUE_DIRECTED - learned_directed reversed_true_edges = {(target, source) for source, target in learned_directed} & TRUE_DIRECTED skeleton_precision =len(skeleton_tp) /len(learned_skeleton) if learned_skeleton else np.nan skeleton_recall =len(skeleton_tp) /len(TRUE_SKELETON) skeleton_f1 =2* skeleton_precision * skeleton_recall / (skeleton_precision + skeleton_recall) if skeleton_precision + skeleton_recall >0else np.nan directed_precision =len(directed_tp) /len(learned_directed) if learned_directed else np.nan directed_recall =len(directed_tp) /len(TRUE_DIRECTED) directed_f1 =2* directed_precision * directed_recall / (directed_precision + directed_recall) if directed_precision + directed_recall >0else np.nanreturn pd.DataFrame( [ {"scenario": scenario,"method": label,"reported_edges": len(edge_df),"skeleton_precision": skeleton_precision,"skeleton_recall": skeleton_recall,"skeleton_f1": skeleton_f1,"directed_precision": directed_precision,"directed_recall": directed_recall,"directed_f1": directed_f1,"extra_adjacencies": len(skeleton_fp),"missed_adjacencies": len(skeleton_fn),"reversed_true_edges": len(reversed_true_edges),"extra_adjacency_list": " | ".join(f"{a}--{b}"for a, b insorted(skeleton_fp)),"missed_adjacency_list": " | ".join(f"{a}--{b}"for a, b insorted(skeleton_fn)), } ] )
The metric functions make the benchmark transparent. A partially directed PC or GES graph can still score well on skeleton recovery while receiving lower directed recall.
Algorithm Runners
The code below wraps PC, GES, FCI, and DirectLiNGAM so later benchmark grids can call them consistently. We keep the defaults conservative and expose the main tuning knobs.
# Define reusable helpers for the Algorithm Runners section.def run_pc(data_df, alpha=0.01, label="PC_FisherZ"):""" Idea: Run the PC algorithm for a selected dataset and return recovered edges or diagnostics. Parameters ---------- data_df : pd.DataFrame Rows for the current simulated or observed experiment. alpha : float Significance level, transparency value, or tuning parameter used by the diagnostic. label : str Short label attached to a scenario, method, or plotted result. Returns ------- pd.DataFrame or tuple PC recovery output for the requested dataset and alpha setting. """ start = time.perf_counter() result = pc( data_df.to_numpy(), alpha=alpha, indep_test="fisherz", stable=True, show_progress=False, node_names=VARIABLES, ) elapsed = time.perf_counter() - startreturn graph_to_edge_table(result.G, label), elapseddef run_ges(data_df, lambda_value=1.0, label="GES_BIC"):""" Idea: Run GES under the requested score or penalty setting and return recovered graph information. Parameters ---------- data_df : pd.DataFrame Rows for the current simulated or observed experiment. lambda_value : float Penalty value used by score-based search or a learner. label : str Short label attached to a scenario, method, or plotted result. Returns ------- pd.DataFrame or tuple GES recovery output for the requested dataset and penalty setting. """ start = time.perf_counter() record = ges( data_df.to_numpy(), score_func="local_score_BIC_from_cov", node_names=VARIABLES, parameters={"lambda_value": lambda_value}, ) elapsed = time.perf_counter() - startreturn graph_to_edge_table(record["G"], label), elapseddef run_direct_lingam(data_df, threshold=0.12, label="DirectLiNGAM"):""" Idea: Run DirectLiNGAM and convert the learned adjacency matrix into an edge table. Parameters ---------- data_df : pd.DataFrame Rows for the current simulated or observed experiment. threshold : float Cutoff used to decide whether a signal or edge is retained. label : str Short label attached to a scenario, method, or plotted result. Returns ------- pd.DataFrame Directed edge table recovered by DirectLiNGAM. """ start = time.perf_counter() model = DirectLiNGAM(random_state=RANDOM_SEED) model.fit(data_df.to_numpy()) elapsed = time.perf_counter() - start edge_table = lingam_to_edge_table(model.adjacency_matrix_, label=label, threshold=threshold)return edge_table, elapsed, modeldef run_fci(data_df, alpha=0.01, label="FCI_FisherZ"):""" Idea: Run the FCI algorithm for a selected dataset and return recovered edges or diagnostics. Parameters ---------- data_df : pd.DataFrame Rows for the current simulated or observed experiment. alpha : float Significance level, transparency value, or tuning parameter used by the diagnostic. label : str Short label attached to a scenario, method, or plotted result. Returns ------- pd.DataFrame or tuple FCI recovery output for the requested dataset and alpha setting. """ start = time.perf_counter() graph, _ = fci( data_df.to_numpy(), independence_test_method="fisherz", alpha=alpha, show_progress=False, node_names=VARIABLES, ) elapsed = time.perf_counter() - startreturn graph_to_edge_table(graph, label), elapseddef run_benchmark_methods(data_df, scenario="baseline", pc_alpha=0.01, ges_lambda=1.0, lingam_threshold=0.12):""" Idea: Run the chosen discovery methods on a benchmark dataset and collect comparable recovery metrics. Parameters ---------- data_df : pd.DataFrame Rows for the current simulated or observed experiment. scenario : str Scenario label describing the data-generating or diagnostic condition. pc_alpha : object Context-specific input used for PC alpha in this helper. ges_lambda : object Context-specific input used for GES lambda in this helper. lingam_threshold : object Context-specific input used for LiNGAM threshold in this helper. Returns ------- pd.DataFrame Benchmark table collecting graph-recovery metrics across methods. """ rows = [] edges = [] pc_edges, pc_elapsed = run_pc(data_df, alpha=pc_alpha, label="PC_FisherZ") rows.append(summarize_against_truth(pc_edges, "PC_FisherZ", scenario).assign(elapsed_seconds=pc_elapsed)) edges.append(pc_edges.assign(scenario=scenario, elapsed_seconds=pc_elapsed)) ges_edges, ges_elapsed = run_ges(data_df, lambda_value=ges_lambda, label="GES_BIC") rows.append(summarize_against_truth(ges_edges, "GES_BIC", scenario).assign(elapsed_seconds=ges_elapsed)) edges.append(ges_edges.assign(scenario=scenario, elapsed_seconds=ges_elapsed)) lingam_edges, lingam_elapsed, _ = run_direct_lingam(data_df, threshold=lingam_threshold, label="DirectLiNGAM") rows.append(summarize_against_truth(lingam_edges, "DirectLiNGAM", scenario).assign(elapsed_seconds=lingam_elapsed)) edges.append(lingam_edges.assign(scenario=scenario, elapsed_seconds=lingam_elapsed))return pd.concat(rows, ignore_index=True), pd.concat(edges, ignore_index=True)
These wrappers are small. They avoid hidden defaults in the benchmark loops and make each algorithm’s tuning parameters visible.
Baseline Algorithm Comparison
Now we run PC, GES, and DirectLiNGAM on the same baseline data. This is the cleanest comparison because the data are linear, acyclic, causally sufficient, and non-Gaussian.
The baseline is deliberately friendly to all three methods. PC and GES usually recover the correct skeleton and many directions; DirectLiNGAM can recover all directions because the data match its linear non-Gaussian assumptions.
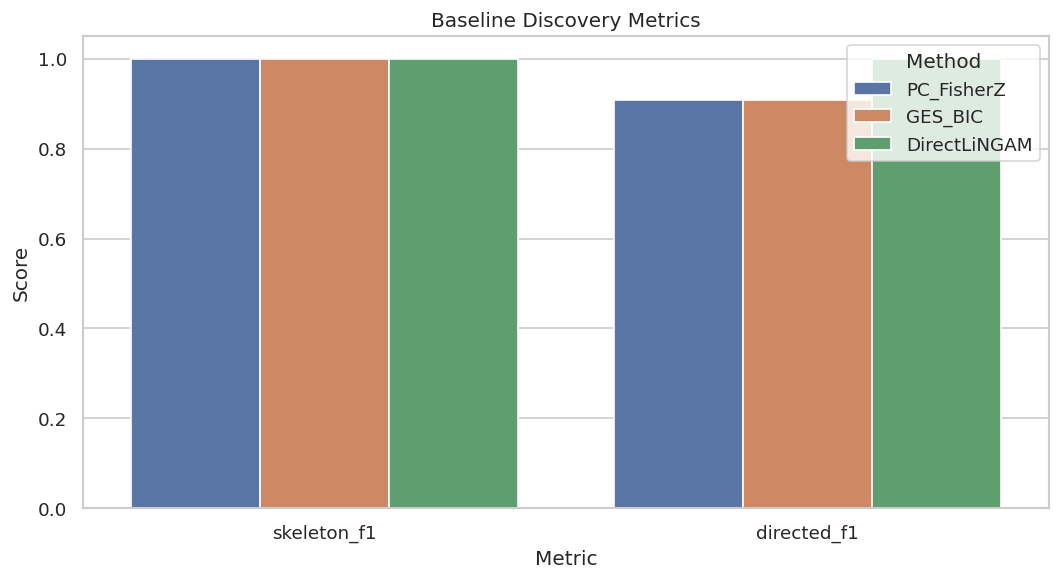
Plot Baseline Metrics
A compact metric plot lets us see the skeleton-versus-direction distinction immediately.
The plot shows why benchmark reports should use more than one number. Recovering adjacencies and orienting arrows are related but different tasks.
That makes the comparison interpretable because differences across methods can be tied to estimator behavior while preprocessing and evaluation stay fixed.
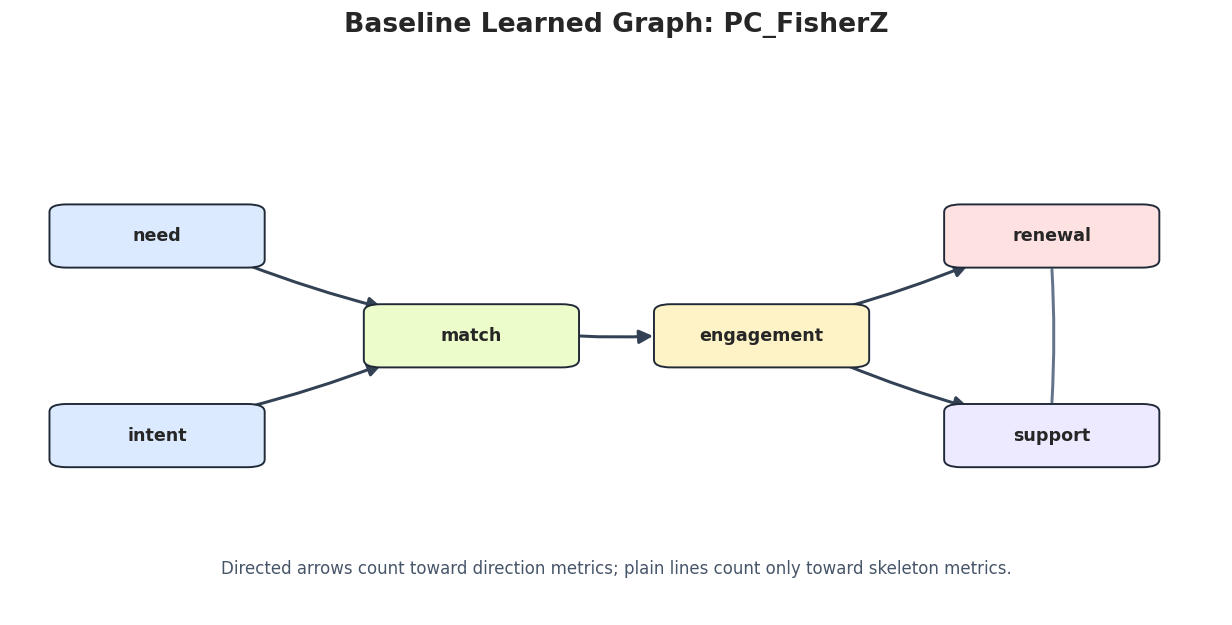
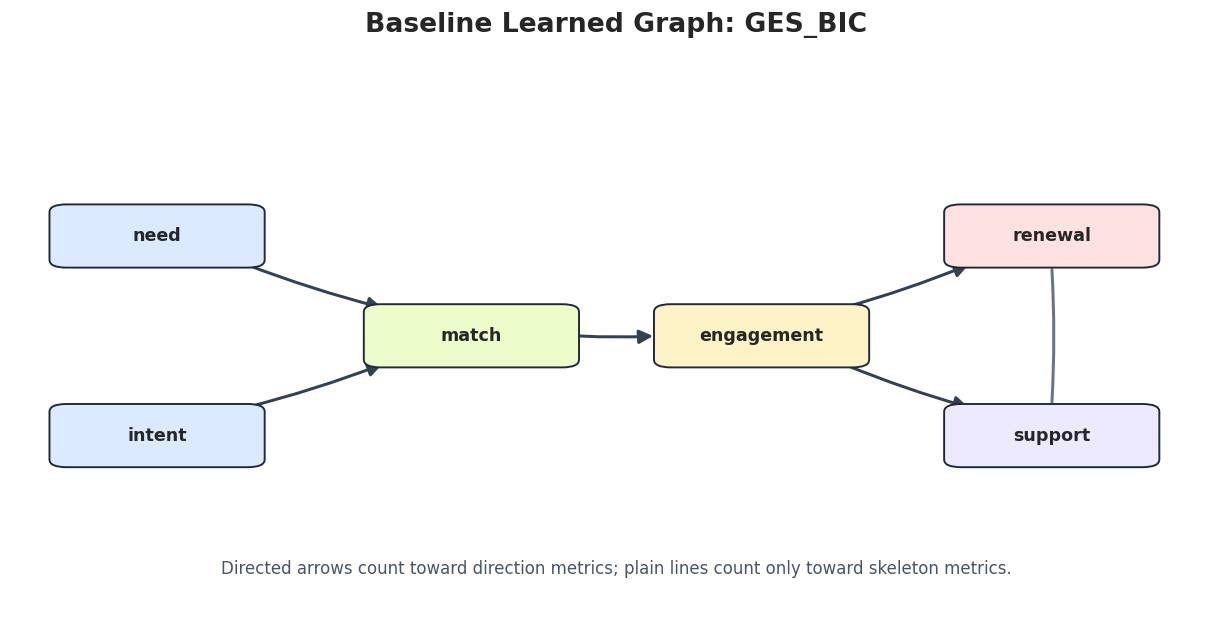
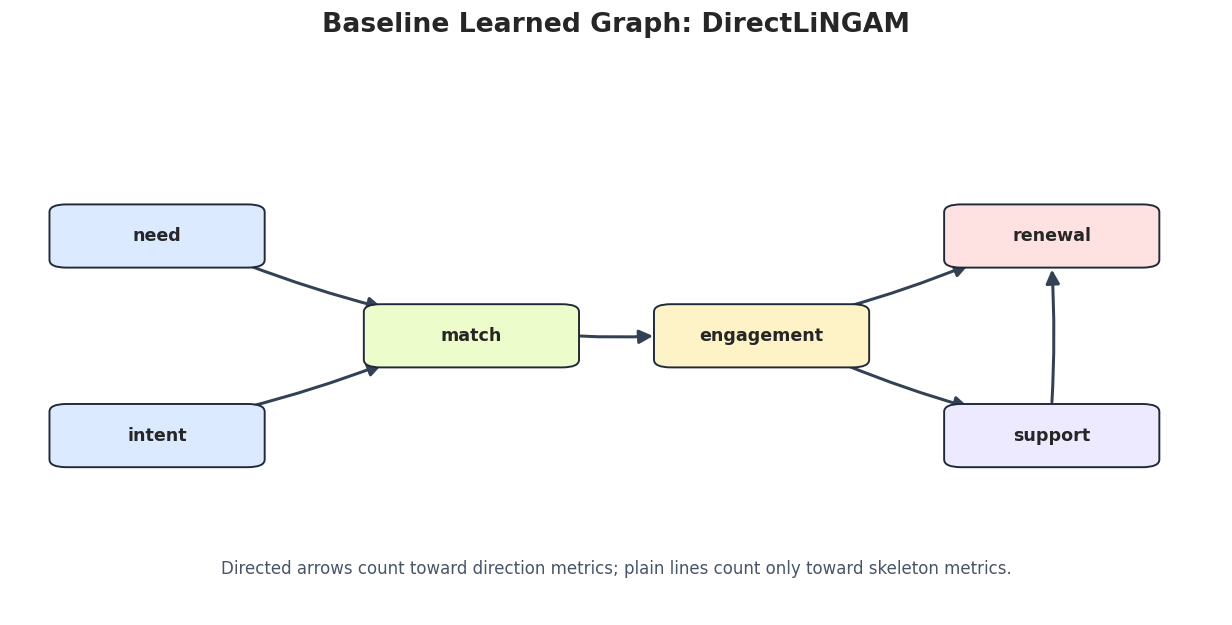
Draw Baseline Learned Graphs
The next step saves one graph image per method. Undirected or partially oriented edges are drawn as plain lines so they are not mistaken for confirmed arrow directions.
for method_name in baseline_edges["run"].unique(): method_edges = baseline_edges[baseline_edges["run"] == method_name].copy() draw_box_graph( method_edges,f"Baseline Learned Graph: {method_name}", FIGURE_DIR /f"{NOTEBOOK_PREFIX}_baseline_{method_name.lower()}_graph.png", note="Directed arrows count toward direction metrics; plain lines count only toward skeleton metrics.", )
These plots are useful for qualitative review. The metric table tells us what changed; the graph drawings make the change easier to inspect.
For causal discovery, the result is a statement about recoverable structure under assumptions, not a free-standing proof of cause and effect.
Sample-Size and Seed Stability
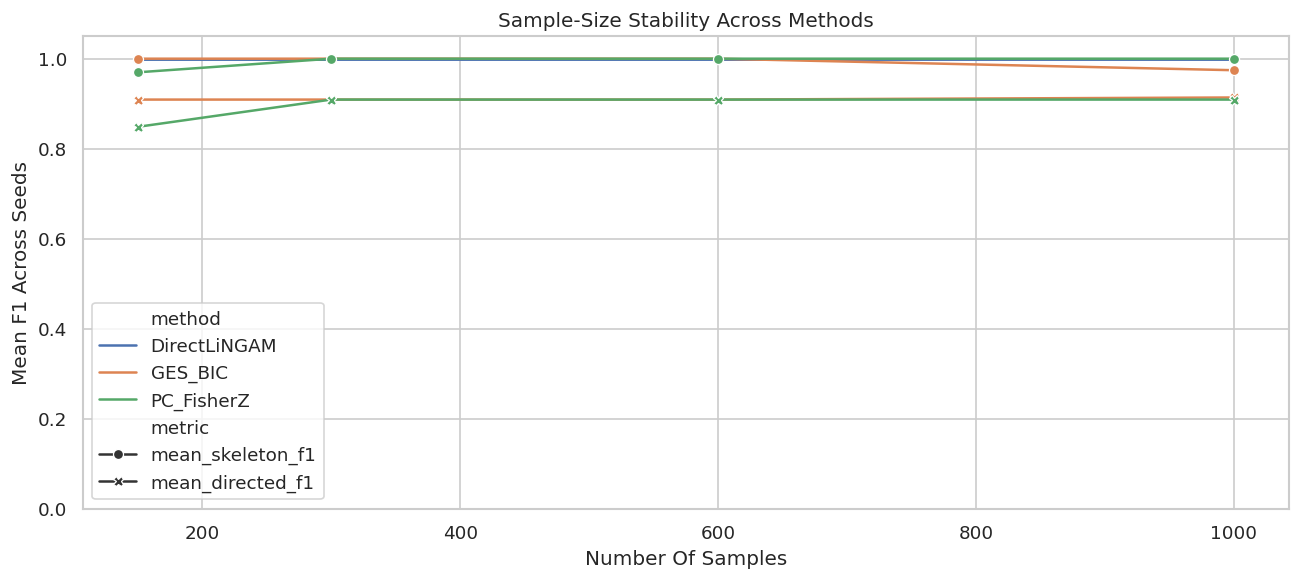
A stable discovery method should not depend on one lucky sample. This grid varies sample size and random seed, then reruns all three benchmark methods.
The summary shows how recovery improves as the sample grows. Small samples can preserve the rough skeleton while making directions less reliable.
The later estimates should be read in light of this sample construction, since data quality and composition set the boundary for any causal claim.
Plot Sample-Size Stability
The line plot uses the mean F1 scores across seeds for each sample size.
sample_plot = sample_seed_summary.melt( id_vars=["method", "n_samples"], value_vars=["mean_skeleton_f1", "mean_directed_f1"], var_name="metric", value_name="score",)fig, ax = plt.subplots(figsize=(11, 5))sns.lineplot(data=sample_plot, x="n_samples", y="score", hue="method", style="metric", markers=True, dashes=False, ax=ax)ax.set_title("Sample-Size Stability Across Methods")ax.set_xlabel("Number Of Samples")ax.set_ylabel("Mean F1 Across Seeds")ax.set_ylim(0, 1.05)plt.tight_layout()fig.savefig(FIGURE_DIR /f"{NOTEBOOK_PREFIX}_sample_size_stability.png", dpi=160, bbox_inches="tight")plt.show()
The plot makes the practical sample-size story visible. If the directed score is unstable at small n, a report should avoid strong directional claims from that region.
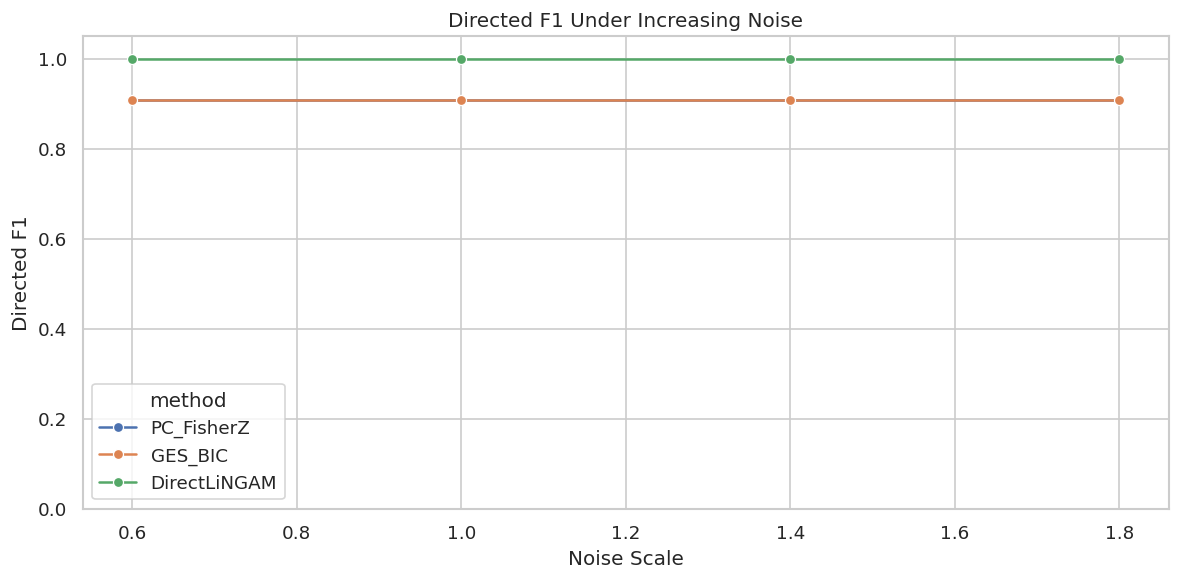
Noise Sensitivity
Next we hold sample size fixed and vary the measurement noise scale. Higher noise weakens the signal-to-noise ratio and can make direct adjacencies harder to recover.
Noise sensitivity is a useful robustness check because real datasets rarely have the clean signal strength used in synthetic demos.
The later estimates should be read in light of this sample construction, since data quality and composition set the boundary for any causal claim.
Plot Noise Sensitivity
The next figure tracks directed F1 as noise increases. Skeleton scores are saved in the table above; the directed score is usually the more fragile layer.
fig, ax = plt.subplots(figsize=(10, 5))sns.lineplot(data=noise_sensitivity, x="noise_scale", y="directed_f1", hue="method", marker="o", ax=ax)ax.set_title("Directed F1 Under Increasing Noise")ax.set_xlabel("Noise Scale")ax.set_ylabel("Directed F1")ax.set_ylim(0, 1.05)plt.tight_layout()fig.savefig(FIGURE_DIR /f"{NOTEBOOK_PREFIX}_noise_sensitivity.png", dpi=160, bbox_inches="tight")plt.show()
If a method’s directed score drops sharply as noise increases, its arrow claims should be reported with caution in low-signal applications.
For causal discovery, the result is a statement about recoverable structure under assumptions, not a free-standing proof of cause and effect.
Tuning Sensitivity: PC Alpha
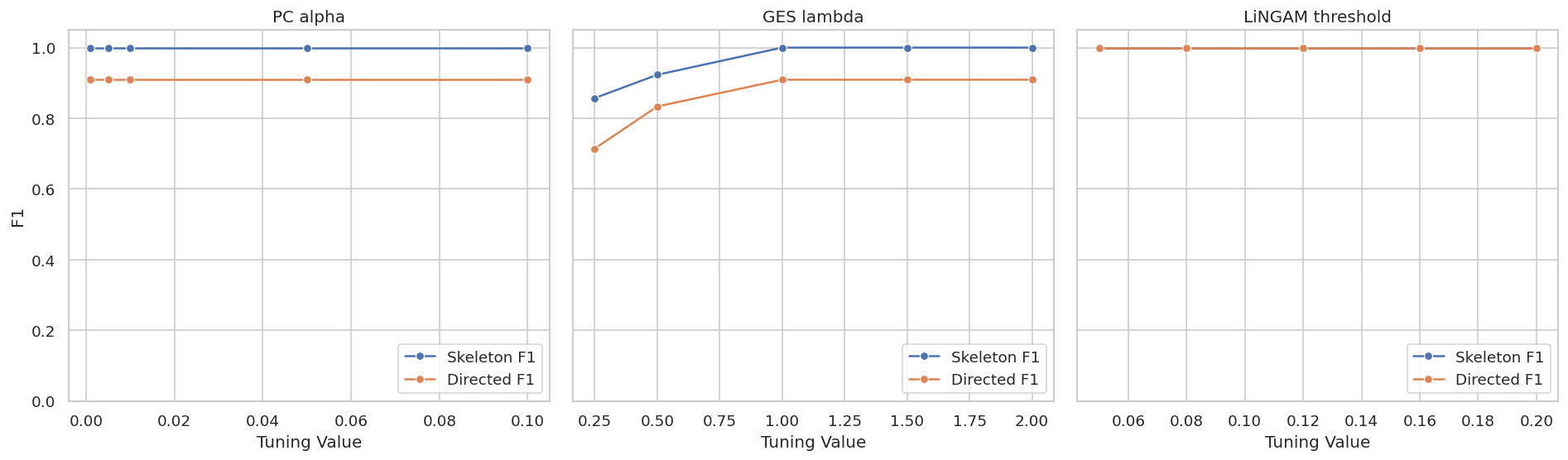
PC depends on a conditional-independence significance level. Larger alpha values tend to remove fewer edges, while smaller values tend to remove more edges. The right value is data-dependent, so it should be scanned and reported.
The PC alpha scan shows whether the learned graph is stable across reasonable independence-test thresholds.
For causal discovery, the result is a statement about recoverable structure under assumptions, not a free-standing proof of cause and effect.
Tuning Sensitivity: GES Penalty
GES uses a score penalty. Larger penalties favor simpler graphs. Smaller penalties can admit extra edges. We scan the penalty multiplier used by the local BIC score.
The GES penalty scan makes the sparsity tradeoff explicit. A benchmark should say which penalty produced the reported graph.
That makes the comparison interpretable because differences across methods can be tied to estimator behavior while preprocessing and evaluation stay fixed.
DirectLiNGAM returns a weighted adjacency matrix. To report a graph, we need a coefficient threshold. The code below fits DirectLiNGAM once and scans several thresholds.
The threshold scan is a reminder that weighted-output algorithms still require a reporting rule. A low threshold can over-report weak edges; a high threshold can drop true but weaker effects.
Plot Tuning Sensitivity
This plot puts the main tuning scans on one page. Each panel uses the method-specific tuning parameter, so read the x-axis labels separately.
Stable regions are more reassuring than isolated peaks. In an applied report, a graph chosen from a narrow peak should be described as sensitive to tuning.
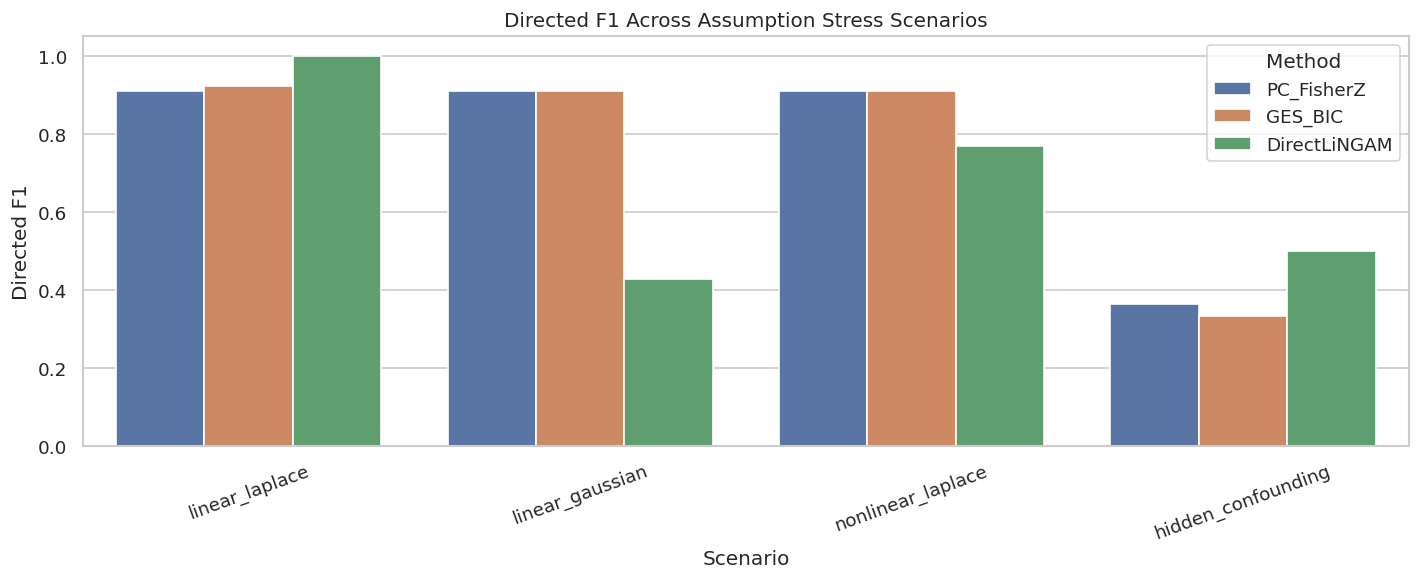
Assumption Stress Scenarios
The baseline was friendly. Now we deliberately perturb the assumptions:
linear_laplace: baseline linear non-Gaussian data;
linear_gaussian: directions are harder for LiNGAM because non-Gaussianity is removed;
nonlinear_laplace: linear algorithms are misspecified;
hidden_confounding: causal sufficiency is violated by an unobserved common cause.
The hidden-confounding scores are not a fair observed-DAG target; they are included to show how observed-DAG methods can become unstable when a key assumption fails.
The stress table shows which failures are algorithm-specific and which are assumption-level. Gaussian noise mainly weakens DirectLiNGAM direction recovery; hidden confounding can create extra adjacencies or misleading directions for observed-DAG methods.
Plot Assumption Stress Results
The next figure compares directed F1 across the stress scenarios. Skeleton details are saved in the table above.
fig, ax = plt.subplots(figsize=(12, 5))sns.barplot(data=stress_metrics, x="scenario", y="directed_f1", hue="method", ax=ax)ax.set_title("Directed F1 Across Assumption Stress Scenarios")ax.set_xlabel("Scenario")ax.set_ylabel("Directed F1")ax.set_ylim(0, 1.05)ax.tick_params(axis="x", rotation=20)ax.legend(title="Method")plt.tight_layout()fig.savefig(FIGURE_DIR /f"{NOTEBOOK_PREFIX}_assumption_stress_directed_f1.png", dpi=160, bbox_inches="tight")plt.show()
The plot turns the warning into something visible. A method that performs beautifully under one data-generating regime can become much less reliable under another.
Targeted Hidden-Confounding Check with FCI
FCI is designed for settings where hidden common causes may exist. The code below runs FCI only on the hidden-confounding scenario. Since the target graph type is different from the observed DAG, we inspect whether the output marks possible hidden structure.
FCI uses endpoint marks that should be read differently from a DAG. Bidirected or partially marked edges are signs that hidden structure may be involved, not ordinary directed arrows from the observed DAG benchmark.
Edge Stability Signatures
Stability can also be summarized by graph signatures. The next step counts how many unique graphs each method produced across the sample-size and seed grid.
# Define reusable helpers for the Edge Stability Signatures section.def edge_signature(edge_df):""" Idea: Create a stable text signature for a graph edge so edge sets can be compared. Parameters ---------- edge_df : pd.DataFrame Graph edges or edge-level diagnostics to summarize. Returns ------- str Stable text signature for the set of learned graph edges. """if edge_df.empty:return"empty"return" | ".join(sorted(f"{row.source}{row.edge_type}{row.target}"for row in edge_df.itertuples(index=False)))signature_rows = []for (method, n_samples, seed), group in sample_seed_edges.groupby(["run", "n_samples", "seed"]): signature_rows.append( {"method": method,"n_samples": n_samples,"seed": seed,"edge_signature": edge_signature(group),"reported_edges": len(group), } )signature_table = pd.DataFrame(signature_rows)signature_summary = signature_table.groupby(["method", "n_samples"], as_index=False).agg( unique_graphs=("edge_signature", "nunique"), min_reported_edges=("reported_edges", "min"), max_reported_edges=("reported_edges", "max"),)signature_table.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_edge_signatures.csv", index=False)signature_summary.to_csv(TABLE_DIR /f"{NOTEBOOK_PREFIX}_edge_signature_summary.csv", index=False)display(signature_summary)
method
n_samples
unique_graphs
min_reported_edges
max_reported_edges
0
DirectLiNGAM
150
1
6
6
1
DirectLiNGAM
300
1
6
6
2
DirectLiNGAM
600
1
6
6
3
DirectLiNGAM
1000
1
6
6
4
GES_BIC
150
1
6
6
5
GES_BIC
300
1
6
6
6
GES_BIC
600
1
6
6
7
GES_BIC
1000
2
6
7
8
PC_FisherZ
150
2
5
6
9
PC_FisherZ
300
1
6
6
10
PC_FisherZ
600
1
6
6
11
PC_FisherZ
1000
1
6
6
Unique graph counts help distinguish stable metrics from stable graphs. Two graphs can have the same F1 score but disagree about which specific edge changed.
Reporting and Takeaways
Runtime Summary
Runtime is part of method selection. A method that is statistically attractive but too slow for repeated sensitivity checks may be hard to use responsibly on a larger graph.
The runtime table is small here because the graph has only six variables. On wider graphs, runtime and stability checks become a much bigger part of practical method choice.
Benchmark Reporting Checklist
A benchmark should make its assumptions and fragility visible. This checklist is a reusable template for reporting causal discovery comparisons.
item
what_to_report
why_it_matters
Graph target
Whether metrics target a DAG, CPDAG, PAG, skeleton, or weighted adjacency matrix.
Different algorithms return different graph objects and should not be collapsed casually.
Data-generating assumptions
Linearity, noise family, causal sufficiency, stationarity, and sample size.
Benchmark performance only applies to the assumptions actually tested.
Skeleton and direction metrics
Report adjacency recovery separately from arrow-direction recovery.
Partially directed graphs can have correct adjacencies but unresolved directions.
Tuning settings
PC alpha, GES penalty, coefficient threshold, and any prior knowledge used.
Graph output can change materially across tuning choices.
Stability checks
Seed, sample-size, noise, resampling, and graph-signature stability.
A single graph can hide high variance across plausible datasets.
Assumption stress tests
Nonlinearity, Gaussian noise, hidden confounding, missingness, or selection stress.
Failure modes are often more informative than the clean baseline result.
Claim strength
Whether learned edges are final claims, candidate hypotheses, or diagnostic signals.
Causal discovery rarely justifies strong claims without domain and design support.
The checklist is conservative. Good benchmarking does not make a graph automatically true; it makes the graph’s support and fragility easier to inspect.
Summary
The lesson leaves us with a practical benchmark pattern: start from a known graph, compare methods by graph layer, scan tuning settings, test stability, then stress the assumptions before making any causal claim from a discovered graph.