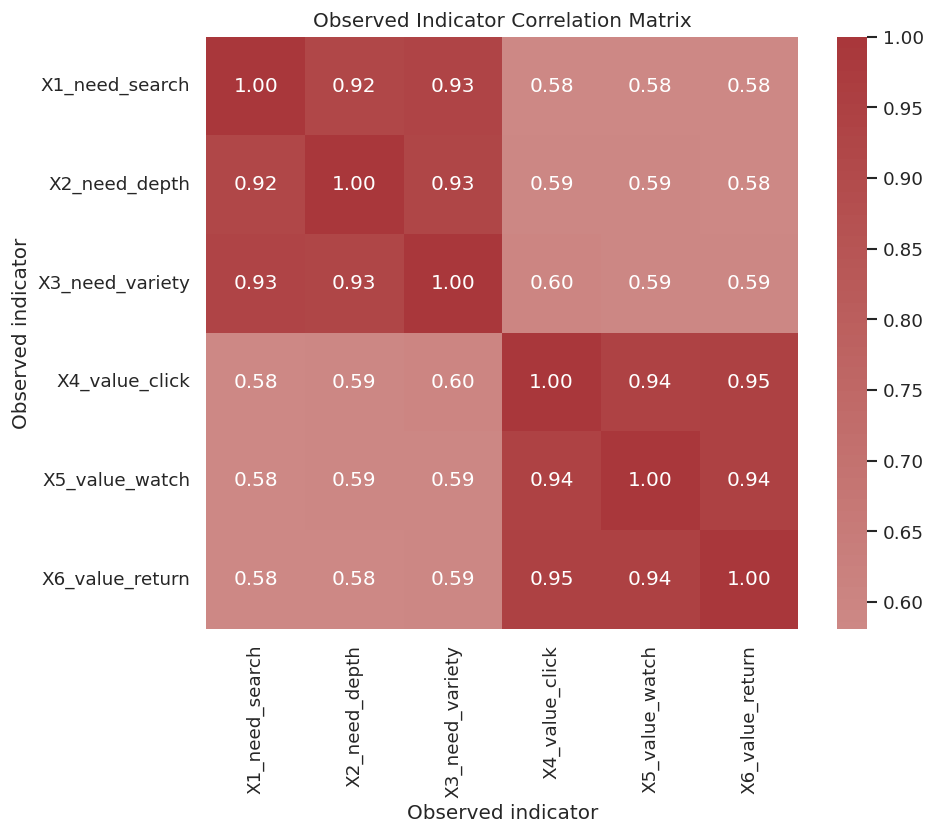
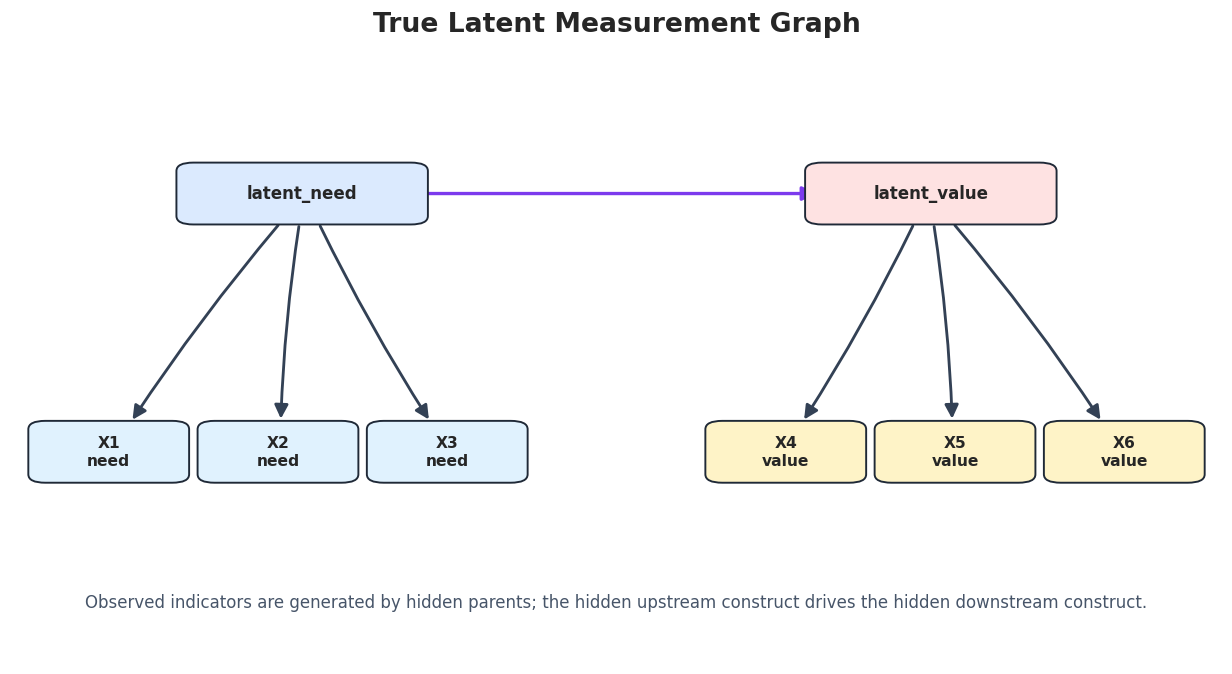
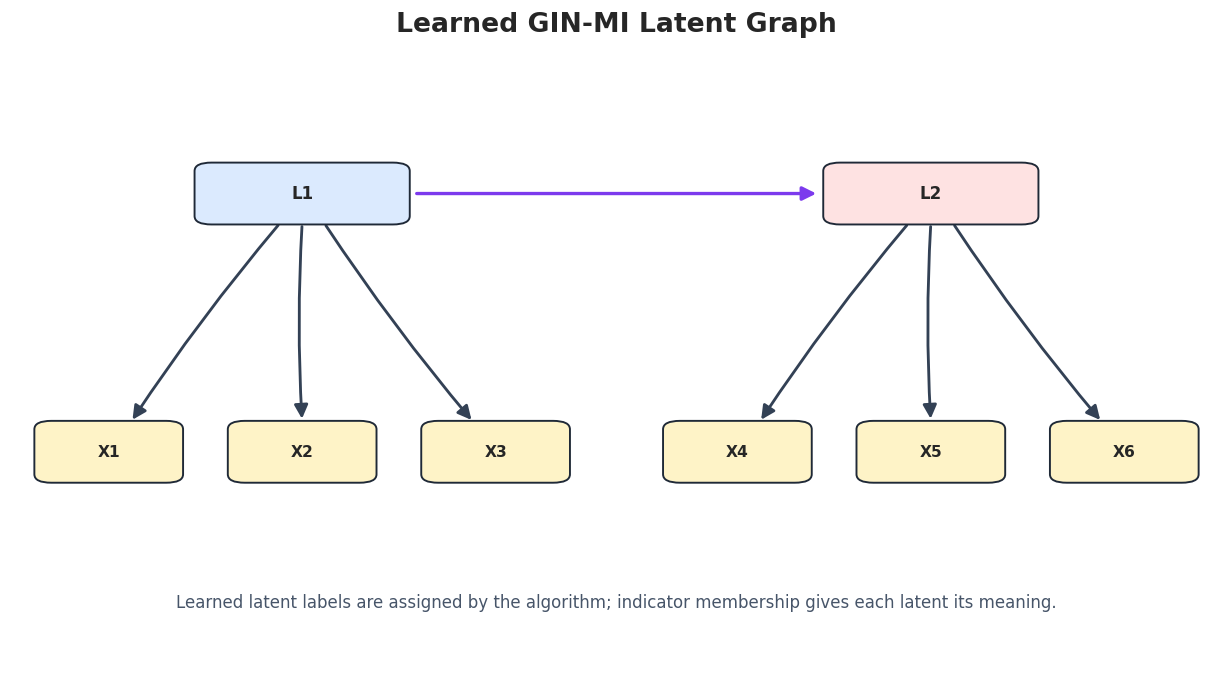
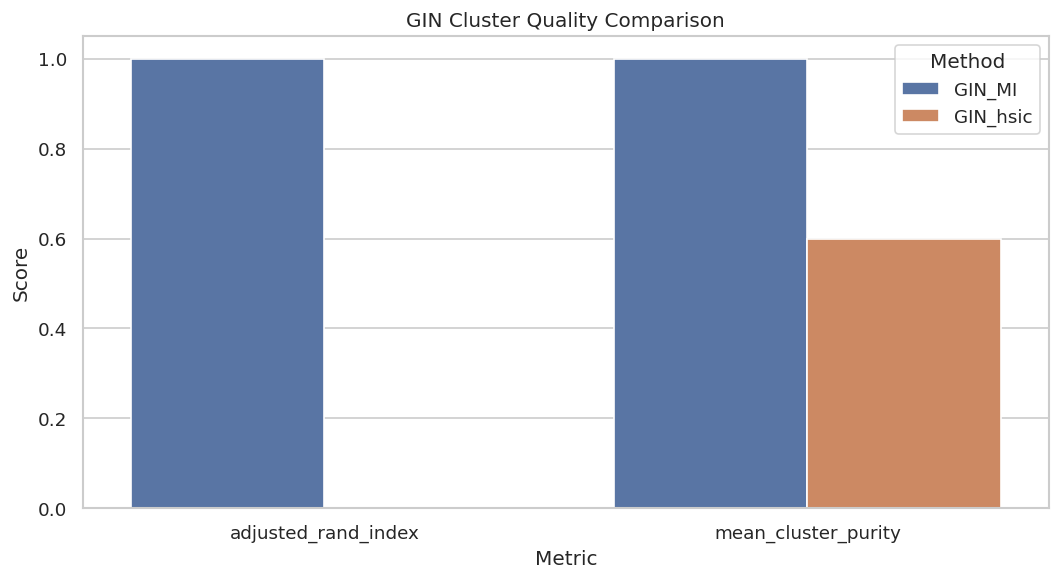
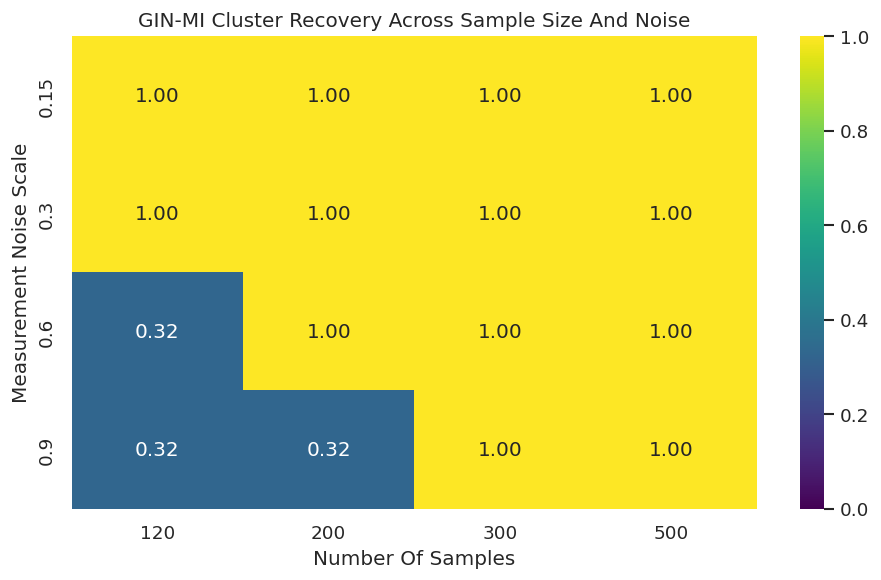
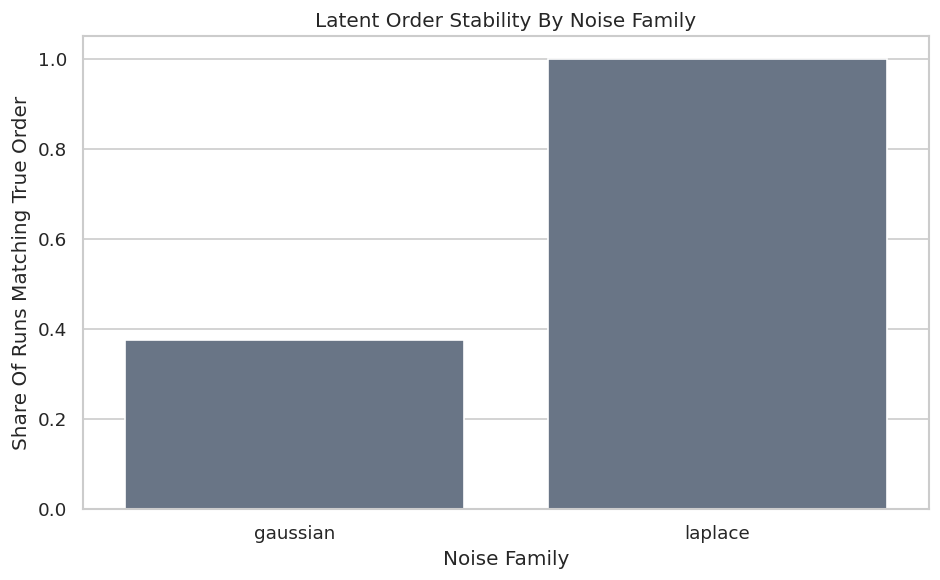
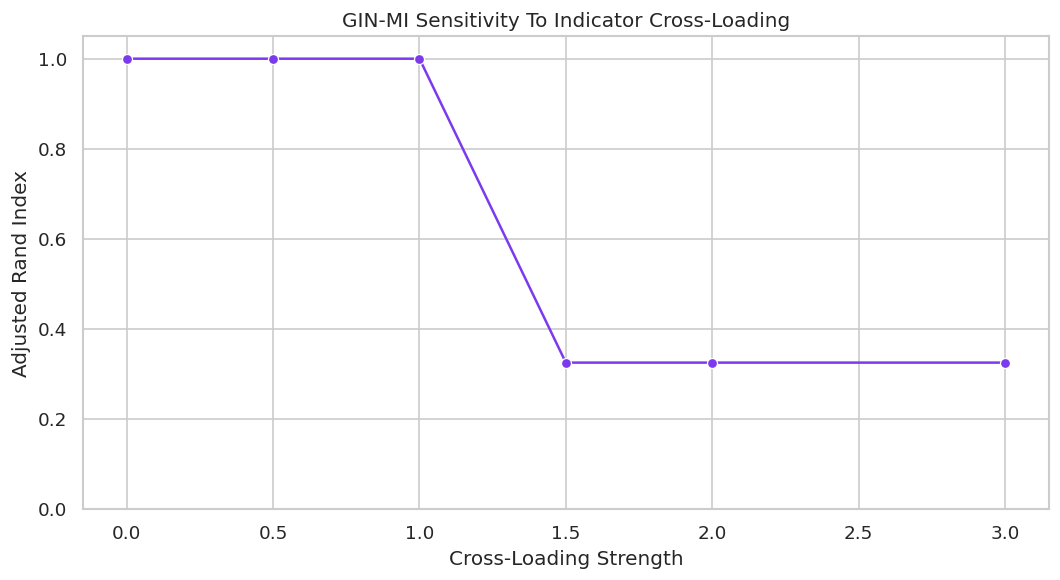
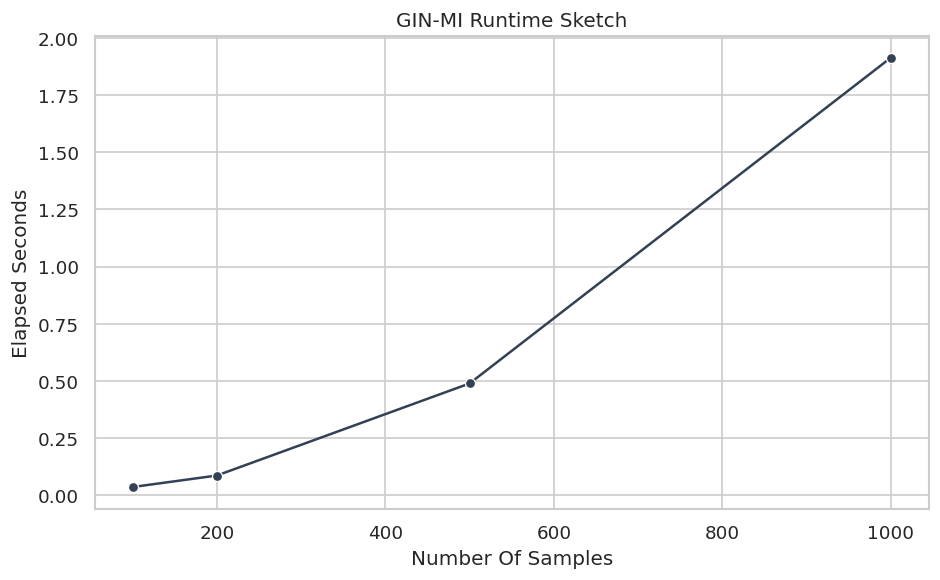
# Define reusable helpers for the Draw The True Latent Measurement Graph section.
def add_box(ax, xy, label, color, width=0.16, height=0.075, fontsize=10):
"""
Idea: Add a labeled node box to a Matplotlib flowchart or graph diagram.
Parameters
----------
ax : matplotlib.axes.Axes
Axes object that receives the drawing commands.
xy : object
Coordinate pair used to place a plotted node, label, or annotation.
label : str
Short label attached to a scenario, method, or plotted result.
color : str
Plot color used to identify this element.
width : float
Width used for a plotted box or simulated object.
height : float
Height used for a plotted box or simulated object.
fontsize : float
Font size used for a label in the plot.
Returns
-------
None
Adds a labeled node box directly to the supplied Matplotlib axes.
"""
x, y = xy
patch = FancyBboxPatch(
(x - width / 2, y - height / 2),
width,
height,
boxstyle="round,pad=0.014",
facecolor=color,
edgecolor="#1f2937",
linewidth=1.15,
zorder=4,
)
ax.add_patch(patch)
ax.text(x, y, label, ha="center", va="center", fontsize=fontsize, fontweight="bold", zorder=5)
def boundary_points(start, end, width=0.16, height=0.075, gap=0.012):
"""
Idea: Move arrow start and end points to the visible boundary of two boxes.
Parameters
----------
start : tuple[float, float]
Starting coordinate for a plotted element.
end : tuple[float, float]
Ending coordinate for a plotted element.
width : float
Width used for a plotted box or simulated object.
height : float
Height used for a plotted box or simulated object.
gap : float
Spacing used to keep plotted elements from overlapping.
Returns
-------
tuple[tuple[float, float], tuple[float, float]]
Adjusted start and end coordinates for an arrow between boxes.
"""
x0, y0 = start
x1, y1 = end
dx = x1 - x0
dy = y1 - y0
distance = (dx**2 + dy**2) ** 0.5
if distance == 0:
return start, end
ux, uy = dx / distance, dy / distance
candidates = []
if abs(ux) > 1e-9:
candidates.append((width / 2) / abs(ux))
if abs(uy) > 1e-9:
candidates.append((height / 2) / abs(uy))
offset = min(candidates) + gap
return (x0 + ux * offset, y0 + uy * offset), (x1 - ux * offset, y1 - uy * offset)
def add_arrow(ax, start, end, color="#334155", rad=0.0, lw=1.7):
"""
Idea: Add an arrow annotation to an existing Matplotlib axes.
Parameters
----------
ax : matplotlib.axes.Axes
Axes object that receives the drawing commands.
start : tuple[float, float]
Starting coordinate for a plotted element.
end : tuple[float, float]
Ending coordinate for a plotted element.
color : str
Plot color used to identify this element.
rad : float
Curvature parameter for the plotted arrow.
lw : float
Line width for the plotted arrow or edge.
Returns
-------
None
Adds an arrow annotation directly to the supplied Matplotlib axes.
"""
start_edge, end_edge = boundary_points(start, end)
arrow = FancyArrowPatch(
start_edge,
end_edge,
arrowstyle="-|>",
mutation_scale=17,
linewidth=lw,
color=color,
connectionstyle=f"arc3,rad={rad}",
zorder=2,
)
ax.add_patch(arrow)
def draw_true_measurement_graph(path):
"""
Idea: Draw the oracle latent-measurement graph used to check the GIN example.
Parameters
----------
path : str or pathlib.Path
Input or output path.
Returns
-------
None
Draws and saves the oracle latent-measurement graph.
"""
fig, ax = plt.subplots(figsize=(13, 6.5))
ax.set_axis_off()
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
positions = {
"latent_need": (0.24, 0.78),
"latent_value": (0.76, 0.78),
"X1": (0.08, 0.35),
"X2": (0.22, 0.35),
"X3": (0.36, 0.35),
"X4": (0.64, 0.35),
"X5": (0.78, 0.35),
"X6": (0.92, 0.35),
}
add_arrow(ax, positions["latent_need"], positions["latent_value"], color="#7c3aed", lw=2.0)
for label in ["X1", "X2", "X3"]:
add_arrow(ax, positions["latent_need"], positions[label], rad=0.03)
for label in ["X4", "X5", "X6"]:
add_arrow(ax, positions["latent_value"], positions[label], rad=-0.03)
add_box(ax, positions["latent_need"], "latent_need", "#dbeafe", width=0.18)
add_box(ax, positions["latent_value"], "latent_value", "#fee2e2", width=0.18)
for label in ["X1", "X2", "X3"]:
add_box(ax, positions[label], f"{label}\nneed", "#e0f2fe", width=0.105, fontsize=9.3)
for label in ["X4", "X5", "X6"]:
add_box(ax, positions[label], f"{label}\nvalue", "#fef3c7", width=0.105, fontsize=9.3)
ax.text(
0.5,
0.10,
"Observed indicators are generated by hidden parents; the hidden upstream construct drives the hidden downstream construct.",
ha="center",
va="center",
fontsize=10,
color="#475569",
)
ax.set_title("True Latent Measurement Graph", pad=18, fontsize=16, fontweight="bold")
fig.savefig(path, dpi=160, bbox_inches="tight")
plt.show()
draw_true_measurement_graph(FIGURE_DIR / f"{NOTEBOOK_PREFIX}_true_latent_measurement_graph.png")