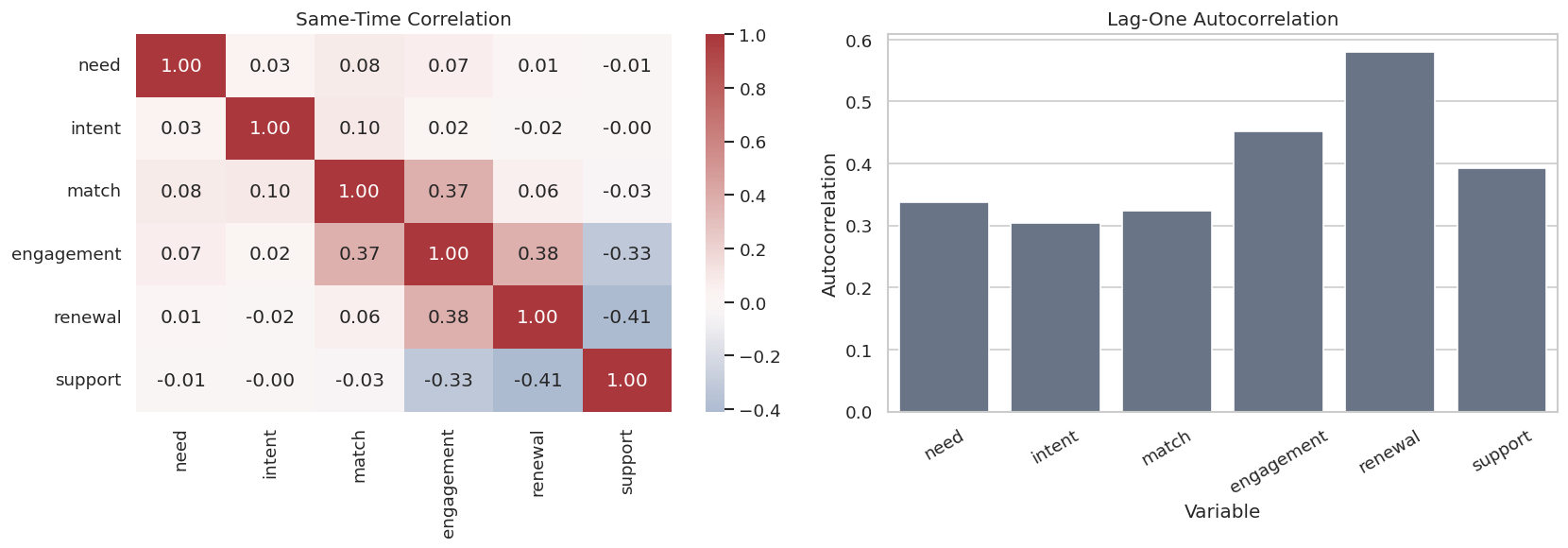
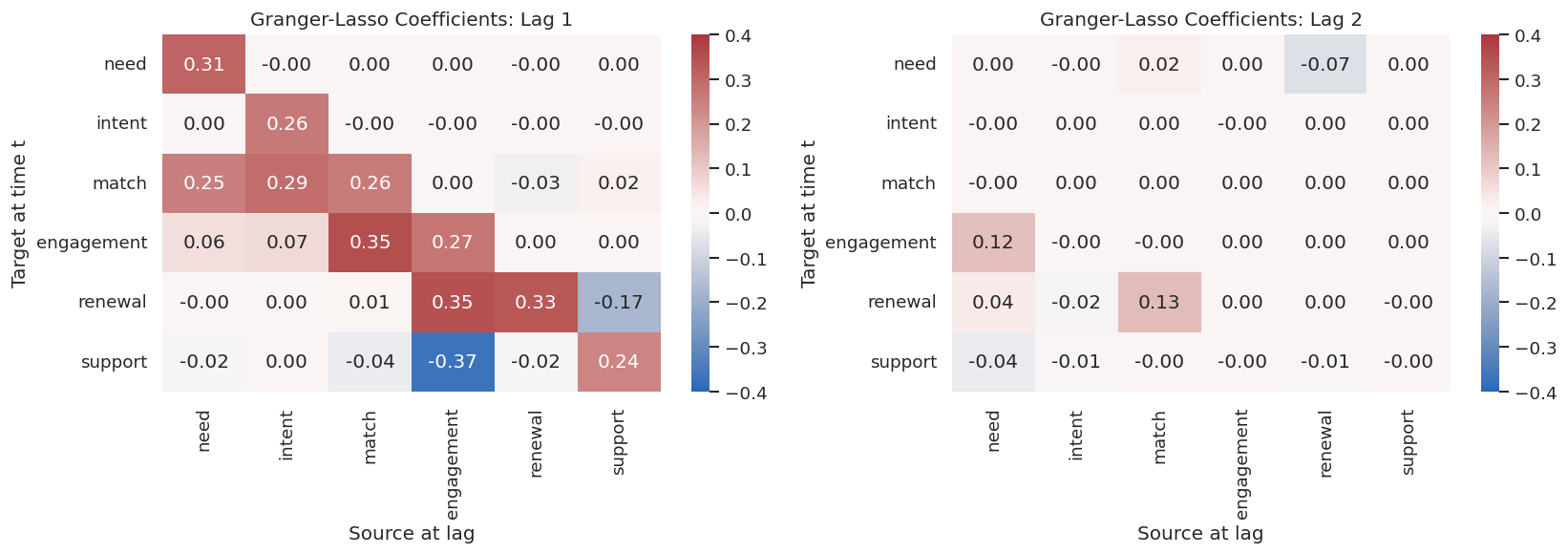
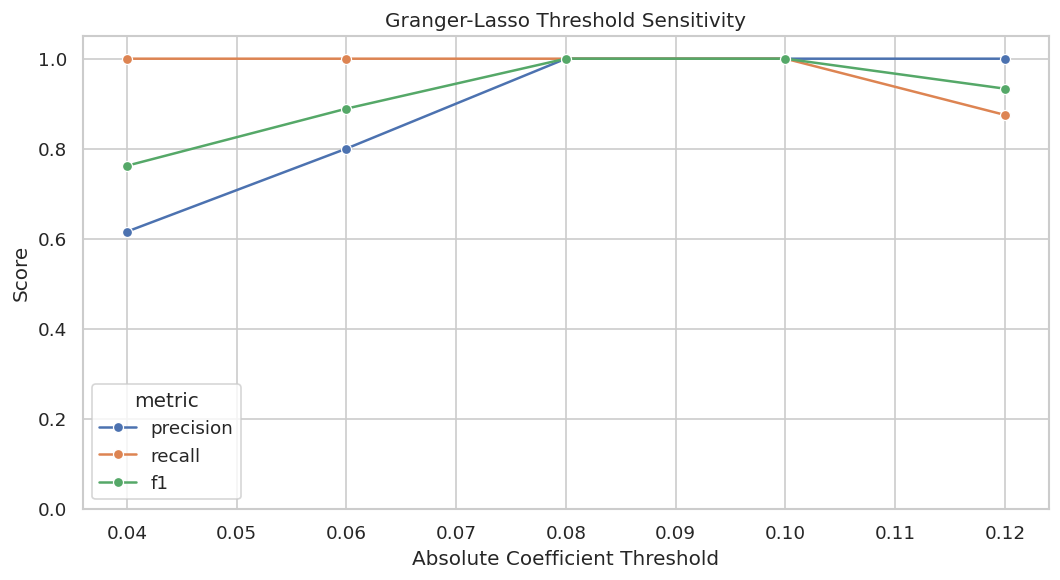
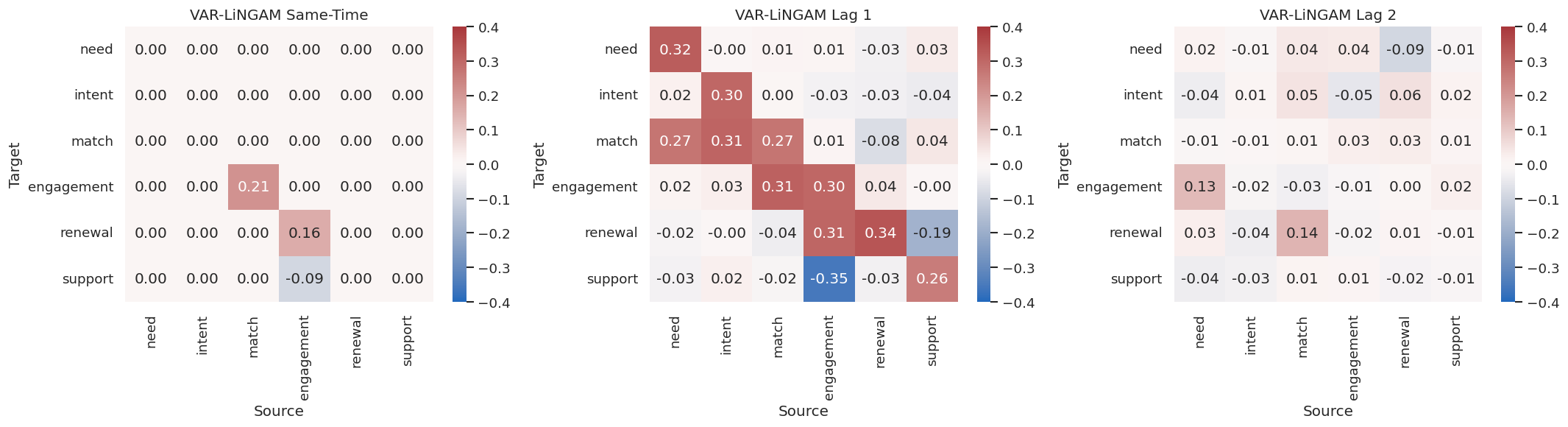
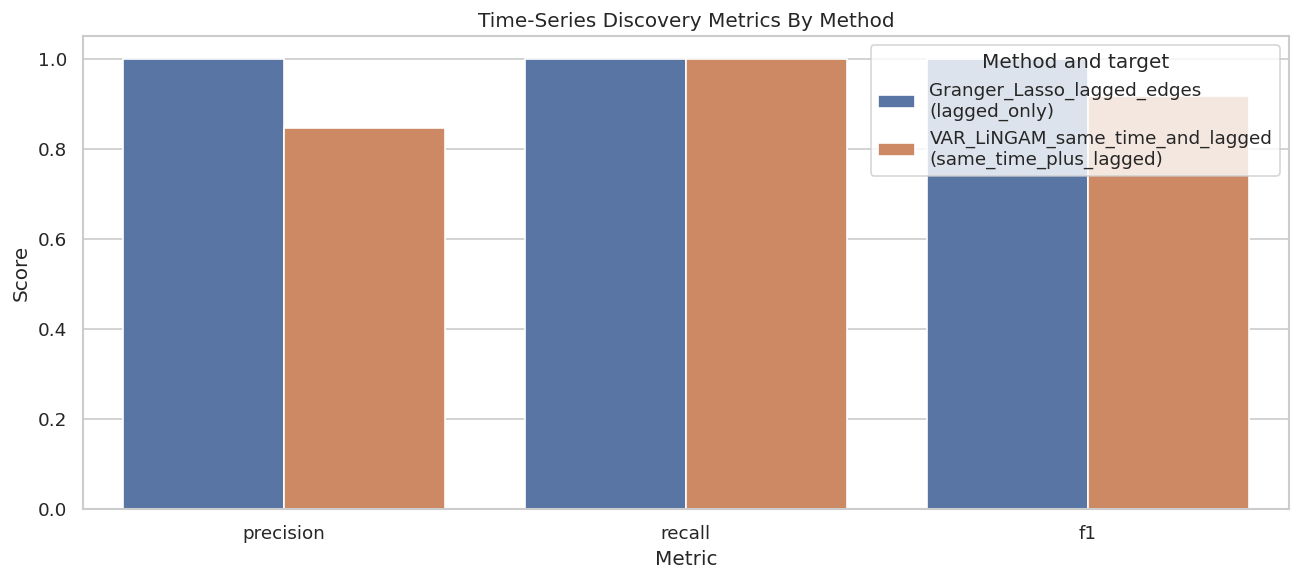
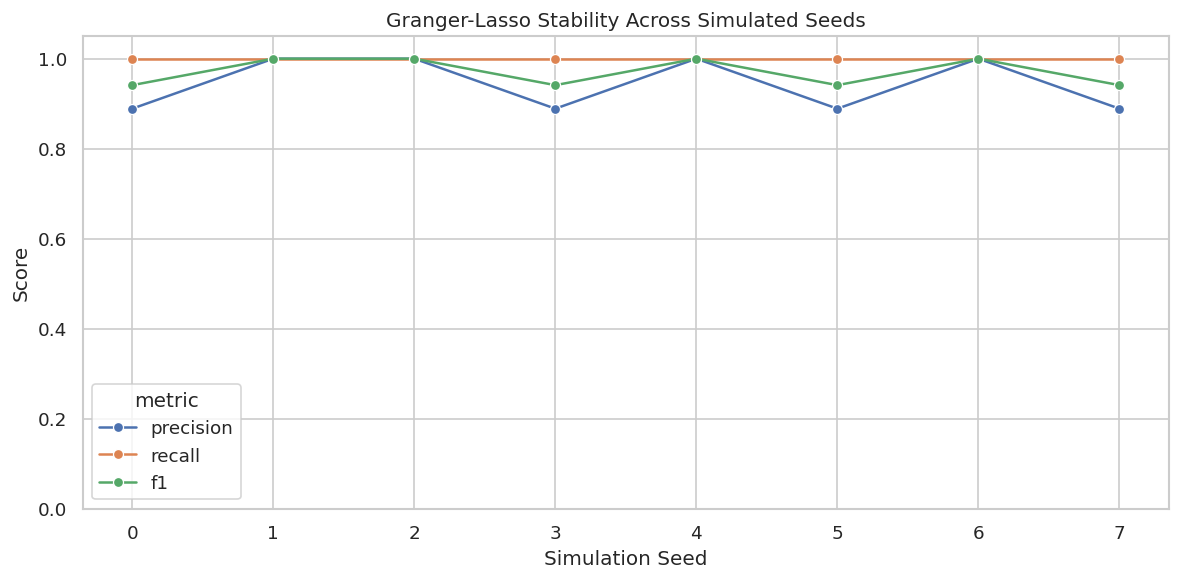
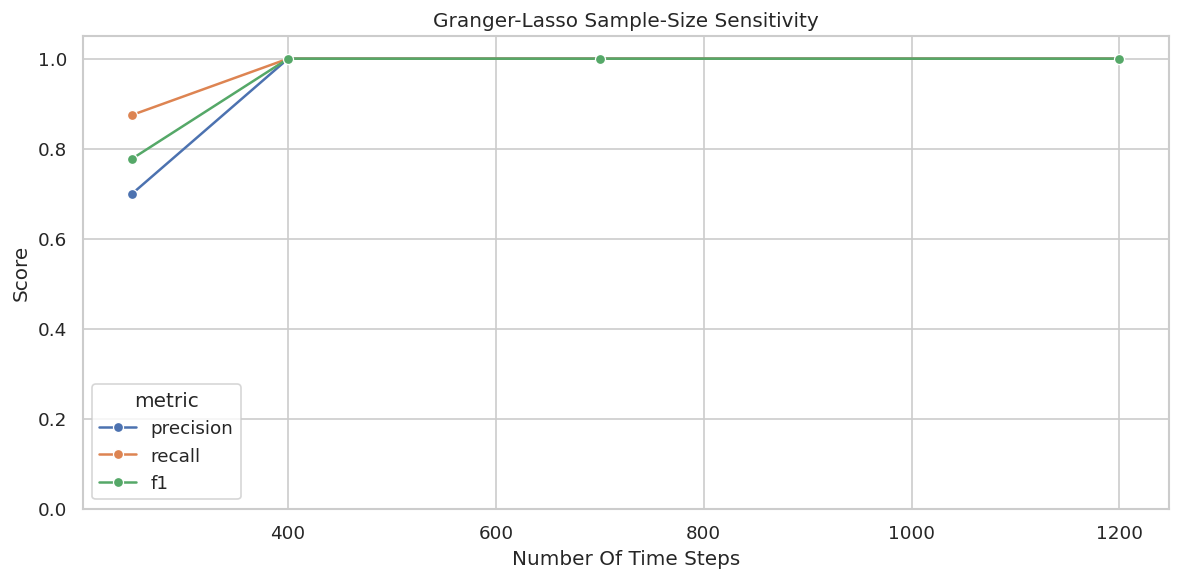
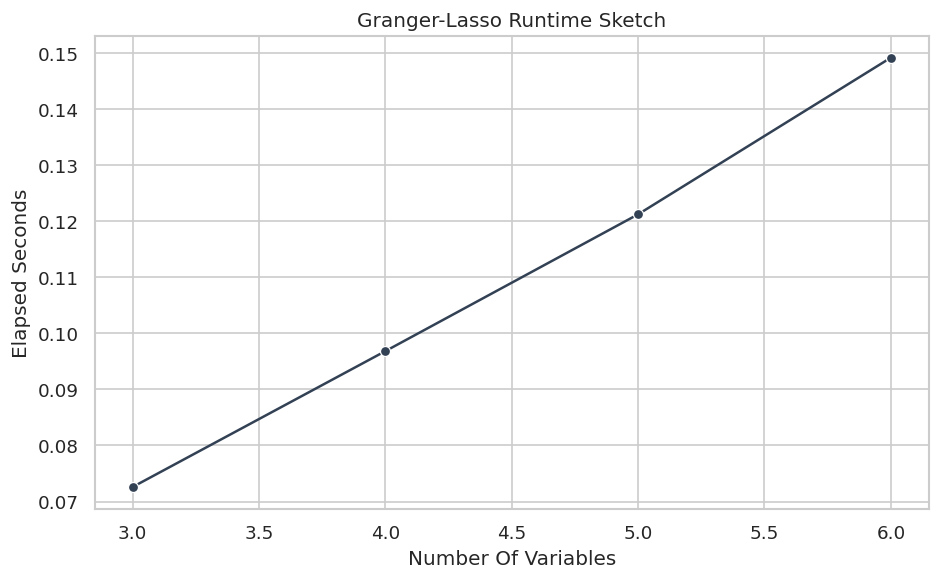
# Define reusable helpers for the Draw The True Temporal Graph section.
def add_box(ax, xy, label, color, width=0.13, height=0.065):
"""
Idea: Add a labeled node box to a Matplotlib flowchart or graph diagram.
Parameters
----------
ax : matplotlib.axes.Axes
Axes object that receives the drawing commands.
xy : object
Coordinate pair used to place a plotted node, label, or annotation.
label : str
Short label attached to a scenario, method, or plotted result.
color : str
Plot color used to identify this element.
width : float
Width used for a plotted box or simulated object.
height : float
Height used for a plotted box or simulated object.
Returns
-------
None
Adds a labeled node box directly to the supplied Matplotlib axes.
"""
x, y = xy
patch = FancyBboxPatch(
(x - width / 2, y - height / 2),
width,
height,
boxstyle="round,pad=0.014",
facecolor=color,
edgecolor="#1f2937",
linewidth=1.15,
zorder=4,
)
ax.add_patch(patch)
ax.text(x, y, label, ha="center", va="center", fontsize=9.5, fontweight="bold", zorder=5)
def box_boundary_points(start, end, width=0.13, height=0.065, gap=0.010):
"""
Move an arrow from node centers to rounded-box boundaries.
Parameters
----------
start : tuple[float, float]
Starting coordinate of the arrow or edge segment.
end : tuple[float, float]
Ending coordinate of the arrow or edge segment.
width : float
Width of the drawn box or plotted element.
height : float
Height of the drawn box or plotted element.
gap : float
Extra spacing between an edge endpoint and a node boundary.
Returns
-------
tuple[tuple[float, float], tuple[float, float]] or float
Adjusted boundary coordinates, or the offset used to compute them.
"""
x0, y0 = start
x1, y1 = end
dx = x1 - x0
dy = y1 - y0
distance = (dx**2 + dy**2) ** 0.5
if distance == 0:
return start, end
ux, uy = dx / distance, dy / distance
def boundary_offset(ux, uy):
"""
Idea: Compute how far an arrow endpoint should be shifted to avoid entering a node box.
Parameters
----------
ux : object
Horizontal unit direction used in arrow-boundary geometry.
uy : object
Vertical unit direction used in arrow-boundary geometry.
Returns
-------
float
Distance needed to move an arrow endpoint outside a node boundary.
"""
candidates = []
if abs(ux) > 1e-9:
candidates.append((width / 2) / abs(ux))
if abs(uy) > 1e-9:
candidates.append((height / 2) / abs(uy))
return min(candidates) + gap
offset = boundary_offset(ux, uy)
return (x0 + ux * offset, y0 + uy * offset), (x1 - ux * offset, y1 - uy * offset)
def add_arrow(ax, start, end, color="#334155", rad=0.0, lw=1.7):
"""
Idea: Add an arrow annotation to an existing Matplotlib axes.
Parameters
----------
ax : matplotlib.axes.Axes
Axes object that receives the drawing commands.
start : tuple[float, float]
Starting coordinate for a plotted element.
end : tuple[float, float]
Ending coordinate for a plotted element.
color : str
Plot color used to identify this element.
rad : float
Curvature parameter for the plotted arrow.
lw : float
Line width for the plotted arrow or edge.
Returns
-------
None
Adds an arrow annotation directly to the supplied Matplotlib axes.
"""
start_edge, end_edge = box_boundary_points(start, end)
arrow = FancyArrowPatch(
start_edge,
end_edge,
arrowstyle="-|>",
mutation_scale=16,
linewidth=lw,
color=color,
connectionstyle=f"arc3,rad={rad}",
zorder=2,
)
ax.add_patch(arrow)
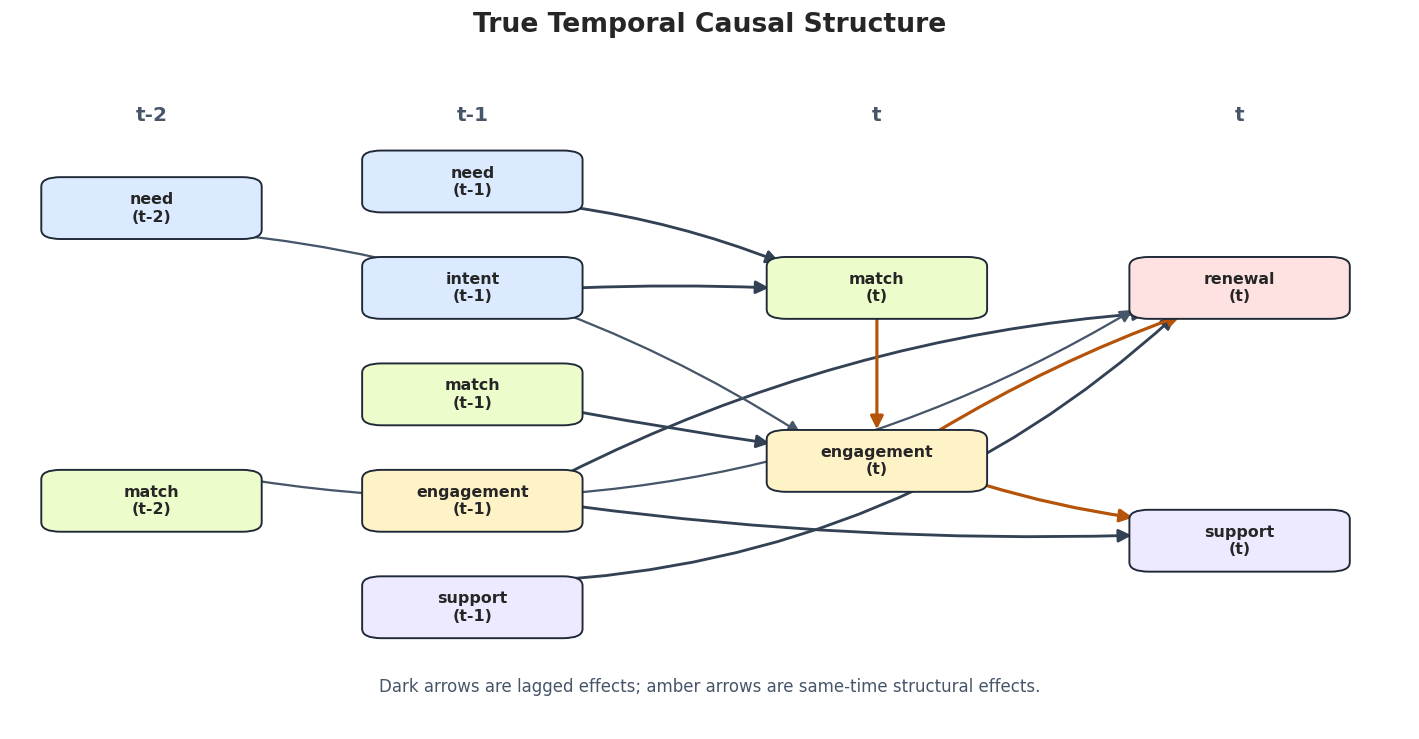
def draw_true_temporal_graph(path):
"""
Idea: Draw the lagged causal structure used as the time-series benchmark.
Parameters
----------
path : str or pathlib.Path
Input or output path.
Returns
-------
None
Draws and saves the oracle lagged temporal graph.
"""
fig, ax = plt.subplots(figsize=(15, 7.2))
ax.set_axis_off()
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
colors = {
"need": "#dbeafe",
"intent": "#dbeafe",
"match": "#ecfccb",
"engagement": "#fef3c7",
"renewal": "#fee2e2",
"support": "#ede9fe",
}
positions = {
("need", 2): (0.10, 0.78),
("match", 2): (0.10, 0.34),
("need", 1): (0.33, 0.82),
("intent", 1): (0.33, 0.66),
("match", 1): (0.33, 0.50),
("engagement", 1): (0.33, 0.34),
("support", 1): (0.33, 0.18),
("match", 0): (0.62, 0.66),
("engagement", 0): (0.62, 0.40),
("renewal", 0): (0.88, 0.66),
("support", 0): (0.88, 0.28),
}
for x, label in [(0.10, "t-2"), (0.33, "t-1"), (0.62, "t"), (0.88, "t")]:
ax.text(x, 0.92, label, ha="center", va="center", fontsize=12, fontweight="bold", color="#475569")
# Draw arrows first so boxes remain crisp and readable.
add_arrow(ax, positions[("need", 1)], positions[("match", 0)], rad=-0.06)
add_arrow(ax, positions[("intent", 1)], positions[("match", 0)], rad=-0.02)
add_arrow(ax, positions[("match", 1)], positions[("engagement", 0)], rad=0.01)
add_arrow(ax, positions[("engagement", 1)], positions[("renewal", 0)], rad=-0.10)
add_arrow(ax, positions[("engagement", 1)], positions[("support", 0)], rad=0.04)
add_arrow(ax, positions[("support", 1)], positions[("renewal", 0)], rad=0.18)
add_arrow(ax, positions[("need", 2)], positions[("engagement", 0)], color="#475569", rad=-0.12, lw=1.35)
add_arrow(ax, positions[("match", 2)], positions[("renewal", 0)], color="#475569", rad=0.18, lw=1.35)
add_arrow(ax, positions[("match", 0)], positions[("engagement", 0)], color="#b45309", rad=0.0, lw=1.9)
add_arrow(ax, positions[("engagement", 0)], positions[("renewal", 0)], color="#b45309", rad=-0.05, lw=1.9)
add_arrow(ax, positions[("engagement", 0)], positions[("support", 0)], color="#b45309", rad=0.04, lw=1.9)
for (variable, lag), xy in positions.items():
suffix = "t" if lag == 0 else f"t-{lag}"
add_box(ax, xy, f"{variable}\n({suffix})", colors[variable])
ax.text(
0.50,
0.06,
"Dark arrows are lagged effects; amber arrows are same-time structural effects.",
ha="center",
va="center",
fontsize=10,
color="#475569",
)
ax.set_title("True Temporal Causal Structure", pad=18, fontsize=16, fontweight="bold")
fig.savefig(path, dpi=160, bbox_inches="tight")
plt.show()
draw_true_temporal_graph(FIGURE_DIR / f"{NOTEBOOK_PREFIX}_true_temporal_graph.png")