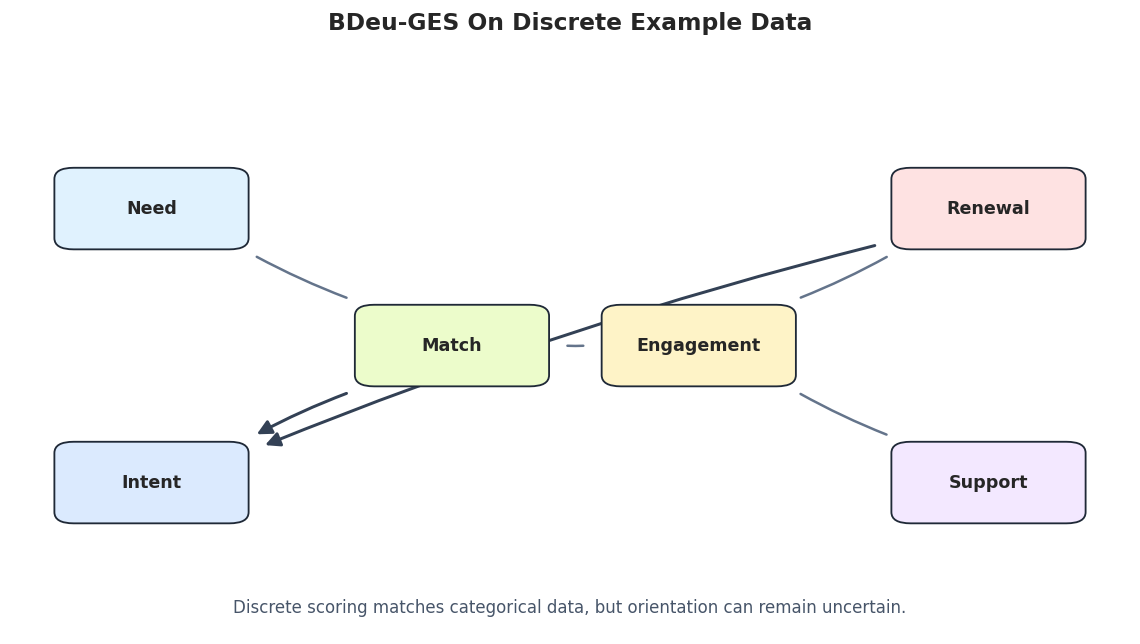
# Define reusable helpers for the Helper Functions section.
def parse_causallearn_edge(edge):
"""
Convert a causal-learn edge object into source, endpoint pattern, and target strings.
Parameters
----------
edge : object
Graph edge object or edge row being parsed, classified, or drawn.
Returns
-------
tuple[str, str, str]
Source node, endpoint mark, and target node parsed from a causal-learn edge.
"""
parts = str(edge).strip().split()
if len(parts) != 3:
return {"source": str(edge), "edge_type": "unknown", "target": "unknown"}
return {"source": parts[0], "edge_type": parts[1], "target": parts[2]}
def graph_to_edge_table(graph, label):
"""
Return a tidy edge table from a causal-learn graph object.
Parameters
----------
graph : object
Graph object returned by causal-learn or constructed from the edge table.
label : str
Readable label attached to the method, scenario, or output row.
Returns
-------
pd.DataFrame
Edge table with source, target, edge mark, and method metadata.
"""
rows = [parse_causallearn_edge(edge) for edge in graph.get_graph_edges()]
edge_df = pd.DataFrame(rows, columns=["source", "edge_type", "target"])
if edge_df.empty:
edge_df = pd.DataFrame(columns=["source", "edge_type", "target"])
edge_df.insert(0, "run", label)
return edge_df
def directed_pairs(edge_df):
"""
Extract definite directed pairs from an edge table.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
Returns
-------
set[tuple[str, str]]
Ordered source-target pairs representing directed learned edges.
"""
pairs = set()
for row in edge_df.itertuples(index=False):
if row.edge_type == "-->":
pairs.add((row.source, row.target))
elif row.edge_type == "<--":
pairs.add((row.target, row.source))
return pairs
def skeleton_pairs(edge_df):
"""
Extract learned adjacencies while ignoring endpoint direction.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
Returns
-------
set[tuple[str, str]]
Unordered node pairs representing the learned graph skeleton.
"""
pairs = set()
for row in edge_df.itertuples(index=False):
if row.target != "unknown":
pairs.add(frozenset([row.source, row.target]))
return pairs
def summarize_against_truth(edge_df, truth_df, label):
"""
Compute compact graph-recovery metrics against the synthetic truth table.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
truth_df : pd.DataFrame
Oracle edge table used as the synthetic ground-truth benchmark.
label : str
Readable label attached to the method, scenario, or output row.
Returns
-------
pd.DataFrame
Graph-recovery summary table with edge counts, precision, recall, missing edges, and extra edges.
"""
true_directed = set(zip(truth_df["source"], truth_df["target"]))
true_skeleton = {frozenset(edge) for edge in true_directed}
learned_directed = directed_pairs(edge_df)
learned_skeleton = skeleton_pairs(edge_df)
correct_directed = learned_directed & true_directed
reversed_true = {(src, dst) for src, dst in true_directed if (dst, src) in learned_directed}
missing_skeleton = true_skeleton - learned_skeleton
extra_skeleton = learned_skeleton - true_skeleton
unresolved_true = 0
for src, dst in true_directed:
pair = frozenset([src, dst])
if pair in learned_skeleton and (src, dst) not in learned_directed and (dst, src) not in learned_directed:
unresolved_true += 1
directed_count = len(learned_directed)
return pd.DataFrame(
[
{
"run": label,
"learned_edges_total": len(edge_df),
"definite_directed_edges": directed_count,
"true_edges": len(true_directed),
"correct_directed_edges": len(correct_directed),
"directed_precision": len(correct_directed) / directed_count if directed_count else np.nan,
"directed_recall": len(correct_directed) / len(true_directed) if true_directed else np.nan,
"reversed_true_edges": len(reversed_true),
"unresolved_true_adjacencies": unresolved_true,
"missing_true_adjacencies": len(missing_skeleton),
"extra_adjacencies": len(extra_skeleton),
}
]
)
def classify_edges(edge_df, truth_df):
"""
Label learned edges relative to the synthetic truth table.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
truth_df : pd.DataFrame
Oracle edge table used as the synthetic ground-truth benchmark.
Returns
-------
pd.DataFrame
Graph edge table for classify edges, including node names and edge-orientation information where available.
"""
true_directed = set(zip(truth_df["source"], truth_df["target"]))
true_skeleton = {frozenset(edge) for edge in true_directed}
rows = []
for row in edge_df.itertuples(index=False):
pair = frozenset([row.source, row.target])
learned_direction = None
if row.edge_type == "-->":
learned_direction = (row.source, row.target)
elif row.edge_type == "<--":
learned_direction = (row.target, row.source)
if learned_direction in true_directed:
status = "correct directed edge"
elif learned_direction and (learned_direction[1], learned_direction[0]) in true_directed:
status = "reversed true edge"
elif pair in true_skeleton:
status = "true adjacency with uncertain or wrong endpoint"
else:
status = "extra adjacency"
rows.append({"source": row.source, "edge_type": row.edge_type, "target": row.target, "status": status})
return pd.DataFrame(rows)
def run_ges_bic(data_df, label, lambda_value=0.5, maxP=None):
"""
Run BIC-GES quietly and return the record plus tidy edge table.
Parameters
----------
data_df : pd.DataFrame
Dataset for the current simulated or observed experiment.
label : str
Readable label attached to the method, scenario, or output row.
lambda_value : float
Numeric value for `lambda`.
maxP : object
Maximum number of parents allowed by the GES search call.
Returns
-------
tuple
Tuple containing record, edge_table, messages.
"""
buffer = io.StringIO()
with contextlib.redirect_stdout(buffer):
record = ges(
data_df.to_numpy(),
score_func="local_score_BIC",
node_names=list(data_df.columns),
lambda_value=lambda_value,
maxP=maxP,
)
edge_table = graph_to_edge_table(record["G"], label=label)
messages = pd.DataFrame({"run": label, "message": [line for line in buffer.getvalue().splitlines() if line.strip()]})
return record, edge_table, messages
def run_pc_baseline(data_df, label):
"""
Run Fisher-Z PC as a constraint-based baseline.
Parameters
----------
data_df : pd.DataFrame
Dataset for the current simulated or observed experiment.
label : str
Readable label attached to the method, scenario, or output row.
Returns
-------
pd.DataFrame
Baseline PC edge table recovered from the selected dataset.
"""
result = pc(
data_df.to_numpy(),
alpha=0.05,
indep_test="fisherz",
stable=True,
show_progress=False,
node_names=list(data_df.columns),
)
return graph_to_edge_table(result.G, label=label)
def operation_table(record, variable_names):
"""
Summarize GES forward and backward updates using variable names.
Parameters
----------
record : object
Single benchmark record being converted into a table row.
variable_names : object
Variable names used to label graph nodes or matrix columns.
Returns
-------
pd.DataFrame
Table describing how GES search operations add, delete, or reverse edges.
"""
rows = []
for phase, updates in [("forward_insert", record.get("update1", [])), ("backward_delete", record.get("update2", []))]:
for step, update in enumerate(updates, start=1):
source_idx, target_idx, conditioning_set = update
rows.append(
{
"phase": phase,
"step": step,
"source_index": int(source_idx),
"target_index": int(target_idx),
"source_variable": variable_names[int(source_idx)],
"target_variable": variable_names[int(target_idx)],
"conditioning_set": [variable_names[int(idx)] for idx in conditioning_set],
}
)
return pd.DataFrame(rows)
GRAPH_POSITIONS = {
"need": (0.11, 0.72),
"intent": (0.11, 0.28),
"match": (0.39, 0.50),
"engagement": (0.62, 0.50),
"renewal": (0.89, 0.72),
"support": (0.89, 0.28),
}
NODE_LABELS = {name: name.title() for name in GRAPH_POSITIONS}
NODE_COLORS = {
"need": "#e0f2fe",
"intent": "#dbeafe",
"match": "#ecfccb",
"engagement": "#fef3c7",
"renewal": "#fee2e2",
"support": "#f3e8ff",
}
def trim_edge_to_box(start, end, box_w=0.145, box_h=0.095, gap=0.012):
"""
Return edge endpoints that stop just outside source and target boxes.
Parameters
----------
start : tuple[float, float]
Starting coordinate of the arrow or edge segment.
end : tuple[float, float]
Ending coordinate of the arrow or edge segment.
box_w : float
Width of the node box used to trim edge endpoints.
box_h : float
Height of the node box used to trim edge endpoints.
gap : float
Extra spacing between an edge endpoint and a node boundary.
Returns
-------
tuple[tuple[float, float], tuple[float, float]]
Start and end coordinates trimmed so the edge stops at box boundaries.
"""
x0, y0 = start
x1, y1 = end
dx = x1 - x0
dy = y1 - y0
length = float(np.hypot(dx, dy))
if length == 0:
return start, end
effective_w = box_w + 0.04
effective_h = box_h + 0.04
x_limit = (effective_w / 2) / abs(dx) if dx else np.inf
y_limit = (effective_h / 2) / abs(dy) if dy else np.inf
t = min(x_limit, y_limit) + gap / length
return (x0 + dx * t, y0 + dy * t), (x1 - dx * t, y1 - dy * t)
def draw_box_graph(edge_df, title, path, note=None):
"""
Draw a DAG/CPDAG-style graph with rounded boxes and visible arrowheads.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
title : str
Title shown above the plot.
path : str or pathlib.Path
Optional output path for the figure.
note : str or None
Optional explanatory note shown in the plot.
Returns
-------
None
Draws the graph diagram directly on the Matplotlib axes and saves it when requested.
"""
fig, ax = plt.subplots(figsize=(12, 6.2))
ax.set_axis_off()
ax.set_xlim(-0.02, 1.02)
ax.set_ylim(0.04, 0.96)
box_w, box_h = 0.145, 0.095
for row in edge_df.itertuples(index=False):
if row.source not in GRAPH_POSITIONS or row.target not in GRAPH_POSITIONS:
continue
raw_start = GRAPH_POSITIONS[row.source]
raw_end = GRAPH_POSITIONS[row.target]
if row.edge_type == "<--":
raw_start, raw_end = raw_end, raw_start
start, end = trim_edge_to_box(raw_start, raw_end, box_w=box_w, box_h=box_h)
if row.edge_type in {"-->", "<--"}:
arrowstyle = "-|>"
mutation_scale = 18
linewidth = 1.8
color = "#334155"
else:
arrowstyle = "-"
mutation_scale = 1
linewidth = 1.5
color = "#64748b"
arrow = FancyArrowPatch(
start,
end,
arrowstyle=arrowstyle,
mutation_scale=mutation_scale,
linewidth=linewidth,
color=color,
connectionstyle="arc3,rad=0.035",
zorder=2,
)
ax.add_patch(arrow)
for node, (x, y) in GRAPH_POSITIONS.items():
rect = FancyBboxPatch(
(x - box_w / 2, y - box_h / 2),
box_w,
box_h,
boxstyle="round,pad=0.018",
facecolor=NODE_COLORS[node],
edgecolor="#1f2937",
linewidth=1.1,
zorder=5,
)
ax.add_patch(rect)
ax.text(x, y, NODE_LABELS[node], ha="center", va="center", fontsize=10.5, fontweight="bold", zorder=6)
if note:
ax.text(0.50, 0.08, note, ha="center", va="center", fontsize=10, color="#475569")
ax.set_title(title, pad=18, fontsize=14, fontweight="bold")
fig.savefig(path, dpi=160, bbox_inches="tight")
plt.show()
def truth_as_edge_table(truth_df, label="truth"):
"""
Convert a truth edge table to the plotting schema.
Parameters
----------
truth_df : pd.DataFrame
Oracle edge table used as the synthetic ground-truth benchmark.
label : str
Readable label attached to the method, scenario, or output row.
Returns
-------
pd.DataFrame
Oracle graph edge table with run label and directed-edge marks.
"""
return truth_df.assign(run=label, edge_type="-->")[["run", "source", "edge_type", "target"]]