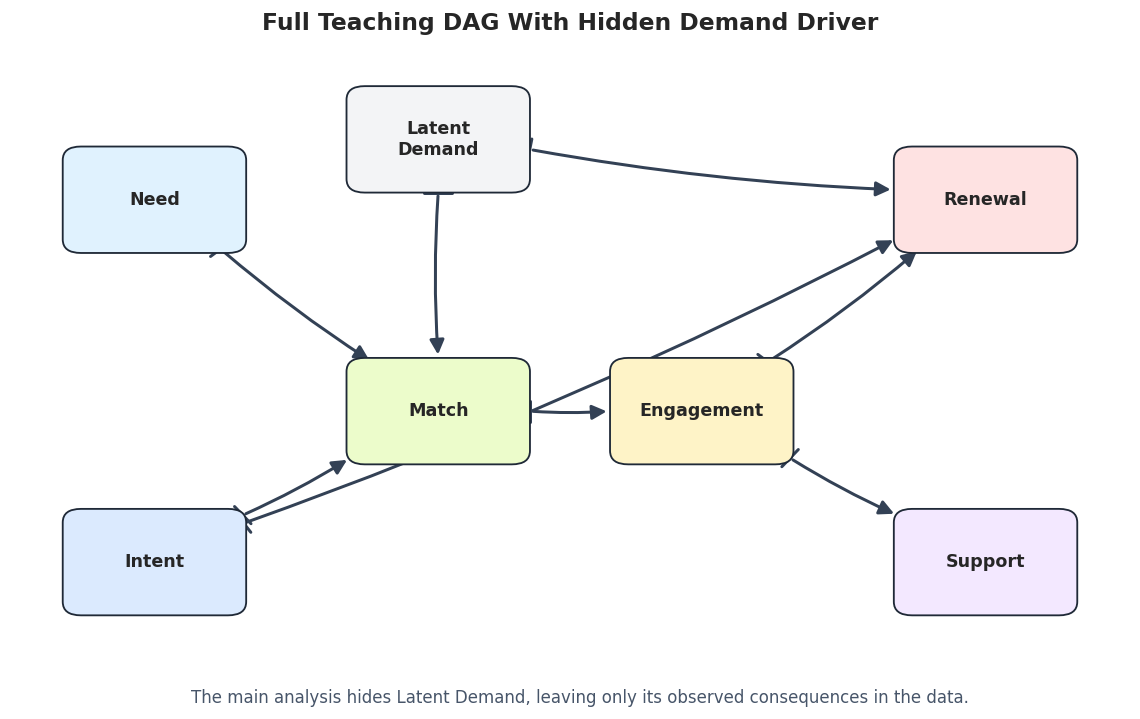
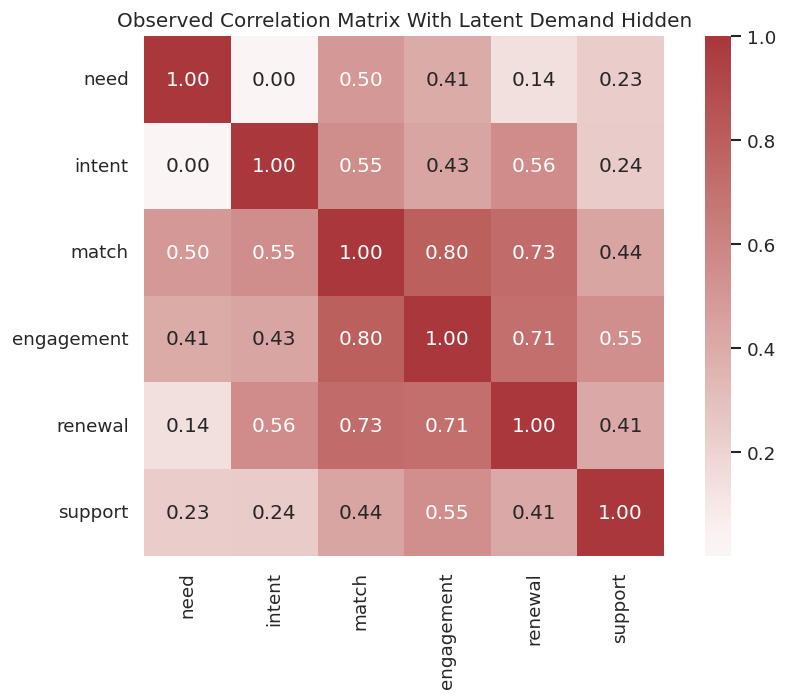
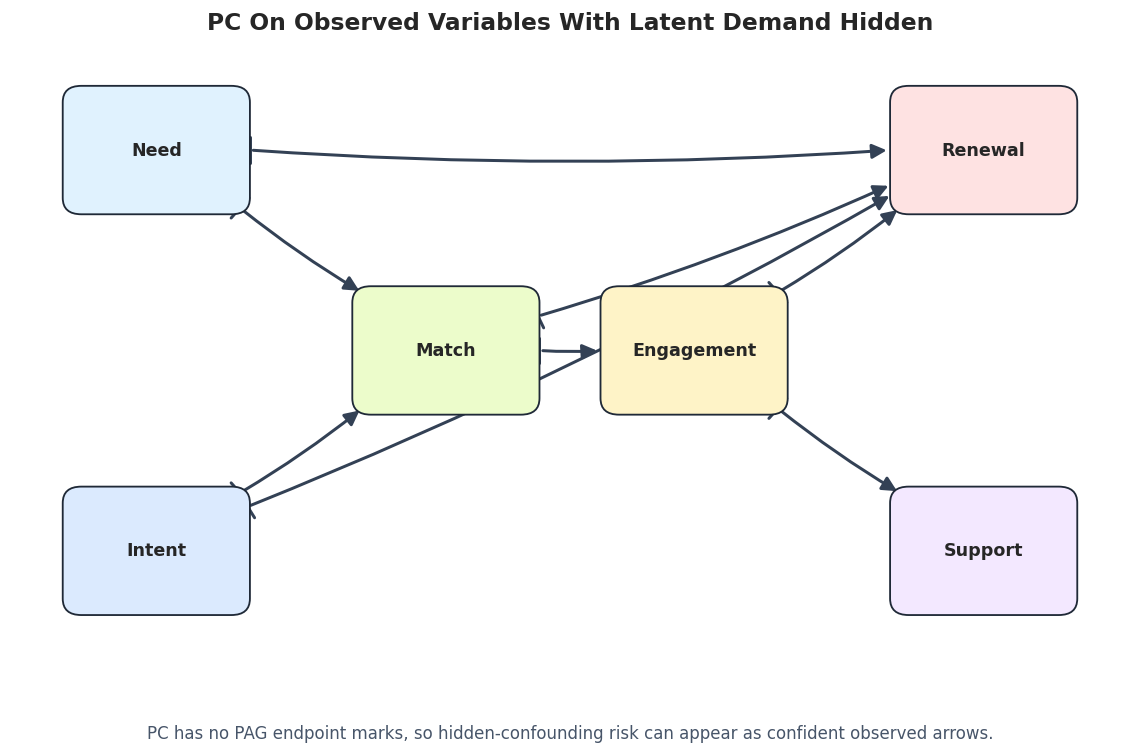
# Define reusable helpers for the Helper Functions For DAGs, PAGs, And Metrics section.
def parse_causallearn_edge(edge):
"""
Convert a causal-learn edge object into source, endpoint pattern, and target strings.
Parameters
----------
edge : object
Graph edge object or edge row being parsed, classified, or drawn.
Returns
-------
tuple[str, str, str]
Source node, endpoint mark, and target node parsed from a causal-learn edge.
"""
parts = str(edge).strip().split()
if len(parts) != 3:
return {"source": str(edge), "edge_type": "unknown", "target": "unknown"}
return {"source": parts[0], "edge_type": parts[1], "target": parts[2]}
def graph_to_edge_table(graph, label, edge_properties=None):
"""
Return a tidy edge table from a causal-learn Graph result.
Parameters
----------
graph : object
Graph object returned by causal-learn or constructed from the edge table.
label : str
Readable label attached to the method, scenario, or output row.
edge_properties : object
Additional edge metadata attached by the graph algorithm.
Returns
-------
pd.DataFrame
Edge table with source, target, edge mark, and method metadata.
"""
rows = []
property_lookup = {}
if edge_properties is not None:
for edge in edge_properties:
parsed = parse_causallearn_edge(edge)
key = (parsed["source"], parsed["edge_type"], parsed["target"])
props = getattr(edge, "properties", [])
property_lookup[key] = ",".join(getattr(prop, "name", str(prop)) for prop in props) or "none"
for edge in graph.get_graph_edges():
parsed = parse_causallearn_edge(edge)
key = (parsed["source"], parsed["edge_type"], parsed["target"])
rows.append(
{
"run": label,
"source": parsed["source"],
"edge_type": parsed["edge_type"],
"target": parsed["target"],
"edge_properties": property_lookup.get(key, "not_returned" if edge_properties is None else "none"),
}
)
return pd.DataFrame(rows, columns=["run", "source", "edge_type", "target", "edge_properties"])
def run_fci_quiet(data, label, node_names, alpha=0.05, depth=-1, max_path_length=-1):
"""
Run FCI while capturing small orientation messages printed by the implementation.
Parameters
----------
data : array-like or pd.DataFrame
Data passed into the demonstrated method or score function.
label : str
Readable label attached to the method, scenario, or output row.
node_names : list[str]
Variable names used to create graph nodes.
alpha : float
Significance level for an independence test or transparency level for plotting.
depth : int
Maximum conditioning-set depth used by the discovery algorithm.
max_path_length : int
Maximum path length used by FCI during possible-DSEP search.
Returns
-------
tuple
Tuple containing graph, edges, pd.DataFrame({'run': label, 'message': messages}), aligned for the causal estimator.
"""
buffer = io.StringIO()
with contextlib.redirect_stdout(buffer):
graph, edges = fci(
data,
independence_test_method="fisherz",
alpha=alpha,
depth=depth,
max_path_length=max_path_length,
verbose=False,
show_progress=False,
node_names=node_names,
)
messages = [line for line in buffer.getvalue().splitlines() if line.strip()]
return graph, edges, pd.DataFrame({"run": label, "message": messages})
def endpoint_category(edge_type):
"""
Map causal-learn edge strings to a plain-language PAG category.
Parameters
----------
edge_type : str
Endpoint pattern or edge mark string returned by the graph algorithm.
Returns
-------
str
Readable category describing the graph endpoint pattern.
"""
if edge_type in {"-->", "<--"}:
return "definite directed edge"
if edge_type in {"o->", "<-o"}:
return "partially oriented edge"
if edge_type == "<->":
return "possible latent-confounding edge"
if edge_type in {"o-o", "---"}:
return "unresolved adjacency"
return "other endpoint pattern"
def directed_pairs(edge_df):
"""
Extract only definite directed pairs from an edge table.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
Returns
-------
set[tuple[str, str]]
Ordered source-target pairs representing directed learned edges.
"""
pairs = set()
for row in edge_df.itertuples(index=False):
if row.edge_type == "-->":
pairs.add((row.source, row.target))
elif row.edge_type == "<--":
pairs.add((row.target, row.source))
return pairs
def skeleton_pairs(edge_df):
"""
Extract adjacencies while ignoring endpoint marks.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
Returns
-------
set[tuple[str, str]]
Unordered node pairs representing the learned graph skeleton.
"""
pairs = set()
for row in edge_df.itertuples(index=False):
if row.target != "unknown":
pairs.add(frozenset([row.source, row.target]))
return pairs
def summarize_against_observed_truth(edge_df, truth_df, label):
"""
Compute compact recovery metrics against the observed-variable truth table.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
truth_df : pd.DataFrame
Oracle edge table used as the synthetic ground-truth benchmark.
label : str
Readable label attached to the method, scenario, or output row.
Returns
-------
pd.DataFrame
Summary table for summarize against observed truth, with one row per method, scenario, group, or diagnostic check.
"""
true_directed = set(zip(truth_df["source"], truth_df["target"]))
true_skeleton = {frozenset(edge) for edge in true_directed}
learned_directed = directed_pairs(edge_df)
learned_skeleton = skeleton_pairs(edge_df)
correct_directed = learned_directed & true_directed
reversed_true = {(src, dst) for src, dst in true_directed if (dst, src) in learned_directed}
missing_skeleton = true_skeleton - learned_skeleton
extra_skeleton = learned_skeleton - true_skeleton
partially_oriented = int(edge_df["edge_type"].isin(["o->", "<-o"]).sum())
bidirected_like = int((edge_df["edge_type"] == "<->").sum())
unresolved = int(edge_df["edge_type"].isin(["o-o", "---"]).sum())
directed_count = len(learned_directed)
return pd.DataFrame(
[
{
"run": label,
"learned_edges_total": len(edge_df),
"definite_directed_edges": directed_count,
"partially_oriented_edges": partially_oriented,
"bidirected_like_edges": bidirected_like,
"unresolved_adjacencies": unresolved,
"correct_definite_directed_edges": len(correct_directed),
"directed_precision": len(correct_directed) / directed_count if directed_count else np.nan,
"directed_recall": len(correct_directed) / len(true_directed) if true_directed else np.nan,
"reversed_true_edges": len(reversed_true),
"missing_true_adjacencies": len(missing_skeleton),
"extra_adjacencies": len(extra_skeleton),
}
]
)
def classify_edges(edge_df, truth_df):
"""
Label learned edges relative to the observed synthetic truth table.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
truth_df : pd.DataFrame
Oracle edge table used as the synthetic ground-truth benchmark.
Returns
-------
pd.DataFrame
Graph edge table for classify edges, including node names and edge-orientation information where available.
"""
true_directed = set(zip(truth_df["source"], truth_df["target"]))
true_skeleton = {frozenset(edge) for edge in true_directed}
rows = []
for row in edge_df.itertuples(index=False):
pair = frozenset([row.source, row.target])
learned_direction = None
if row.edge_type == "-->":
learned_direction = (row.source, row.target)
elif row.edge_type == "<--":
learned_direction = (row.target, row.source)
if learned_direction in true_directed:
status = "correct definite direction"
elif learned_direction and (learned_direction[1], learned_direction[0]) in true_directed:
status = "reversed definite direction"
elif pair in true_skeleton:
status = "true adjacency with non-definite endpoint"
else:
status = "extra observed adjacency"
rows.append(
{
"source": row.source,
"edge_type": row.edge_type,
"target": row.target,
"endpoint_category": endpoint_category(row.edge_type),
"edge_properties": row.edge_properties,
"status_vs_observed_truth": status,
}
)
return pd.DataFrame(rows)
def hidden_common_cause_pairs(full_truth_df):
"""
Find observed variable pairs that share a latent parent in the synthetic full truth table.
Parameters
----------
full_truth_df : pd.DataFrame
DataFrame for the `full truth` part of `hidden_common_cause_pairs`.
Returns
-------
pd.DataFrame
Table of observed variable pairs that share a hidden parent in the full synthetic truth graph.
"""
latent_edges = full_truth_df[full_truth_df["source"].str.startswith("latent")]
rows = []
for latent, group in latent_edges.groupby("source"):
children = sorted(group["target"].tolist())
for i, left in enumerate(children):
for right in children[i + 1 :]:
rows.append({"latent_variable": latent, "observed_child_a": left, "observed_child_b": right})
return pd.DataFrame(rows)
OBS_POS = {
"need": (0.10, 0.72),
"intent": (0.10, 0.28),
"match": (0.38, 0.50),
"engagement": (0.62, 0.50),
"renewal": (0.90, 0.72),
"support": (0.90, 0.28),
}
FULL_POS = {
"need": (0.08, 0.74),
"intent": (0.08, 0.26),
"latent_demand": (0.36, 0.82),
"match": (0.36, 0.46),
"engagement": (0.62, 0.46),
"renewal": (0.90, 0.74),
"support": (0.90, 0.26),
}
NODE_COLORS = {
"need": "#e0f2fe",
"intent": "#dbeafe",
"latent_demand": "#f3f4f6",
"match": "#ecfccb",
"engagement": "#fef3c7",
"renewal": "#fee2e2",
"support": "#f3e8ff",
}
NODE_LABELS = {
"need": "Need",
"intent": "Intent",
"latent_demand": "Latent\nDemand",
"match": "Match",
"engagement": "Engagement",
"renewal": "Renewal",
"support": "Support",
}
def trim_edge_to_box(start, end, box_w=0.145, box_h=0.105, gap=0.018):
"""
Return edge endpoints that stop just outside source and target boxes.
Parameters
----------
start : tuple[float, float]
Starting coordinate of the arrow or edge segment.
end : tuple[float, float]
Ending coordinate of the arrow or edge segment.
box_w : float
Width of the node box used to trim edge endpoints.
box_h : float
Height of the node box used to trim edge endpoints.
gap : float
Extra spacing between an edge endpoint and a node boundary.
Returns
-------
tuple[tuple[float, float], tuple[float, float]]
Start and end coordinates trimmed so the edge stops at box boundaries.
"""
x0, y0 = start
x1, y1 = end
dx = x1 - x0
dy = y1 - y0
length = float(np.hypot(dx, dy))
if length == 0:
return start, end
x_limit = (box_w / 2) / abs(dx) if dx else np.inf
y_limit = (box_h / 2) / abs(dy) if dy else np.inf
t = min(x_limit, y_limit) + gap / length
return (x0 + dx * t, y0 + dy * t), (x1 - dx * t, y1 - dy * t)
def add_endpoint_mark(ax, point, other, mark, color="#334155"):
"""
Draw a PAG endpoint mark at a trimmed edge endpoint.
Parameters
----------
ax : matplotlib.axes.Axes
Axes object that receives the drawing command.
point : tuple[float, float]
Endpoint coordinate where the mark is drawn.
other : tuple[float, float]
Opposite endpoint coordinate used to orient the mark.
mark : str
Endpoint mark type such as tail, arrow, or circle.
color : str
Color used for the plotted element.
Returns
-------
None
Performs the add endpoint mark side effect and returns no value.
"""
if mark == "arrow":
return
if mark == "circle":
ax.scatter(
[point[0]],
[point[1]],
s=80,
facecolor="white",
edgecolor=color,
linewidth=1.7,
zorder=4,
)
elif mark == "tail":
x, y = point
ox, oy = other
dx, dy = x - ox, y - oy
length = float(np.hypot(dx, dy))
if length == 0:
return
nx_, ny_ = -dy / length, dx / length
half = 0.014
ax.plot([x - nx_ * half, x + nx_ * half], [y - ny_ * half, y + ny_ * half], color=color, linewidth=1.8, zorder=4)
def endpoint_marks(edge_type):
"""
Return source and target endpoint marks for a causal-learn edge string.
Parameters
----------
edge_type : str
Endpoint pattern or edge mark string returned by the graph algorithm.
Returns
-------
tuple[str, str]
Pair of endpoint marks for a graph edge.
"""
if edge_type == "-->":
return "tail", "arrow"
if edge_type == "<--":
return "arrow", "tail"
if edge_type == "o->":
return "circle", "arrow"
if edge_type == "<-o":
return "arrow", "circle"
if edge_type == "<->":
return "arrow", "arrow"
if edge_type == "o-o":
return "circle", "circle"
return "tail", "tail"
def draw_pag_or_dag(edge_df, title, path, positions, note=None, show_endpoint_labels=False):
"""
Draw a DAG/PAG-style graph with rounded nodes and visible endpoint marks.
Parameters
----------
edge_df : pd.DataFrame
Learned or oracle edge table being summarized or drawn.
title : str
Title shown above the plot.
path : str or pathlib.Path
Optional output path for the figure.
positions : dict
Node positions used to draw the graph.
note : str or None
Optional explanatory note shown in the plot.
show_endpoint_labels : bool
Whether endpoint labels are printed near PAG edge marks.
Returns
-------
None
Draws a teaching DAG or PAG directly on the Matplotlib axes.
"""
fig, ax = plt.subplots(figsize=(12, 6.3))
ax.set_axis_off()
box_w, box_h = 0.145, 0.105
for row in edge_df.itertuples(index=False):
if row.source not in positions or row.target not in positions:
continue
raw_start = positions[row.source]
raw_end = positions[row.target]
start, end = trim_edge_to_box(raw_start, raw_end, box_w=box_w, box_h=box_h)
source_mark, target_mark = endpoint_marks(row.edge_type)
has_arrow = source_mark == "arrow" or target_mark == "arrow"
if source_mark == "arrow" and target_mark == "arrow":
arrowstyle = "<|-|>"
elif target_mark == "arrow":
arrowstyle = "-|>"
elif source_mark == "arrow":
arrowstyle = "<|-"
else:
arrowstyle = "-"
color = "#334155" if row.edge_type != "<->" else "#7c2d12"
arrow = FancyArrowPatch(
start,
end,
arrowstyle=arrowstyle,
mutation_scale=18 if has_arrow else 1,
linewidth=1.8,
color=color,
connectionstyle="arc3,rad=0.035",
zorder=2,
)
ax.add_patch(arrow)
add_endpoint_mark(ax, start, end, source_mark, color=color)
add_endpoint_mark(ax, end, start, target_mark, color=color)
if show_endpoint_labels and row.edge_type not in {"-->", "<--"}:
mid_x = (start[0] + end[0]) / 2
mid_y = (start[1] + end[1]) / 2
ax.text(mid_x, mid_y + 0.035, row.edge_type, ha="center", va="center", fontsize=9, color="#475569")
for node, (x, y) in positions.items():
rect = FancyBboxPatch(
(x - box_w / 2, y - box_h / 2),
box_w,
box_h,
boxstyle="round,pad=0.018",
facecolor=NODE_COLORS.get(node, "#f8fafc"),
edgecolor="#1f2937",
linewidth=1.1,
zorder=5,
)
ax.add_patch(rect)
ax.text(x, y, NODE_LABELS.get(node, node), ha="center", va="center", fontsize=10.5, fontweight="bold", zorder=6)
if note:
ax.text(0.50, 0.08, note, ha="center", va="center", fontsize=10, color="#475569")
ax.set_title(title, pad=18, fontsize=14, fontweight="bold")
fig.savefig(path, dpi=160, bbox_inches="tight")
plt.show()
def truth_as_edges(truth_df, label="truth"):
"""
Convert a truth table with directed rows into the plotting schema.
Parameters
----------
truth_df : pd.DataFrame
Oracle edge table used as the synthetic ground-truth benchmark.
label : str
Readable label attached to the method, scenario, or output row.
Returns
-------
pd.DataFrame
Oracle graph edge table with run label, edge type, and truth marker.
"""
return truth_df.assign(run=label, edge_type="-->", edge_properties="truth")[["run", "source", "edge_type", "target", "edge_properties"]]