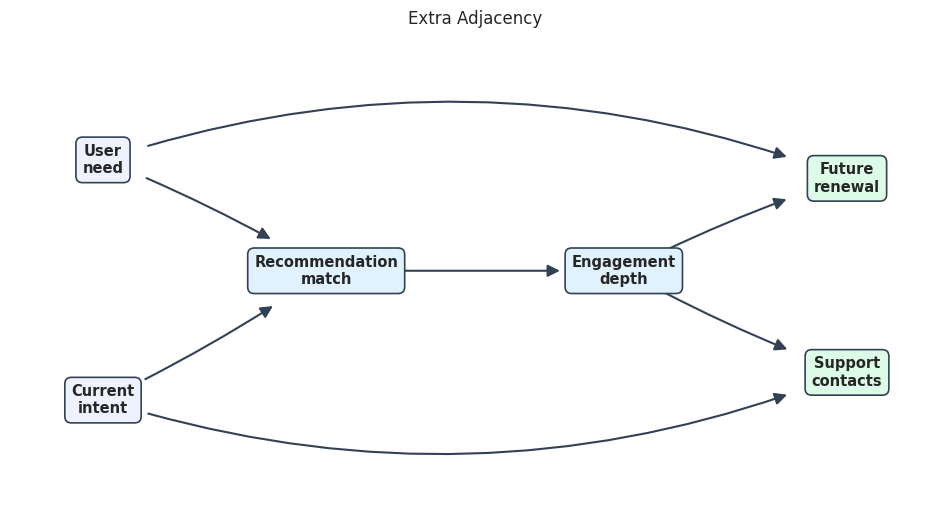
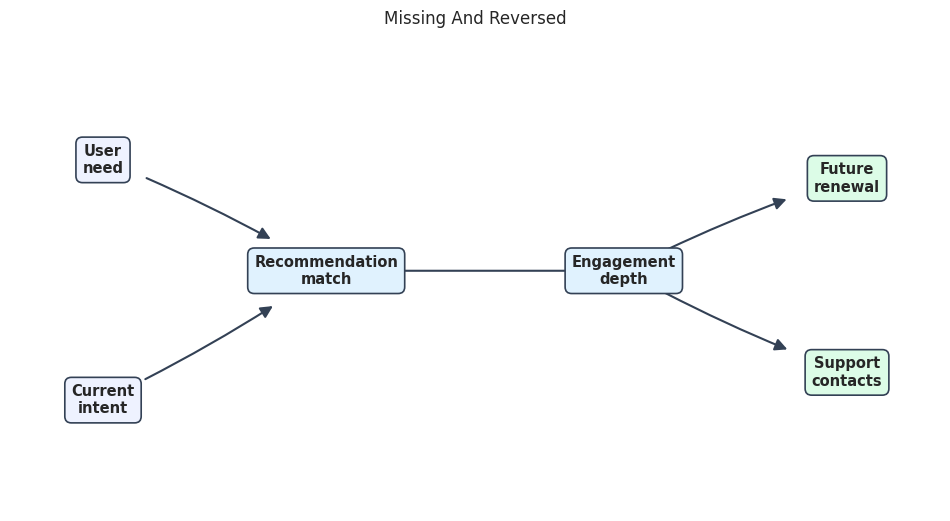
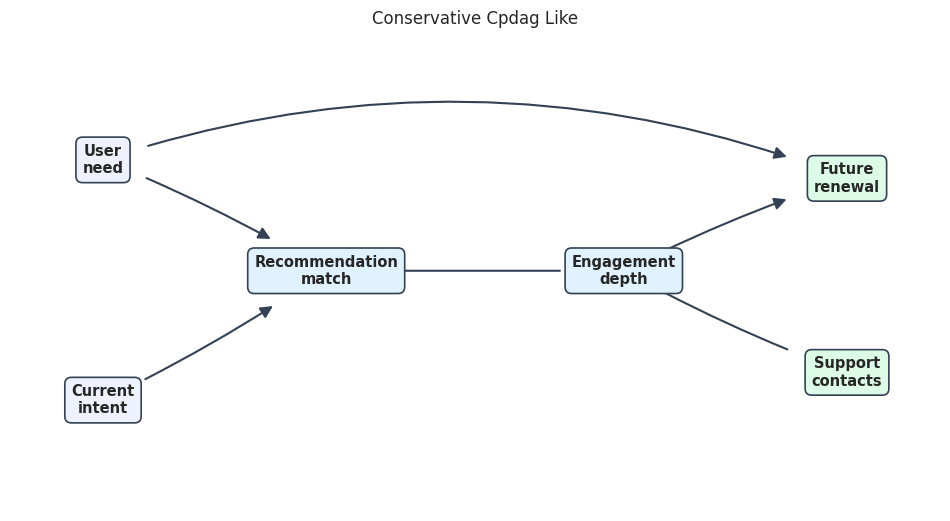
# Define reusable helpers for the Rendering The Teaching DAG section.
def render_edge_table_graph(
edge_table,
labels,
positions,
title,
output_path,
node_colors=None,
edge_radii=None,
circle_positions=None,
edge_color="#334155",
figsize=(12, 6),
):
"""
Render an edge table using the shared tutorial DAG style.
Parameters
----------
edge_table : pd.DataFrame
Table of source-target edges and endpoint marks to convert, draw, or score.
labels : dict[str, str]
Display labels used for graph nodes in the rendered figure.
positions : dict
Node positions used to draw the graph.
title : str
Title shown above the plot.
output_path : str or pathlib.Path
Output path where the rendered figure is saved.
node_colors : dict[str, str] or None
Optional mapping from node names to display colors.
edge_radii : dict or None
Optional curvature settings for individual plotted edges.
circle_positions : dict or None
Optional coordinates for PAG circle endpoint marks.
edge_color : str
Color used for rendered edges or arrows.
figsize : tuple[float, float]
Matplotlib figure size for the rendered graph.
Returns
-------
pathlib.Path
Path to the saved graph figure rendered from the edge table.
"""
node_colors = node_colors or {node: "#e0f2fe" for node in labels}
edge_radii = edge_radii or {}
circle_positions = circle_positions or {}
fig, ax = plt.subplots(figsize=figsize)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.set_axis_off()
endpoint_circle_queue = []
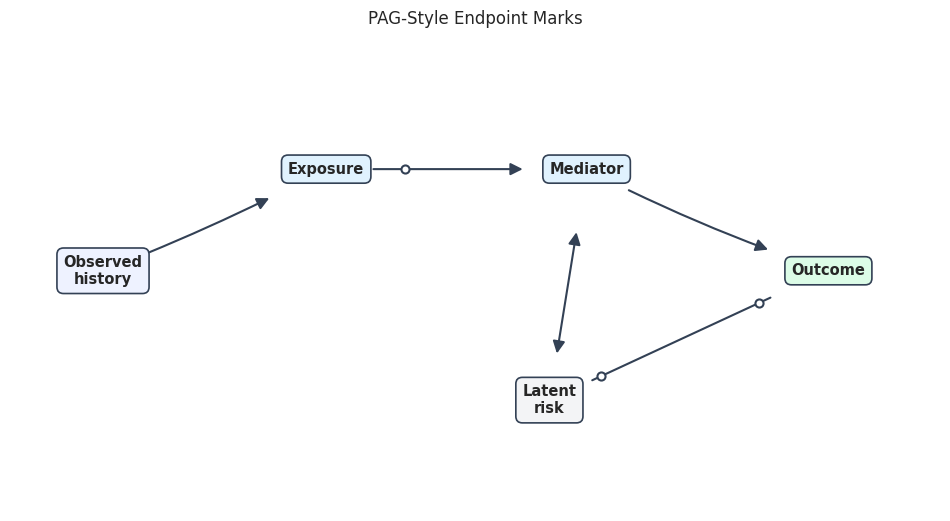
def endpoint_circle(source, target, near_source=True):
"""
Queue a PAG circle endpoint, using explicit positions when provided.
Parameters
----------
source : str
Source node name for a graph edge.
target : str or array-like
Outcome, metric, or variable whose residualized or transformed value is needed.
near_source : bool
Whether the endpoint mark should be placed near the source node.
Returns
-------
None
Performs the endpoint circle side effect and returns no value.
"""
side = "source" if near_source else "target"
key = (source, target, side)
if key in circle_positions:
point = np.array(circle_positions[key], dtype=float)
else:
source_xy = np.array(positions[source], dtype=float)
target_xy = np.array(positions[target], dtype=float)
t = 0.18 if near_source else 0.82
point = source_xy + t * (target_xy - source_xy)
endpoint_circle_queue.append(point)
for row in edge_table.itertuples(index=False):
source = row.source
target = row.target
mark = row.mark
rad = edge_radii.get((source, target), edge_radii.get((target, source), 0.0))
linestyle = "-"
arrowstyle = "-|>"
xy = positions[target]
xytext = positions[source]
if mark == "<--":
xy = positions[source]
xytext = positions[target]
elif mark == "---":
arrowstyle = "-"
elif mark == "<->":
arrowstyle = "<|-|>"
elif mark == "o->":
endpoint_circle(source, target, near_source=True)
elif mark == "<-o":
xy = positions[source]
xytext = positions[target]
endpoint_circle(source, target, near_source=False)
elif mark == "o-o":
arrowstyle = "-"
endpoint_circle(source, target, near_source=True)
endpoint_circle(source, target, near_source=False)
ax.annotate(
"",
xy=xy,
xytext=xytext,
arrowprops=dict(
arrowstyle=arrowstyle,
color=edge_color,
linewidth=1.5,
mutation_scale=18,
shrinkA=34,
shrinkB=46,
linestyle=linestyle,
connectionstyle=f"arc3,rad={rad}",
),
zorder=1,
)
for point in endpoint_circle_queue:
ax.scatter(
point[0],
point[1],
s=34,
facecolors="white",
edgecolors=edge_color,
linewidths=1.5,
zorder=3,
)
for node, (x, y) in positions.items():
ax.text(
x,
y,
labels[node],
ha="center",
va="center",
fontsize=10.5,
fontweight="bold",
bbox=dict(
boxstyle="round,pad=0.45",
facecolor=node_colors.get(node, "#e0f2fe"),
edgecolor="#334155",
linewidth=1.2,
),
zorder=4,
)
ax.set_title(title, pad=18)
output_path = Path(output_path)
output_path.parent.mkdir(parents=True, exist_ok=True)
fig.savefig(output_path, dpi=160, bbox_inches="tight")
plt.show()
return output_path
teaching_positions = {
"Need": (0.10, 0.76),
"Intent": (0.10, 0.24),
"Match": (0.34, 0.52),
"Engagement": (0.66, 0.52),
"Renewal": (0.90, 0.72),
"Support": (0.90, 0.30),
}
teaching_node_colors = {
"Need": "#eef2ff",
"Intent": "#eef2ff",
"Match": "#e0f2fe",
"Engagement": "#e0f2fe",
"Renewal": "#dcfce7",
"Support": "#dcfce7",
}
teaching_edge_radii = {
("Need", "Match"): -0.04,
("Intent", "Match"): 0.04,
("Match", "Engagement"): 0.00,
("Engagement", "Renewal"): -0.04,
("Engagement", "Support"): 0.04,
("Need", "Renewal"): -0.18,
("Intent", "Support"): 0.18,
}
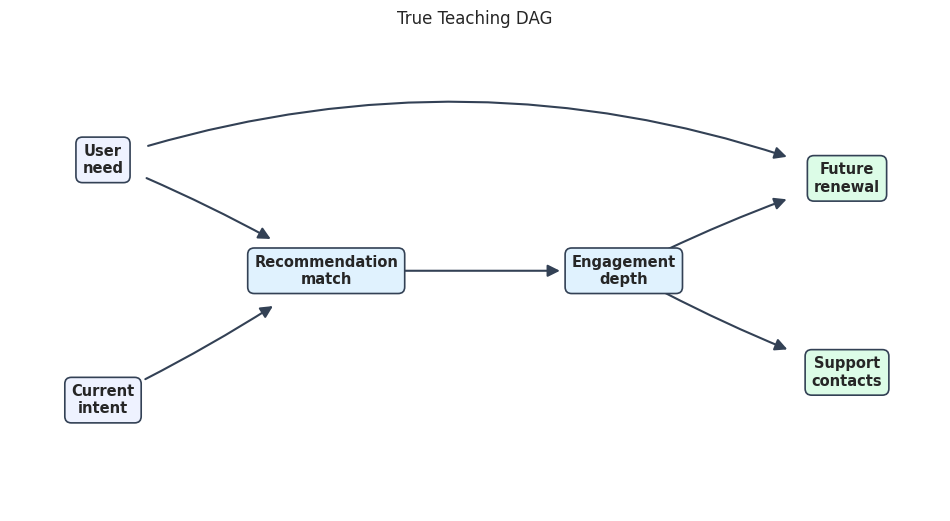
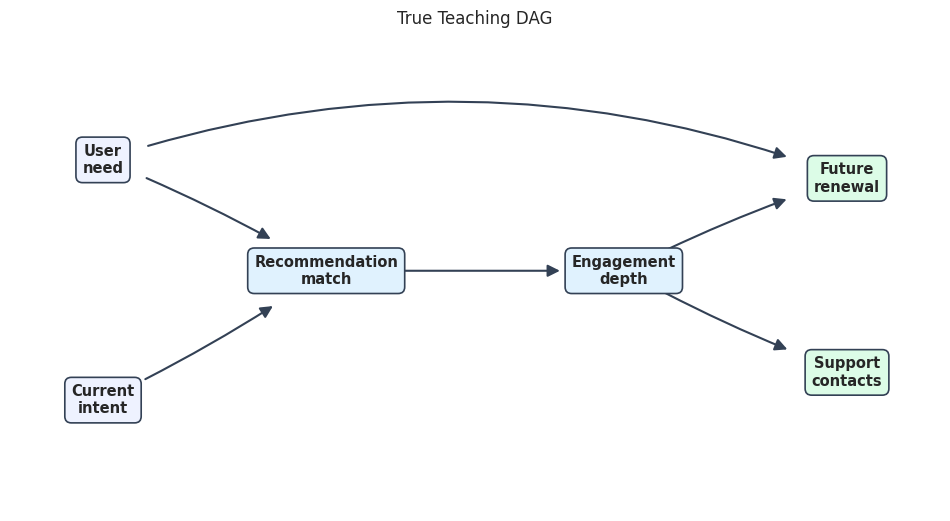
true_dag_path = FIGURE_DIR / f"{NOTEBOOK_PREFIX}_true_teaching_dag.png"
render_edge_table_graph(
true_edge_table,
node_labels,
teaching_positions,
"True Teaching DAG",
true_dag_path,
node_colors=teaching_node_colors,
edge_radii=teaching_edge_radii,
)