This notebook adds machine learning to the interference workflow.
The previous notebooks established the causal design and estimated direct, indirect, and total effects with transparent randomized estimators. That is the foundation. This notebook asks a more advanced product question:
Can we use user, item, slate, and spillover features to predict when a promotion is likely to create positive net slate value?
The notebook uses advanced models for three purposes:
Outcome modeling: predict total simulated slate clicks from pre-promotion features and treatment assignment.
Conditional effect modeling: predict the counterfactual difference between promoting the focal item and leaving it unpromoted.
Policy targeting: compare random promotion with model-targeted promotion rules.
The important discipline is that ML supports the causal design. Treatment was randomized at the slate level, so the simple randomized estimator remains the baseline. The models are used to understand heterogeneity and policy targeting, and their predictions are checked against the known simulation lift available in this synthetic setup.
Dataset and Simulation Design Context
This project uses MovieLens 32M as a realistic user-item preference source. MovieLens contains ratings and movie metadata, but it lacks production recommendation impressions, randomized promotions, and observed slate outcomes.
Because the public data lack a real experiment, the project builds a transparent simulation. It constructs recommendation slates, selects lower-ranked focal movies, randomizes focal promotion at the slate level, and generates outcomes through an explicit competition model.
The simulated experiment is designed to teach interference. Promoting one item can increase that item’s engagement while reducing attention for substitutes and neighboring items. The estimands are direct focal effects, spillover effects, and total slate value, so the project emphasizes experiment design and measurement logic as a teaching workflow.
Role of this notebook. This notebook adds flexible outcome models and targeted policy evaluation to ask whether model-assisted targeting can avoid harmful promotions.
Mathematical Setup
Model-assisted interference analysis predicts counterfactual outcomes under alternative exposure states. If (X_i) contains slate and item features, the outcome model is
The machine-learning models are therefore used for adjustment, heterogeneity, and prediction. Their estimates still need to be checked against the known simulation structure and simpler randomized estimators.
1. Environment and Paths
This cell imports the modeling libraries. LightGBM and XGBoost are used as flexible tree-based outcome models, while scikit-learn provides splitting, metrics, and cross-fitting utilities. The path logic searches upward for the processed interference files so the notebook works from JupyterLab or command-line execution.
# Set up environment and paths.from pathlib import Pathimport reimport warningsimport lightgbm as lgbimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport seaborn as snsimport xgboost as xgbfrom IPython.display import displayfrom sklearn.metrics import mean_absolute_error, mean_squared_error, r2_scorefrom sklearn.model_selection import StratifiedKFold, train_test_splitwarnings.filterwarnings("ignore", category=UserWarning)sns.set_theme(style="whitegrid", context="notebook")pd.set_option("display.max_columns", 140)pd.set_option("display.max_rows", 100)pd.set_option("display.float_format", lambda value: f"{value:,.4f}")candidate_roots = [Path.cwd(), *Path.cwd().parents]PROJECT_DIR =next( root for root in candidate_rootsif (root /"data"/"processed"/"movielens_interference_exposure_mapping.parquet").exists())PROCESSED_DIR = PROJECT_DIR /"data"/"processed"NOTEBOOK_DIR = PROJECT_DIR /"notebooks"/"interference_spillover_effects"EXPOSURE_PATH = PROCESSED_DIR /"movielens_interference_exposure_mapping.parquet"COMPONENT_SLATE_PATH = PROCESSED_DIR /"movielens_interference_component_slate.parquet"OBSERVED_EFFECTS_PATH = PROCESSED_DIR /"movielens_interference_observed_effects.csv"PRODUCT_SUMMARY_PATH = PROCESSED_DIR /"movielens_interference_product_summary.csv"EXPOSURE_PATH.exists(), COMPONENT_SLATE_PATH.exists(), OBSERVED_EFFECTS_PATH.exists(), PRODUCT_SUMMARY_PATH.exists()
(True, True, True, True)
All checks should return True. The advanced notebook builds on the exposure mapping, component slate table, prior randomized estimates, and product-unit decomposition created earlier. This keeps the analysis auditable: a reader can trace the final claim back to the exact table, figure, or markdown artifact that produced it.
2. Load Prior Outputs
This cell loads the item-row exposure table and the slate-level component table. The item-row table is used to construct pre-promotion slate features and reconstruct the known simulation lift. The slate-level table is used as the modeling unit because promotion was randomized at the slate level.
The product summary reminds us why advanced models are worth adding. The direct focal gain was positive, and competitor losses more than offset it. The advanced models will look for segments where that net effect is less negative or potentially positive.
3. Reconstruct the Known Counterfactual Promotion Lift
Because this is a simulation, we can reconstruct the expected outcome if every slate’s focal item were promoted. Real observational data would lack this oracle signal. Here it is useful for validating model predictions.
This cell rebuilds the same outcome mechanism used in the exposure-mapping notebook. It computes:
expected click probability under no promotion,
expected click probability if the focal item is promoted,
true expected net lift from promotion for every slate.
This gives us a benchmark for evaluating conditional-effect models and targeted promotion rules.
# Reconstruct the known counterfactual promotion lift.def sigmoid(values):""" Apply the logistic sigmoid transformation. Idea ---- The simulation uses this helper to convert latent utility or score values into probabilities for generated recommendation outcomes. Parameters ---------- values : object Numeric values to summarize. Returns ------- numpy.ndarray Values transformed to the interval from zero to one. """return1/ (1+ np.exp(-values))oracle_rows = exposure.copy()non_focal = oracle_rows["is_focal_item"].eq(0)same_cluster = oracle_rows["spillover_cluster"].eq(oracle_rows["focal_spillover_cluster"])would_be_displaced = non_focal & oracle_rows["slate_position_seed"].lt(oracle_rows["focal_seed_position"])oracle_rows["final_position_if_promoted"] = oracle_rows["slate_position_seed"]oracle_rows.loc[oracle_rows["is_focal_item"].eq(1), "final_position_if_promoted"] =1oracle_rows.loc[would_be_displaced, "final_position_if_promoted"] = oracle_rows.loc[would_be_displaced, "slate_position_seed"] +1oracle_rows["visibility_if_promoted"] =1/ np.log2(oracle_rows["final_position_if_promoted"] +1)liked_rate_mean = oracle_rows["liked_rate"].mean()item_liked_rate_mean = oracle_rows["sample_liked_rate"].mean()sample_liked_rate_filled = oracle_rows["sample_liked_rate"].fillna(item_liked_rate_mean)log_item_popularity_z_filled = oracle_rows["log_item_popularity_z"].fillna(0)promoted_logit = (-2.75+0.78* (oracle_rows["observed_relevance"] -3.5)+1.15* oracle_rows["visibility_if_promoted"]+0.35* (oracle_rows["liked_rate"] - liked_rate_mean)+0.25* (sample_liked_rate_filled - item_liked_rate_mean)+0.10* log_item_popularity_z_filled+0.20* oracle_rows["is_focal_item"]-0.08* non_focal.astype(float)-0.24* (non_focal & same_cluster).astype(float)-0.10* would_be_displaced.astype(float))oracle_rows["p_if_control"] = oracle_rows["p_no_promotion"]oracle_rows["p_if_promoted"] = sigmoid(promoted_logit).clip(0.01, 0.95)oracle_rows["true_item_lift_if_promoted"] = oracle_rows["p_if_promoted"] - oracle_rows["p_if_control"]oracle_slate_lift = ( oracle_rows.groupby("slate_id") .agg( true_promote_lift=("true_item_lift_if_promoted", "sum"), true_promote_expected_clicks=("p_if_promoted", "sum"), true_control_expected_clicks=("p_if_control", "sum"), ) .reset_index())promoted_validation = component_slate[["slate_id", "promotion_applied", "total_known_probability_lift"]].merge( oracle_slate_lift, on="slate_id", how="left",)promoted_validation["lift_difference_on_promoted_slates"] = np.where( promoted_validation["promotion_applied"].eq(1), promoted_validation["total_known_probability_lift"] - promoted_validation["true_promote_lift"], np.nan,)oracle_check = pd.DataFrame( {"check": ["mean_true_lift_if_all_promoted","median_true_lift_if_all_promoted","share_positive_true_lift","max_abs_difference_for_observed_promoted_slates", ],"value": [ promoted_validation["true_promote_lift"].mean(), promoted_validation["true_promote_lift"].median(), (promoted_validation["true_promote_lift"] >0).mean(), promoted_validation["lift_difference_on_promoted_slates"].abs().max(), ], })display(oracle_check)
check
value
0
mean_true_lift_if_all_promoted
-0.3158
1
median_true_lift_if_all_promoted
-0.3040
2
share_positive_true_lift
0.0000
3
max_abs_difference_for_observed_promoted_slates
0.0000
The validation difference for actually promoted slates should be essentially zero. That confirms the reconstructed oracle lift matches the earlier simulation. The share of positive true lift tells us whether targeted promotion is plausible because a model might learn to select slates with positive net value.
Model-Assisted Spillover Workflow
Build Slate-Level Modeling Features
This cell creates the modeling table. Only pre-promotion information is used as features: focal item relevance, focal starting position, user history features, slate composition, item popularity, and cluster composition. We intentionally avoid using post-treatment variables such as final position, visibility gain, observed known lift, or simulated probabilities as model features.
The modeling table has one row per randomized slate. The treatment flag is included as a feature for outcome modeling, while all other features describe what was known before the promotion was applied. The oracle lift is kept only for validation and policy evaluation.
5. Encode Features for Tree Models
Tree models need a numeric feature matrix. This cell one-hot encodes categorical variables such as focal cluster and popularity bucket, fills missing numeric values with medians, and sanitizes feature names so both LightGBM and XGBoost handle them cleanly.
# Encode features for tree models.numeric_features = ["promotion_applied","focal_seed_position","focal_observed_relevance","focal_high_relevance","log_focal_sample_rating_count","focal_sample_mean_rating","focal_sample_liked_rate","focal_log_item_popularity_z","log_user_n_ratings","mean_rating","liked_rate","active_years","unique_primary_genres","log_activity_span_days","slate_mean_relevance","slate_std_relevance","slate_high_relevance_rate","slate_mean_sample_liked_rate","slate_mean_log_popularity_z","slate_mean_baseline_visibility","same_cluster_competitor_count","displaced_candidate_count","same_cluster_displaced_count","same_cluster_share","displaced_share",]categorical_features = ["focal_spillover_cluster","focal_popularity_bucket","focal_position_bucket",]feature_frame = model_table[numeric_features + categorical_features].copy()for col in numeric_features: feature_frame[col] = pd.to_numeric(feature_frame[col], errors="coerce") feature_frame[col] = feature_frame[col].fillna(feature_frame[col].median())feature_frame[categorical_features] = feature_frame[categorical_features].astype("string").fillna("unknown")X = pd.get_dummies(feature_frame, columns=categorical_features, dtype=float)X.columns = [re.sub(r"[^A-Za-z0-9_]+", "_", col).strip("_") for col in X.columns]X = X.astype("float32")y = model_table["total_simulated_clicks"].astype("float32")treatment = model_table["promotion_applied"].astype("int8")feature_summary = pd.DataFrame( {"metric": ["rows", "features", "outcome_mean", "outcome_std", "treatment_rate"],"value": [len(X), X.shape[1], y.mean(), y.std(), treatment.mean()], })display(feature_summary)display(X.head())
metric
value
0
rows
3,000.0000
1
features
51.0000
2
outcome_mean
2.3727
3
outcome_std
1.4800
4
treatment_rate
0.5017
promotion_applied
focal_seed_position
focal_observed_relevance
focal_high_relevance
log_focal_sample_rating_count
focal_sample_mean_rating
focal_sample_liked_rate
focal_log_item_popularity_z
log_user_n_ratings
mean_rating
liked_rate
active_years
unique_primary_genres
log_activity_span_days
slate_mean_relevance
slate_std_relevance
slate_high_relevance_rate
slate_mean_sample_liked_rate
slate_mean_log_popularity_z
slate_mean_baseline_visibility
same_cluster_competitor_count
displaced_candidate_count
same_cluster_displaced_count
same_cluster_share
displaced_share
focal_spillover_cluster__no_genres_listed
focal_spillover_cluster_Action
focal_spillover_cluster_Adventure
focal_spillover_cluster_Animation
focal_spillover_cluster_Children
focal_spillover_cluster_Comedy
focal_spillover_cluster_Crime
focal_spillover_cluster_Documentary
focal_spillover_cluster_Drama
focal_spillover_cluster_Fantasy
focal_spillover_cluster_Film_Noir
focal_spillover_cluster_Horror
focal_spillover_cluster_Musical
focal_spillover_cluster_Mystery
focal_spillover_cluster_Romance
focal_spillover_cluster_Sci_Fi
focal_spillover_cluster_Thriller
focal_spillover_cluster_Western
focal_popularity_bucket_high
focal_popularity_bucket_low
focal_popularity_bucket_medium
focal_popularity_bucket_very_high
focal_popularity_bucket_very_low
focal_position_bucket_positions_10_12
focal_position_bucket_positions_5_6
focal_position_bucket_positions_7_9
0
1.0000
8.0000
4.0000
1.0000
5.2575
3.8665
0.6335
-0.1016
5.2883
2.7310
0.1675
2.0000
12.0000
6.1527
4.2083
0.3965
0.9167
0.6457
-0.3246
0.4244
1.0000
7.0000
0.0000
0.0909
0.6364
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
1.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
1.0000
0.0000
0.0000
0.0000
1.0000
1
0.0000
12.0000
4.0000
1.0000
5.7170
3.7129
0.5710
0.2245
5.1120
3.6303
0.6000
1.0000
11.0000
0.0000
4.4167
0.5149
1.0000
0.5528
0.0557
0.4244
2.0000
11.0000
2.0000
0.1818
1.0000
0.0000
1.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
1.0000
0.0000
1.0000
0.0000
0.0000
2
1.0000
5.0000
5.0000
1.0000
5.8289
3.0988
0.2596
0.3039
4.0604
2.6491
0.4035
1.0000
10.0000
0.0000
5.0000
0.0000
1.0000
0.5201
0.0627
0.4244
6.0000
4.0000
3.0000
0.5455
0.3636
0.0000
1.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
1.0000
0.0000
0.0000
1.0000
0.0000
3
0.0000
5.0000
5.0000
1.0000
5.3279
3.2439
0.3610
-0.0516
5.6419
3.8274
0.5623
3.0000
11.0000
7.4588
4.9167
0.1946
1.0000
0.5329
0.3683
0.4244
3.0000
4.0000
1.0000
0.2727
0.3636
0.0000
1.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
1.0000
0.0000
0.0000
1.0000
0.0000
4
0.0000
11.0000
5.0000
1.0000
6.6120
3.6588
0.5222
0.8596
5.2575
4.3063
0.8796
1.0000
10.0000
4.4067
4.9583
0.1443
1.0000
0.6079
0.2428
0.4244
6.0000
10.0000
6.0000
0.5455
0.9091
0.0000
1.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
0.0000
1.0000
0.0000
1.0000
0.0000
0.0000
The encoded feature matrix is compact enough for fast model training. The outcome is total simulated clicks per slate, which is the metric that respects interference because it includes both focal gains and competitor losses.
Train LightGBM and XGBoost Outcome Models
This cell trains two gradient-boosted tree models to predict total simulated slate clicks. The treatment indicator is included, so each model can learn how promotion changes outcomes conditional on slate features.
The train/test split is stratified by treatment assignment. That keeps promoted and control slates balanced in both samples.
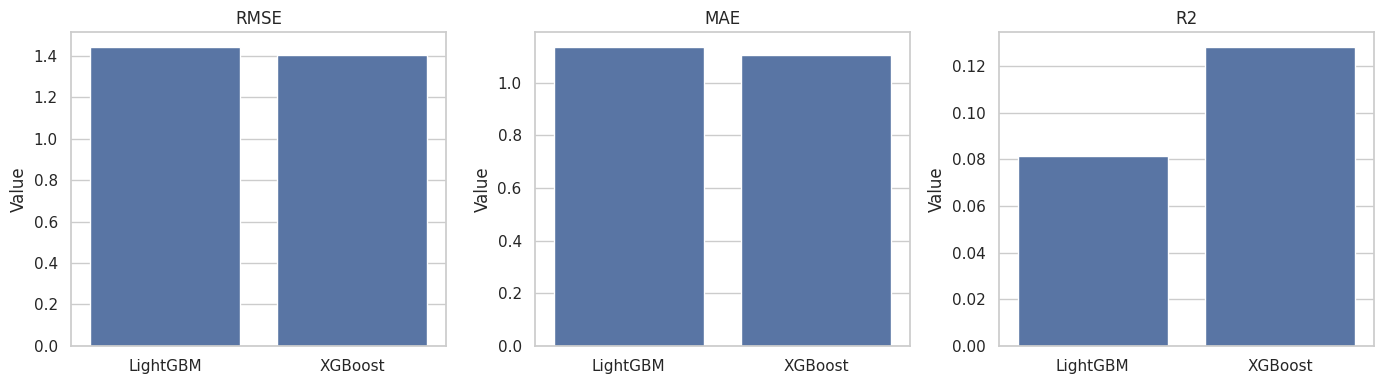
The metrics show how well flexible models predict slate-level outcomes. The goal is useful ranking of predicted lift under noisy clicks. The useful question is whether the model learns enough structure to identify slates where promotion is more or less harmful.
7. Plot Outcome Model Performance
This plot compares model performance on the held-out test set. RMSE and MAE are in clicks per slate; R-squared shows how much outcome variation the model explains.
The model comparison is a reality check. If the models cannot predict slate outcomes at all, policy targeting will be unreliable. If they predict moderately well, they may still be useful for ranking slates by expected net effect.
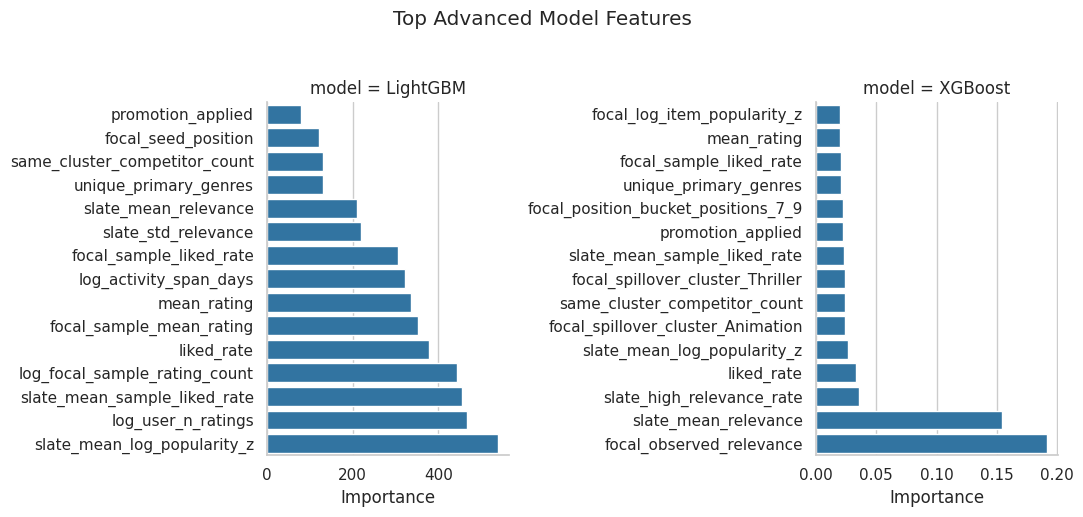
Inspect Feature Importance
This cell extracts feature importance from LightGBM and XGBoost. The goal is to see whether the models are using sensible variables such as treatment assignment, focal position, slate composition, user history, and substitute counts.
Feature importance helps audit the model. Sensible top features suggest the model is learning from pre-promotion slate structure. Treatment assignment and spillover-related features should matter if the model is capturing intervention effects.
9. Plot Top Feature Importance
The table above is dense, so this plot shows the top model features in a compact format. Each model gets its own panel.
# Plot top feature importance.g = sns.FacetGrid( top_importance, col="model", sharex=False, sharey=False, height=5, aspect=1.1,)def importance_barplot(data, **kwargs):""" Plot model feature importances for the spillover outcome model. Idea ---- The figure shows which slate, item, and exposure features drive predicted net promotion value in the advanced interference workflow. Parameters ---------- data : object Input analysis table for the current project step. Returns ------- matplotlib.axes.Axes Axis containing the feature-importance bar plot. """ ordered = data.sort_values("importance", ascending=True) ax = plt.gca() sns.barplot(data=ordered, x="importance", y="feature", ax=ax, color="tab:blue") ax.set_xlabel("Importance") ax.set_ylabel("")g.map_dataframe(importance_barplot)g.fig.suptitle("Top Advanced Model Features", y=1.03)plt.tight_layout()plt.show()
The feature plot is useful for communication because it shows which pre-promotion properties drive the model’s predictions. If focal position, relevance, and competitor counts appear, the model is aligned with the interference mechanism we care about.
Generate Counterfactual Predictions
This cell uses each trained outcome model to predict two potential outcomes for every slate:
predicted total clicks if the focal item is promoted,
predicted total clicks if the slate is left unchanged.
The difference between those predictions is a model-estimated conditional net effect. Because this is a simulation, we can compare that estimate with the reconstructed true expected promotion lift.
# Generate counterfactual predictions.def counterfactual_feature_matrix(X_base, treatment_value):""" Create a counterfactual feature matrix with promotion fixed. Idea ---- The helper copies slate-level model features and sets promotion exposure to treatment or control so model-assisted contrasts can be predicted. Parameters ---------- X_base : object Base feature matrix before counterfactual edits. treatment_value : object Counterfactual treatment value to assign. Returns ------- pandas.DataFrame Feature matrix under the requested counterfactual promotion state. """ X_cf = X_base.copy() X_cf["promotion_applied"] =float(treatment_value)return X_cfcounterfactual_predictions = model_table[ ["slate_id","userId","promotion_applied","focal_seed_position","focal_spillover_cluster","total_simulated_clicks","true_promote_lift", ]].copy()X_promote = counterfactual_feature_matrix(X, 1)X_control = counterfactual_feature_matrix(X, 0)counterfactual_summary_rows = []for model_name, model in trained_models.items(): pred_promote = model.predict(X_promote) pred_control = model.predict(X_control) pred_lift = pred_promote - pred_control counterfactual_predictions[f"pred_promote_clicks_{model_name}"] = pred_promote counterfactual_predictions[f"pred_control_clicks_{model_name}"] = pred_control counterfactual_predictions[f"pred_net_lift_{model_name}"] = pred_lift counterfactual_summary_rows.append( {"model": model_name,"mean_predicted_lift": pred_lift.mean(),"median_predicted_lift": np.median(pred_lift),"share_predicted_positive": (pred_lift >0).mean(),"true_mean_lift": counterfactual_predictions["true_promote_lift"].mean(),"cate_rmse_vs_oracle": np.sqrt(mean_squared_error(counterfactual_predictions["true_promote_lift"], pred_lift)),"cate_mae_vs_oracle": mean_absolute_error(counterfactual_predictions["true_promote_lift"], pred_lift),"cate_correlation_vs_oracle": np.corrcoef(counterfactual_predictions["true_promote_lift"], pred_lift)[0, 1], } )counterfactual_summary = pd.DataFrame(counterfactual_summary_rows).sort_values("cate_rmse_vs_oracle")selected_cate_model = counterfactual_summary.iloc[0]["model"]selected_cate_col =f"pred_net_lift_{selected_cate_model}"display(counterfactual_summary)print(f"Selected CATE model by oracle RMSE: {selected_cate_model}")
model
mean_predicted_lift
median_predicted_lift
share_predicted_positive
true_mean_lift
cate_rmse_vs_oracle
cate_mae_vs_oracle
cate_correlation_vs_oracle
1
XGBoost
-0.2388
-0.2361
0.0100
-0.3158
0.1610
0.1244
0.0189
0
LightGBM
-0.2269
-0.2113
0.1267
-0.3158
0.2481
0.1967
0.0491
Selected CATE model by oracle RMSE: XGBoost
The oracle comparison is only possible because this is a simulation. A good advanced model should at least rank slates in the right direction, even if the exact predicted lift is noisy. The selected model will be used for policy targeting below.
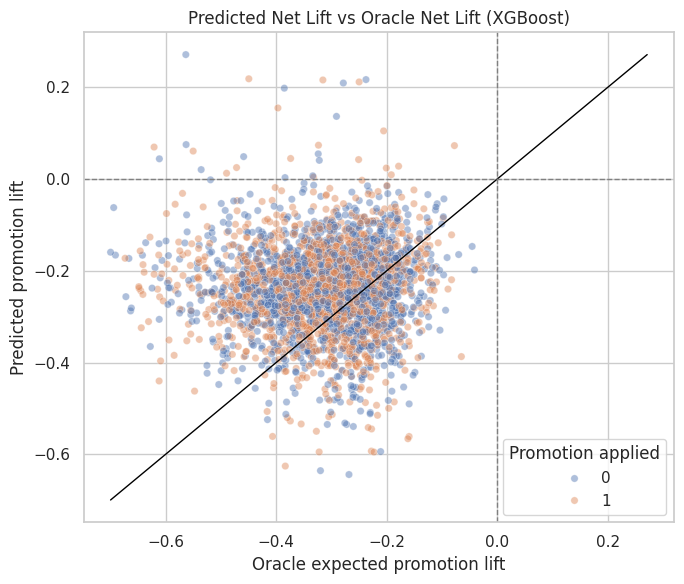
11. Plot Predicted Net Lift Against Oracle Net Lift
This scatter plot shows whether the selected model can identify slates with less harmful or more beneficial promotion effects. The diagonal line represents perfect prediction.
The scatter plot should be read as a targeting diagnostic for prioritizing safer promotions. The key question is whether higher predicted lift corresponds to higher oracle lift. If it does, the model can help prioritize safer promotions.
Cross-Fitted Model-Assisted AIPW Estimate
Even though assignment is randomized, we can use outcome models to build a model-assisted estimator. This cell fits separate LightGBM outcome models for treated and control slates using cross-fitting, then computes an augmented inverse probability weighted estimate.
The treatment probability is known: promotion was randomized with probability 0.5. Cross-fitting keeps each slate’s nuisance predictions out of sample.
# Cross-fitted model-assisted AIPW estimate.def make_aipw_model(seed):""" Build a model used in the model-assisted AIPW spillover workflow. Idea ---- The helper configures a learner with a fixed seed so advanced interference estimates can be reproduced and compared across runs. Parameters ---------- seed : object Random seed for reproducible modeling or resampling. Returns ------- sklearn estimator Configured model for nuisance prediction or effect modeling. """return lgb.LGBMRegressor( n_estimators=250, learning_rate=0.04, num_leaves=15, min_child_samples=20, subsample=0.9, colsample_bytree=0.9, random_state=seed, verbose=-1, )N_SPLITS =5PROPENSITY =0.5skf = StratifiedKFold(n_splits=N_SPLITS, shuffle=True, random_state=RANDOM_SEED)m1_hat = np.zeros(len(model_table), dtype=float)m0_hat = np.zeros(len(model_table), dtype=float)fold_id = np.zeros(len(model_table), dtype=int)for fold, (train_positions, holdout_positions) inenumerate(skf.split(X, treatment), start=1): X_train_fold = X.iloc[train_positions] y_train_fold = y.iloc[train_positions] t_train_fold = treatment.iloc[train_positions] model_treated = make_aipw_model(RANDOM_SEED + fold) model_control = make_aipw_model(RANDOM_SEED +100+ fold) model_treated.fit(X_train_fold.loc[t_train_fold.eq(1)], y_train_fold.loc[t_train_fold.eq(1)]) model_control.fit(X_train_fold.loc[t_train_fold.eq(0)], y_train_fold.loc[t_train_fold.eq(0)]) m1_hat[holdout_positions] = model_treated.predict(counterfactual_feature_matrix(X.iloc[holdout_positions], 1)) m0_hat[holdout_positions] = model_control.predict(counterfactual_feature_matrix(X.iloc[holdout_positions], 0)) fold_id[holdout_positions] = foldobserved_y = y.to_numpy(dtype=float)observed_t = treatment.to_numpy(dtype=float)model_assisted_scores = ( (m1_hat - m0_hat)+ observed_t / PROPENSITY * (observed_y - m1_hat)- (1- observed_t) / (1- PROPENSITY) * (observed_y - m0_hat))simple_difference = observed_y[observed_t ==1].mean() - observed_y[observed_t ==0].mean()aipw_estimate = model_assisted_scores.mean()aipw_se = model_assisted_scores.std(ddof=1) / np.sqrt(len(model_assisted_scores))model_assisted_table = pd.DataFrame( [ {"estimator": "Randomized difference in means","estimate": simple_difference,"se": np.nan,"ci_95_lower": np.nan,"ci_95_upper": np.nan,"reference": "Observed total simulated clicks", }, {"estimator": "Cross-fitted LightGBM AIPW","estimate": aipw_estimate,"se": aipw_se,"ci_95_lower": aipw_estimate -1.96* aipw_se,"ci_95_upper": aipw_estimate +1.96* aipw_se,"reference": "Observed total simulated clicks", }, {"estimator": "Oracle mean promotion lift","estimate": model_table["true_promote_lift"].mean(),"se": model_table["true_promote_lift"].std(ddof=1) / np.sqrt(len(model_table)),"ci_95_lower": model_table["true_promote_lift"].mean() -1.96* model_table["true_promote_lift"].std(ddof=1) / np.sqrt(len(model_table)),"ci_95_upper": model_table["true_promote_lift"].mean() +1.96* model_table["true_promote_lift"].std(ddof=1) / np.sqrt(len(model_table)),"reference": "Known simulation lift", }, ])counterfactual_predictions["crossfit_m1_hat"] = m1_hatcounterfactual_predictions["crossfit_m0_hat"] = m0_hatcounterfactual_predictions["crossfit_cate_lgbm"] = m1_hat - m0_hatcounterfactual_predictions["aipw_score"] = model_assisted_scorescounterfactual_predictions["fold_id"] = fold_iddisplay(model_assisted_table)
estimator
estimate
se
ci_95_lower
ci_95_upper
reference
0
Randomized difference in means
-0.3078
NaN
NaN
NaN
Observed total simulated clicks
1
Cross-fitted LightGBM AIPW
-0.3036
0.0505
-0.4024
-0.2047
Observed total simulated clicks
2
Oracle mean promotion lift
-0.3158
0.0019
-0.3195
-0.3120
Known simulation lift
The AIPW estimator is a robustness check. Because the design is randomized, the simple difference-in-means is already valid. The model-assisted estimate asks whether flexible outcome models produce a similar average answer while also generating useful conditional-effect predictions.
Model-Targeted Promotion Policies
This cell compares several targeting rules using the selected model’s predicted net lift. Since this is a simulation, the policies are evaluated using oracle expected promotion lift. In a real setting, this would require an online experiment or a valid off-policy evaluation design.
The table reports both value per selected slate and value per 1,000 eligible slates. The second metric accounts for how many slates the policy chooses to promote.
The targeting table shows whether the model can reduce harm by avoiding slates with strongly negative predicted net lift. The oracle benchmark shows the value available if targeting were perfect.
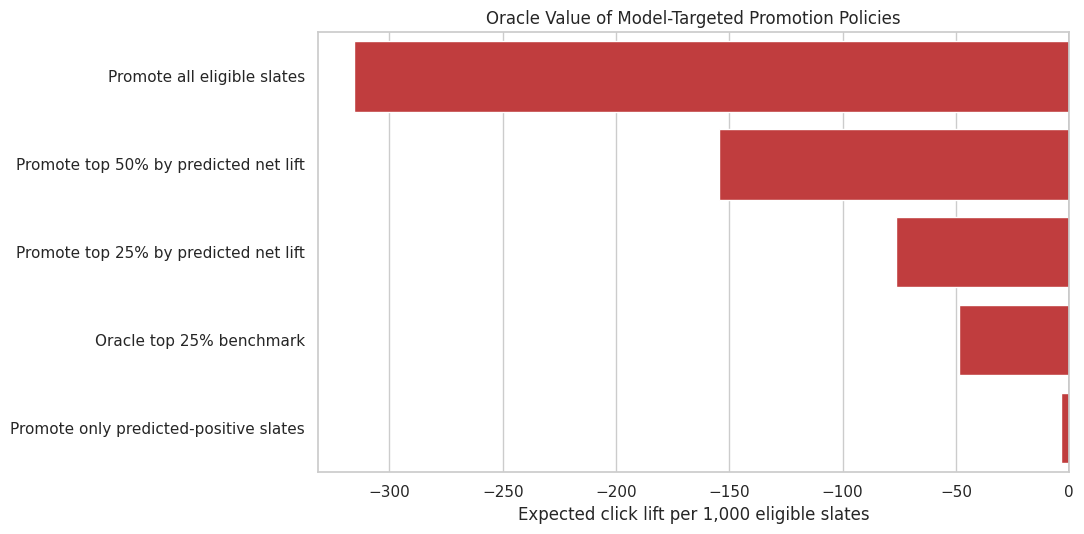
14. Plot Policy Targeting Results
This plot compares the net oracle value of each promotion rule. The value is shown per 1,000 eligible slates, so policies that promote fewer slates are penalized for lower coverage.
policy_plot = policy_targeting.sort_values("oracle_lift_per_1000_eligible_slates", ascending=True).copy()fig, ax = plt.subplots(figsize=(11, 5.5))colors = ["tab:green"if value >=0else"tab:red"for value in policy_plot["oracle_lift_per_1000_eligible_slates"]]sns.barplot( data=policy_plot, x="oracle_lift_per_1000_eligible_slates", y="policy", hue="policy", palette=dict(zip(policy_plot["policy"], colors)), legend=False, ax=ax,)ax.axvline(0, color="black", linewidth=1)ax.set_title("Oracle Value of Model-Targeted Promotion Policies")ax.set_xlabel("Expected click lift per 1,000 eligible slates")ax.set_ylabel("")plt.tight_layout()plt.show()
The policy plot translates advanced modeling into a decision question. If targeted rules are less negative than promoting all slates, the model is useful for reducing harm. The safest policy may still be to avoid promotion unless predicted net value is positive.
Heterogeneity Diagnostics
This cell summarizes true and predicted net lift across interpretable segments: focal starting position, substitute count, displaced count, user activity, and focal cluster. The goal is to connect ML predictions back to product reasoning.
# Heterogeneity diagnostics.heterogeneity_frame = model_table[ ["slate_id","focal_seed_position","focal_position_bucket","focal_spillover_cluster","same_cluster_competitor_count","displaced_candidate_count","n_ratings","true_promote_lift", ]].merge( policy_scores[["slate_id", "selected_model_predicted_lift"]], on="slate_id", how="left",)heterogeneity_frame["same_cluster_count_bucket"] = pd.cut( heterogeneity_frame["same_cluster_competitor_count"], bins=[-0.1, 0, 2, 5, 11], labels=["0", "1-2", "3-5", "6+"],)heterogeneity_frame["displaced_count_bucket"] = pd.cut( heterogeneity_frame["displaced_candidate_count"], bins=[-0.1, 4, 7, 11], labels=["4_or_fewer", "5-7", "8+"],)heterogeneity_frame["user_activity_bucket"] = pd.qcut( heterogeneity_frame["n_ratings"].rank(method="first"), q=4, labels=["lowest_activity", "low_mid_activity", "high_mid_activity", "highest_activity"],)def summarize_segment(frame, segment_type, segment_column, min_slates=30):""" Summarize predicted net lift within an interference segment. Idea ---- The helper aggregates model-predicted treatment contrasts by item, genre, position, or slate segment to identify safer promotion regions. Parameters ---------- frame : object Input analysis table for the current project step. segment_type : object Label describing the segment family. segment_column : object Column defining the segment to summarize. min_slates : object Minimum slates required to keep a segment. Returns ------- dict Segment summary with counts and average predicted net lift. """ summary = ( frame.groupby(segment_column, observed=True) .agg( slates=("slate_id", "size"), mean_true_lift=("true_promote_lift", "mean"), mean_predicted_lift=("selected_model_predicted_lift", "mean"), share_positive_true_lift=("true_promote_lift", lambda s: (s >0).mean()), ) .reset_index() .rename(columns={segment_column: "segment"}) ) summary = summary.query("slates >= @min_slates").copy() summary["segment_type"] = segment_typereturn summaryheterogeneity_summaries = pd.concat( [ summarize_segment(heterogeneity_frame, "focal_position_bucket", "focal_position_bucket"), summarize_segment(heterogeneity_frame, "same_cluster_count_bucket", "same_cluster_count_bucket"), summarize_segment(heterogeneity_frame, "displaced_count_bucket", "displaced_count_bucket"), summarize_segment(heterogeneity_frame, "user_activity_bucket", "user_activity_bucket"), summarize_segment(heterogeneity_frame, "focal_cluster", "focal_spillover_cluster", min_slates=60), ], ignore_index=True,)heterogeneity_summaries = heterogeneity_summaries.sort_values(["segment_type", "mean_true_lift"])display(heterogeneity_summaries)
segment
slates
mean_true_lift
mean_predicted_lift
share_positive_true_lift
segment_type
9
8+
1472
-0.3478
-0.2735
0.0000
displaced_count_bucket
8
5-7
1162
-0.2961
-0.2121
0.0000
displaced_count_bucket
7
4_or_fewer
366
-0.2493
-0.1842
0.0000
displaced_count_bucket
14
Action
799
-0.3625
-0.2154
0.0000
focal_cluster
17
Comedy
658
-0.3258
-0.2348
0.0000
focal_cluster
19
Drama
636
-0.3221
-0.2426
0.0000
focal_cluster
15
Adventure
318
-0.2784
-0.2439
0.0000
focal_cluster
18
Crime
253
-0.2725
-0.2623
0.0000
focal_cluster
16
Animation
70
-0.2496
-0.2290
0.0000
focal_cluster
20
Horror
65
-0.2378
-0.2969
0.0000
focal_cluster
2
positions_10_12
1086
-0.3535
-0.2775
0.0000
focal_position_bucket
1
positions_7_9
1168
-0.3119
-0.2362
0.0000
focal_position_bucket
0
positions_5_6
746
-0.2668
-0.1867
0.0000
focal_position_bucket
6
6+
427
-0.4598
-0.2174
0.0000
same_cluster_count_bucket
5
3-5
1006
-0.3471
-0.2264
0.0000
same_cluster_count_bucket
4
1-2
1023
-0.2729
-0.2280
0.0000
same_cluster_count_bucket
3
0
544
-0.2253
-0.2990
0.0000
same_cluster_count_bucket
10
lowest_activity
750
-0.3386
-0.2512
0.0000
user_activity_bucket
11
low_mid_activity
750
-0.3327
-0.2277
0.0000
user_activity_bucket
12
high_mid_activity
750
-0.3145
-0.2338
0.0000
user_activity_bucket
13
highest_activity
750
-0.2772
-0.2426
0.0000
user_activity_bucket
The heterogeneity table makes the targeting story interpretable. Segments with less negative or positive true lift are safer promotion candidates. Segments with many substitutes or large displacement exposure are more likely to show negative net effects.
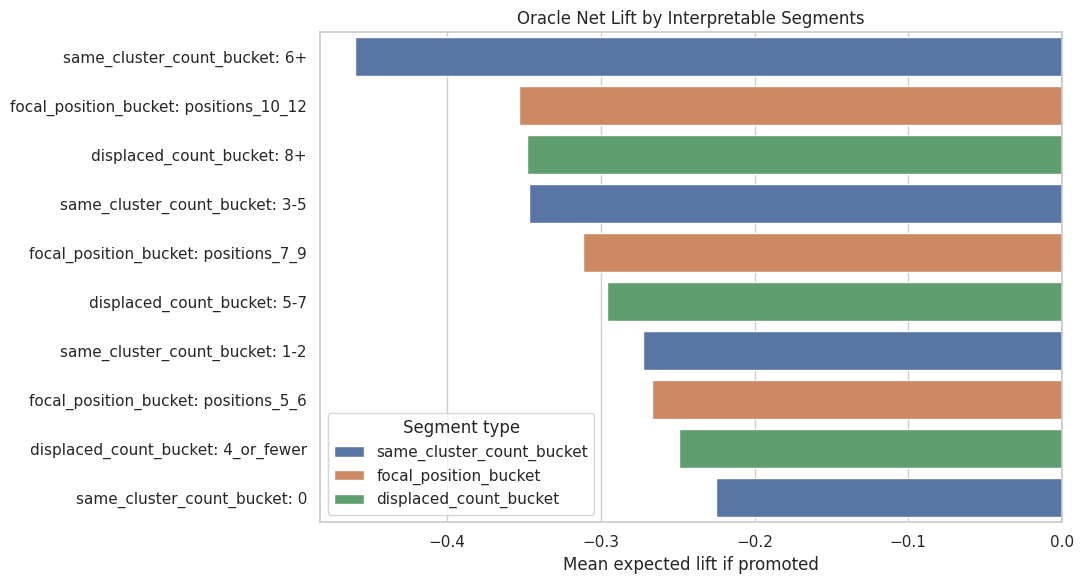
16. Plot Interpretable Heterogeneity
This plot focuses on the most actionable segment types: focal starting position and same-cluster competitor count. These are directly tied to the mechanism of item competition.
heterogeneity_plot = heterogeneity_summaries.query("segment_type in ['focal_position_bucket', 'same_cluster_count_bucket', 'displaced_count_bucket']").copy()heterogeneity_plot["segment_label"] = heterogeneity_plot["segment_type"] +": "+ heterogeneity_plot["segment"].astype(str)fig, ax = plt.subplots(figsize=(11, 6))sns.barplot( data=heterogeneity_plot.sort_values("mean_true_lift"), x="mean_true_lift", y="segment_label", hue="segment_type", dodge=False, ax=ax,)ax.axvline(0, color="black", linewidth=1)ax.set_title("Oracle Net Lift by Interpretable Segments")ax.set_xlabel("Mean expected lift if promoted")ax.set_ylabel("")ax.legend(title="Segment type")plt.tight_layout()plt.show()
The segment plot connects advanced modeling back to recommendation design. If promotions are most harmful in slates with many displaced or same-cluster competitors, then safer policies should account for local slate competition before promoting an item.
Advanced Modeling Takeaways Table
This cell creates a compact summary table showing what the advanced models added beyond the transparent randomized estimators.
# Advanced modeling takeaways table.best_metrics = model_metrics.query("split == 'test' and model == @best_model_name").iloc[0]best_counterfactual = counterfactual_summary.query("model == @selected_cate_model").iloc[0]best_policy = policy_targeting.sort_values("oracle_lift_per_1000_eligible_slates", ascending=False).iloc[0]advanced_takeaways = pd.DataFrame( [ {"area": "Outcome modeling","finding": f"{best_model_name} had the best held-out RMSE at {best_metrics['rmse']:.3f} clicks per slate.","why_it_matters": "Flexible models can summarize how slate composition and treatment assignment relate to total outcomes.", }, {"area": "Conditional effects","finding": f"{selected_cate_model} had CATE RMSE {best_counterfactual['cate_rmse_vs_oracle']:.3f} versus the oracle simulation lift.","why_it_matters": "The model can be used to rank slates by predicted net harm or benefit, with simulation validation.", }, {"area": "Model-assisted estimation","finding": f"Cross-fitted AIPW estimated {aipw_estimate:.3f} total clicks per slate, compared with {simple_difference:.3f} from the randomized difference-in-means.","why_it_matters": "Model-assisted estimates should agree with the randomized baseline before being used for targeting.", }, {"area": "Policy targeting","finding": f"The best evaluated policy was '{best_policy['policy']}' with {best_policy['oracle_lift_per_1000_eligible_slates']:.1f} oracle lift per 1,000 eligible slates.","why_it_matters": "Targeting can reduce displacement harm compared with promoting every eligible slate.", }, ])display(advanced_takeaways)
area
finding
why_it_matters
0
Outcome modeling
XGBoost had the best held-out RMSE at 1.405 cl...
Flexible models can summarize how slate compos...
1
Conditional effects
XGBoost had CATE RMSE 0.161 versus the oracle ...
The model can be used to rank slates by predic...
2
Model-assisted estimation
Cross-fitted AIPW estimated -0.304 total click...
Model-assisted estimates should agree with the...
3
Policy targeting
The best evaluated policy was 'Promote only pr...
Targeting can reduce displacement harm compare...
This table keeps the advanced work concrete: model performance, conditional-effect validation, model-assisted estimation, and policy targeting. This matters because the causal estimate is built from these supporting predictions, so weak nuisance behavior should make the downstream effect estimate less persuasive.
The saved files complete the advanced-modeling handoff. The key artifacts are the counterfactual predictions, AIPW estimate table, policy targeting table, and advanced takeaways. This keeps the analysis auditable: a reader can trace the final claim back to the exact table, figure, or markdown artifact that produced it.
Takeaways and Next Step
This notebook added advanced modeling without changing the causal foundation:
LightGBM and XGBoost were trained to predict total slate outcomes from pre-promotion features and treatment assignment.
Counterfactual predictions estimated conditional net promotion effects for each slate.
A cross-fitted model-assisted AIPW estimate was compared with the simple randomized estimator.
Targeted promotion rules were evaluated against the oracle simulation lift.
Heterogeneity summaries showed where promotion is most likely to be safer or more harmful.
The lab now has a complete workflow covering dataset setup, exposure mapping, randomized estimators, direct/indirect/total decomposition, advanced models, assumptions, limitations, figures, tables, and decision-oriented interpretation.