03: Cluster-Randomized Estimators for Direct and Spillover Effects
This notebook is the first causal estimation notebook in the interference and spillover workflow.
The previous notebook created a randomized promotion simulation from MovieLens seed slates. In each slate, one lower-ranked focal movie was selected, and the slate was randomized to either promote that focal movie or leave the slate unchanged. That gives us a clean assignment mechanism:
the randomized unit is the slate,
the directly treated unit is the promoted focal movie,
the spillover-exposed units are the other movies in a promoted slate,
the strongest spillover candidates are movies in the same genre-based substitute cluster as the promoted focal movie,
the total effect is measured at the slate level because gains and losses happen inside the same attention budget.
The goal here is to estimate what changed when promotion was randomized:
Direct focal effect: what happens to the promoted movie?
Same-cluster spillover effect: what happens to substitute movies in the same slate?
Displaced-item spillover effect: what happens to items that are pushed down by promotion?
Total slate effect: what happens to total slate engagement after combining gains and losses?
Because treatment is assigned at the slate level, uncertainty should respect slate clustering. The notebook therefore compares naive standard errors with slate-clustered standard errors and also uses a cluster bootstrap as a non-parametric check.
Dataset and Simulation Design Context
This project uses MovieLens 32M as a realistic user-item preference source. MovieLens contains ratings and movie metadata, but it lacks production recommendation impressions, randomized promotions, and observed slate outcomes.
Because the public data lack a real experiment, the project builds a transparent simulation. It constructs recommendation slates, selects lower-ranked focal movies, randomizes focal promotion at the slate level, and generates outcomes through an explicit competition model.
The simulated experiment is designed to teach interference. Promoting one item can increase that item’s engagement while reducing attention for substitutes and neighboring items. The estimands are direct focal effects, spillover effects, and total slate value, so the project emphasizes experiment design and measurement logic as a teaching workflow.
Role of this notebook. This notebook estimates direct and slate-level effects under the simulated randomized assignment and compares estimates with known simulation truth.
Mathematical Setup
Cluster randomization assigns treatment at the group level to reduce spillover contamination. For cluster (c), let (Z_c) be the randomized assignment and (Y_c) the cluster mean outcome. A simple cluster-level difference in means is
Because items inside a cluster are related, uncertainty should respect the assignment level. That is why this notebook compares naive uncertainty with cluster-robust or cluster-bootstrap uncertainty.
1. Environment and Paths
This cell imports the estimation, plotting, and table tools used in the notebook. It also finds the repository root by searching upward for the exposure mapping file, which keeps the notebook robust across Jupyter and command-line execution.
# Set up environment and paths.from pathlib import Pathimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport seaborn as snsimport statsmodels.api as smfrom IPython.display import displaysns.set_theme(style="whitegrid", context="notebook")pd.set_option("display.max_columns", 120)pd.set_option("display.max_rows", 100)pd.set_option("display.float_format", lambda value: f"{value:,.4f}")candidate_roots = [Path.cwd(), *Path.cwd().parents]PROJECT_DIR =next( root for root in candidate_rootsif (root /"data"/"processed"/"movielens_interference_exposure_mapping.parquet").exists())PROCESSED_DIR = PROJECT_DIR /"data"/"processed"NOTEBOOK_DIR = PROJECT_DIR /"notebooks"/"interference_spillover_effects"EXPOSURE_PATH = PROCESSED_DIR /"movielens_interference_exposure_mapping.parquet"SLATE_OUTCOME_PATH = PROCESSED_DIR /"movielens_interference_slate_outcomes.parquet"ASSIGNMENT_PATH = PROCESSED_DIR /"movielens_interference_assignment_table.parquet"EXPOSURE_PATH.exists(), SLATE_OUTCOME_PATH.exists(), ASSIGNMENT_PATH.exists()
(True, True, True)
All three checks should be True. The notebook depends on the item-row exposure table, the slate-level outcome table, and the focal assignment table produced in the previous notebook.
2. Load the Randomized Exposure Data
This cell loads the analysis-ready data. The item-row table is used for direct and spillover contrasts, while the slate-level table is used for total-effect estimates. The assignment table is useful for checking that the randomized design is still intact.
The row counts should line up with the previous notebook: 36,000 item rows and 3,000 slates. This confirms that every estimator in this notebook is working from the same randomized experiment simulation.
Estimation Workflow
Recheck the Randomized Assignment
Before estimating effects, we recheck the promotion rate and the number of treated/control slates. This is a quick guard against accidental filtering that could break the randomized design.
The promoted and control arms should be nearly equal in size. Focal seed position and focal relevance should also be close across arms because promotion was randomized after focal item selection.
4. Define Estimation Helpers
This cell defines reusable functions for difference-in-means estimation. The basic estimator is a regression of an outcome on the randomized treatment indicator. For row-level item outcomes, standard errors are clustered by slate because all item rows in the same slate share the same randomized assignment and attention budget.
The helper returns both naive and cluster-robust uncertainty so we can see how much clustering matters.
def difference_in_means( data, outcome, treatment="promotion_applied", cluster_col="slate_id", contrast_name=None, outcome_label=None,):# Estimate treated-control mean difference with naive and clustered uncertainty.""" Estimate a randomized treated-control difference in means. Idea ---- The helper compares promoted and control slates or items for one outcome and records the contrast used in the interference simulation. Parameters ---------- data : object Input analysis table for the current project step. outcome : object Outcome column used in the contrast. treatment : object Treatment indicator column or treatment values. cluster_col : object Cluster identifier used for grouped bootstrap or summaries. contrast_name : object Readable name of the treatment contrast. outcome_label : object Readable name of the outcome being contrasted. Returns ------- dict Difference-in-means estimate with group means and metadata. """ columns = [outcome, treatment]if cluster_col isnotNone: columns.append(cluster_col) work = data[columns].dropna().copy() work[treatment] = work[treatment].astype(float) work[outcome] = work[outcome].astype(float) treated = work.loc[work[treatment] ==1, outcome] control = work.loc[work[treatment] ==0, outcome]if treated.empty or control.empty:raiseValueError(f"Both treatment arms are required for {contrast_name} / {outcome}.") x = sm.add_constant(work[treatment], has_constant="add") y = work[outcome] naive_fit = sm.OLS(y, x).fit() coef =float(naive_fit.params[treatment]) naive_se =float(naive_fit.bse[treatment])if cluster_col isnotNone: cluster_fit = sm.OLS(y, x).fit( cov_type="cluster", cov_kwds={"groups": work[cluster_col]}, ) cluster_se =float(cluster_fit.bse[treatment]) p_value =float(cluster_fit.pvalues[treatment]) clusters = work[cluster_col].nunique()else: cluster_se = naive_se p_value =float(naive_fit.pvalues[treatment]) clusters = np.nanreturn {"contrast": contrast_name or outcome,"outcome": outcome_label or outcome,"estimate": coef,"naive_se": naive_se,"cluster_se": cluster_se,"ci_95_lower": coef -1.96* cluster_se,"ci_95_upper": coef +1.96* cluster_se,"p_value_cluster": p_value,"treated_mean": treated.mean(),"control_mean": control.mean(),"treated_n": len(treated),"control_n": len(control),"clusters": clusters, }def cluster_bootstrap_difference( data, outcome, treatment="promotion_applied", cluster_col="slate_id", n_bootstrap=500, seed=20260428,):# Resample whole slates, then recompute the treated-control mean difference.""" Bootstrap a difference in means by cluster. Idea ---- The bootstrap resamples slates or clusters so uncertainty reflects the experimental assignment structure. Parameters ---------- data : object Input analysis table for the current project step. outcome : object Outcome column used in the contrast. treatment : object Treatment indicator column or treatment values. cluster_col : object Cluster identifier used for grouped bootstrap or summaries. n_bootstrap : object Number of bootstrap resamples. seed : object Random seed for reproducible modeling or resampling. Returns ------- pandas.DataFrame Bootstrap draws or summary statistics for the treatment contrast. """ work = data[[outcome, treatment, cluster_col]].dropna().reset_index(drop=True).copy() work[treatment] = work[treatment].astype(int) work[outcome] = work[outcome].astype(float) clusters = work[cluster_col].drop_duplicates().to_numpy() group_positions = work.groupby(cluster_col).indices rng = np.random.default_rng(seed) estimates = []for _ inrange(n_bootstrap): sampled_clusters = rng.choice(clusters, size=len(clusters), replace=True) sampled_positions = np.concatenate([group_positions[cluster] for cluster in sampled_clusters]) sample = work.iloc[sampled_positions] treated = sample.loc[sample[treatment] ==1, outcome] control = sample.loc[sample[treatment] ==0, outcome]if treated.empty or control.empty: estimates.append(np.nan)else: estimates.append(treated.mean() - control.mean())return np.asarray(estimates, dtype=float)
These helpers keep the estimation cells readable. The estimates are still simple difference-in-means estimators, but the implementation respects the randomized unit and returns enough diagnostic information to explain the uncertainty.
Define the Main Causal Contrasts
This cell creates the datasets for each contrast.
Direct focal effect uses only focal-item rows and compares promoted focal items with control focal items.
Same-cluster spillover effect uses non-focal movies in the same cluster as the focal movie. In promoted slates, these are substitute competitors exposed to spillover; in control slates, they are comparable substitute competitors without promotion.
Displaced-item spillover effect uses non-focal items that start above the focal item and therefore would be pushed down if the focal item is promoted.
All non-focal spillover effect looks at every non-focal item in promoted versus control slates.
Total slate effect uses one row per slate and measures the net outcome across all slate items.
The contrast summary shows how much support each estimator has. The same-cluster and displaced-item contrasts have many rows, and the randomized clusters are still slates. That is why the later standard errors are clustered by slate_id.
Estimate Direct, Spillover, and Total Effects
This cell estimates each contrast for three outcome views:
Observed simulated outcome: the noisy simulated click outcome generated in the previous notebook.
Expected probability outcome: the simulation’s expected click probability, which removes Bernoulli noise.
Known induced lift: the known probability change introduced by the promotion and spillover simulation.
The noisy outcome is what a real logged experiment would look like. The expected and known-lift outcomes are validation views available because this is a simulation.
The signs should tell the main story: promoted focal items gain, substitute or displaced competitors lose, and the total slate effect can be smaller than the direct gain because attention is reallocated. The cluster-to-naive standard error ratio shows whether row-level uncertainty would have been too optimistic.
7. Focus on the Noisy Observed Outcomes
The previous table includes validation outcomes that we only have because the data are simulated. This cell extracts the noisy observed-outcome estimates, which are the closest analogue to what we would report from a real randomized experiment.
This table is the clean experiment-style result. The direct effect is the promoted focal item’s gain. The spillover rows measure competitor losses. The total slate row tells us whether the promotion helped the whole slate after accounting for displacement.
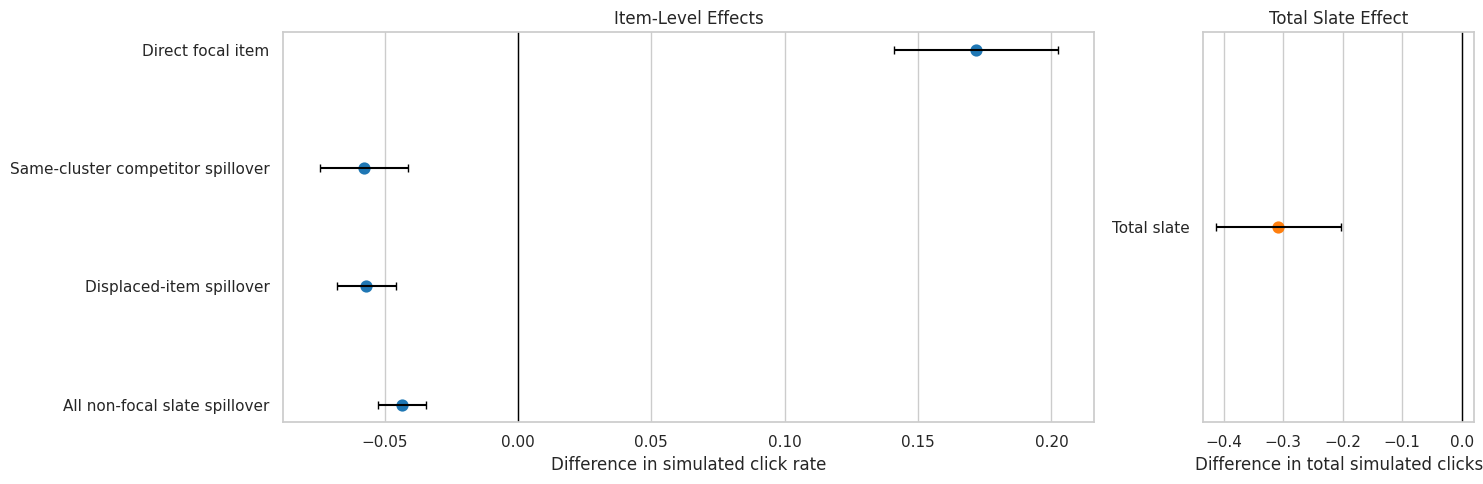
8. Plot Observed Estimates with Cluster-Robust Intervals
This plot shows the main observed estimates with 95 percent intervals using slate-clustered standard errors. Item-level and slate-level outcomes use different units, so the plot is split into item-row effects and total-slate effects.
The plot makes the direct-versus-spillover tradeoff visible. A promotion can increase the focal item’s click chance while decreasing competitor outcomes. The total slate estimate is the product-level summary because it combines both sides of that tradeoff.
Compare Estimates to Known Simulation Truth
Because this is a simulation, we have two extra validation signals:
the expected probability estimate, which removes random click noise;
the known induced lift estimate, which isolates the lift created by the treatment and spillover mechanism.
This cell reshapes the results so each contrast can compare noisy observed estimates against the known simulation signal.
# Compare observed estimates to known simulation truth.validation_table = estimate_table.pivot_table( index="contrast", columns="outcome", values="estimate", aggfunc="first",).reset_index()validation_table = validation_table.rename( columns={"Observed simulated click": "observed_item_click_diff","Expected click probability": "expected_item_probability_diff","Known induced probability lift": "known_item_probability_lift_diff","Observed total simulated clicks": "observed_total_click_diff","Expected total clicks": "expected_total_click_diff","Known total probability lift": "known_total_probability_lift_diff", })validation_table["observed_minus_expected"] = np.where( validation_table["contrast"].eq("Total slate"), validation_table.get("observed_total_click_diff") - validation_table.get("expected_total_click_diff"), validation_table.get("observed_item_click_diff") - validation_table.get("expected_item_probability_diff"),)validation_table["expected_minus_known_lift"] = np.where( validation_table["contrast"].eq("Total slate"), validation_table.get("expected_total_click_diff") - validation_table.get("known_total_probability_lift_diff"), validation_table.get("expected_item_probability_diff") - validation_table.get("known_item_probability_lift_diff"),)validation_table["contrast_order"] = validation_table["contrast"].map(contrast_order)validation_table = validation_table.sort_values("contrast_order")display(validation_table)
outcome
contrast
expected_item_probability_diff
expected_total_click_diff
known_item_probability_lift_diff
known_total_probability_lift_diff
observed_item_click_diff
observed_total_click_diff
observed_minus_expected
expected_minus_known_lift
contrast_order
1
Direct focal item
0.1777
NaN
0.1794
NaN
0.1716
NaN
-0.0061
-0.0017
0
3
Same-cluster competitor spillover
-0.0695
NaN
-0.0686
NaN
-0.0577
NaN
0.0118
-0.0009
1
2
Displaced-item spillover
-0.0574
NaN
-0.0580
NaN
-0.0568
NaN
0.0006
0.0007
2
0
All non-focal slate spillover
-0.0450
NaN
-0.0452
NaN
-0.0436
NaN
0.0014
0.0003
3
4
Total slate
NaN
-0.3168
NaN
-0.3180
NaN
-0.3078
0.0090
0.0012
4
The validation table separates random outcome noise from the designed effect. The observed estimate can deviate from the expected estimate because clicks are simulated as Bernoulli outcomes. The expected estimate can differ from known induced lift when treated and control rows have small baseline differences despite randomization.
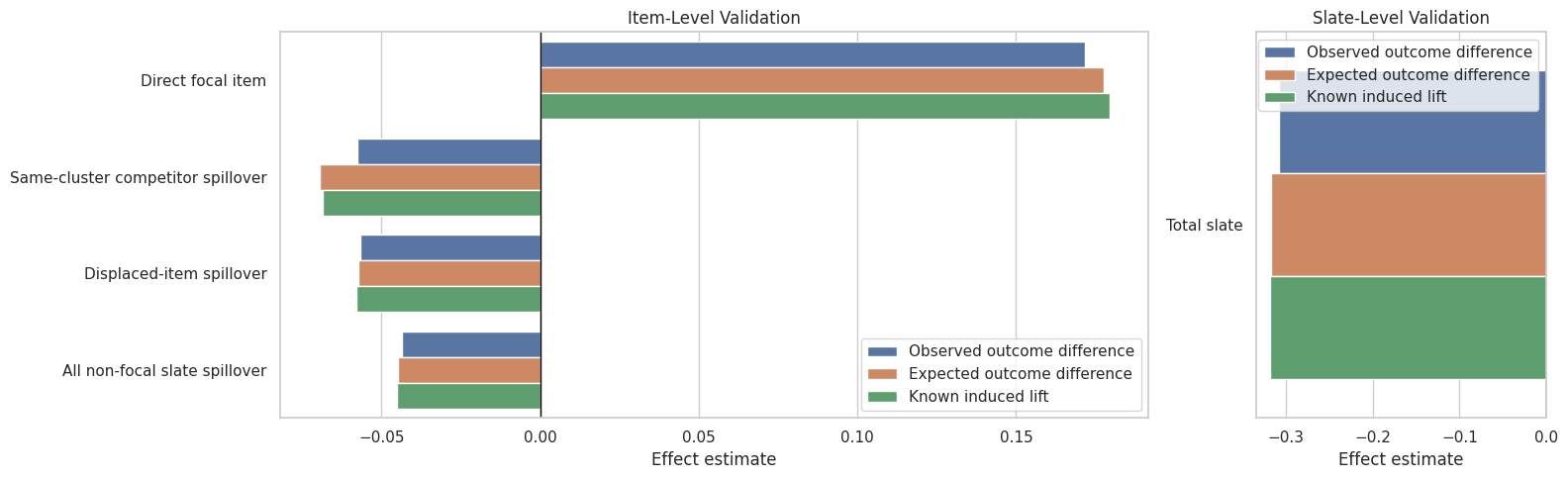
10. Plot Estimated Effects Versus Known Lift
This plot compares observed, expected, and known-lift estimates for each contrast. It is a useful simulation diagnostic: the observed estimates should be directionally consistent with the expected and known-lift signals, even if sampling noise creates some differences.
The validation view is the honest bridge between simulation and estimation. It tells us whether the estimator recovers the direction and approximate magnitude of the mechanism we built into the data. Later notebooks can use this as a baseline before moving into formal direct/indirect decomposition.
Naive versus Clustered Standard Errors
A common mistake in interference settings is to treat item rows as independent even though treatment is assigned to a whole slate. This cell compares naive and cluster-robust standard errors for the observed-outcome estimates.
If the cluster standard error is meaningfully different from the naive standard error, that warns against row-level uncertainty for this design. Even when the estimates are simple, the uncertainty calculation should match the randomized design.
Cluster Bootstrap for Main Observed Effects
The cluster-robust regression standard errors are analytic. This cell adds a cluster bootstrap, resampling slates with replacement and recomputing the treated-control mean difference. The bootstrap is slower but useful as a second uncertainty check.
The bootstrap intervals should usually tell the same qualitative story as the cluster-robust intervals. If they disagree sharply, that would be a sign to inspect skew, leverage, or sparse treated/control support within a contrast.
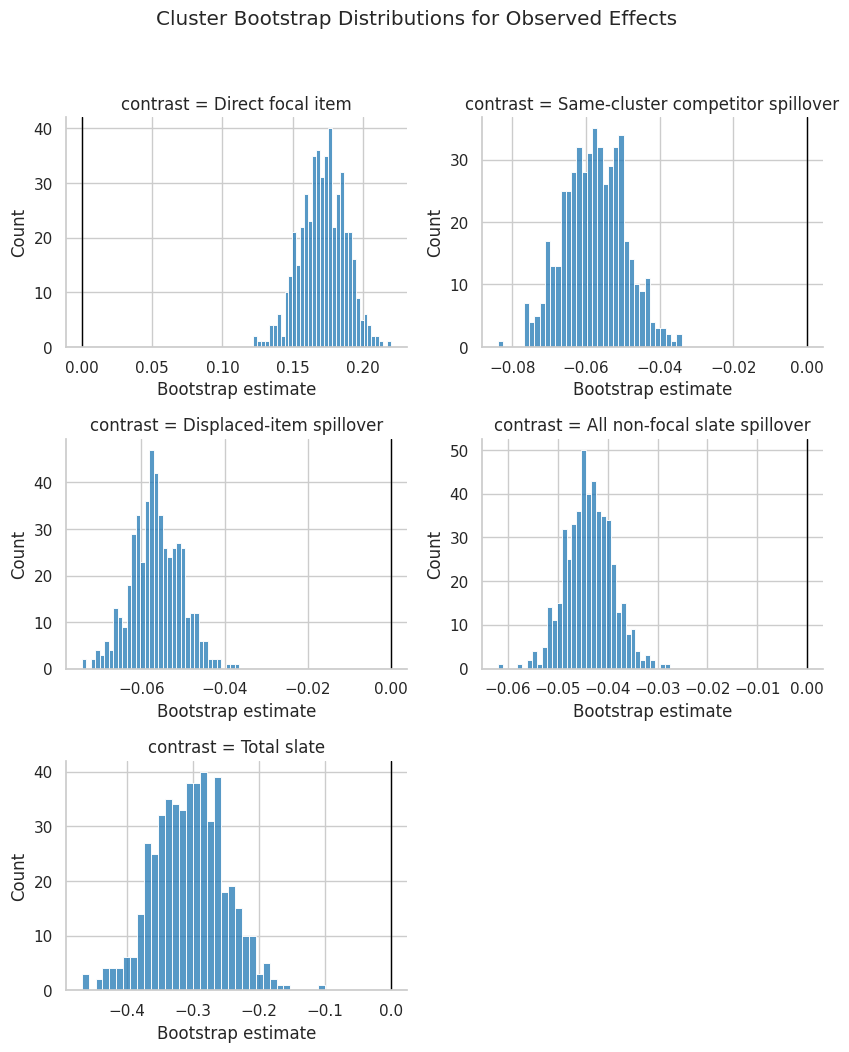
13. Plot Bootstrap Distributions
This plot shows the cluster bootstrap distribution for each observed effect. The vertical line marks zero, making it easy to see whether the bootstrap mass is mostly positive, mostly negative, or centered near no effect.
g = sns.FacetGrid( bootstrap_distribution, col="contrast", col_wrap=2, sharex=False, sharey=False, height=3.4, aspect=1.25,)g.map_dataframe(sns.histplot, x="estimate", bins=35, color="tab:blue")for ax in g.axes.flat: ax.axvline(0, color="black", linewidth=1) ax.set_xlabel("Bootstrap estimate")g.fig.suptitle("Cluster Bootstrap Distributions for Observed Effects", y=1.03)plt.tight_layout()plt.show()
The bootstrap plots add shape information that a table cannot show. For example, slate-level total effects can have a wider distribution because total clicks aggregate many item outcomes and because displacement varies by focal position and cluster composition.
Decompose the Total Slate Effect
The total slate effect combines focal gains and competitor losses. This cell uses the known expected lift components from the simulation to decompose promoted slates into direct focal lift, same-cluster spillover loss, other-spillover loss, and net total lift.
This diagnostic shows why the total effect can differ from the direct effect. It is a diagnostic showing why the total effect can differ from the direct effect.
The decomposition is the core product lesson of this interference project. Looking only at the promoted item can make an intervention look good, while the net slate effect can be weaker or negative once substitute and displaced-item losses are counted.
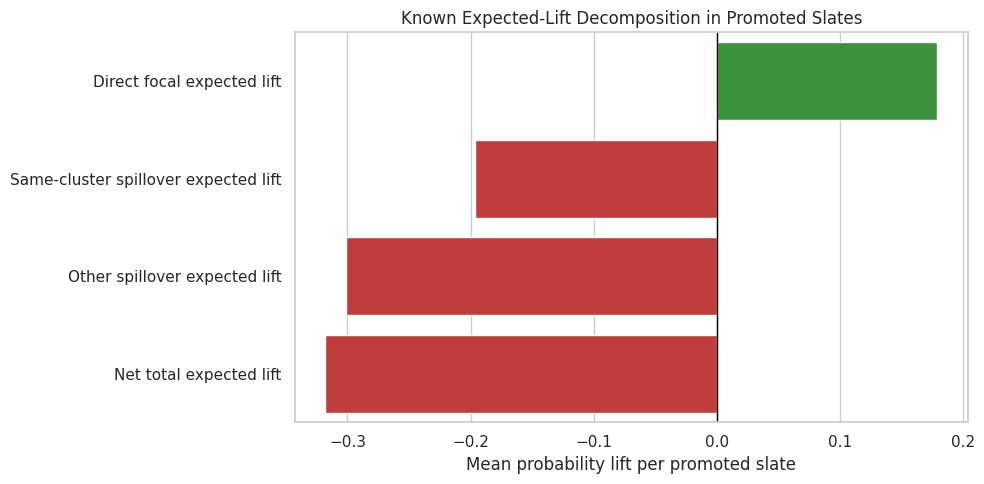
15. Plot the Total Effect Decomposition
This plot turns the decomposition into a report-friendly figure. Positive bars represent focal gains, while negative bars represent spillover losses. The net bar summarizes the slate-level consequence.
fig, ax = plt.subplots(figsize=(10, 5))colors = ["tab:green"if value >=0else"tab:red"for value in slate_decomposition["mean_lift_per_promoted_slate"]]sns.barplot( data=slate_decomposition, x="mean_lift_per_promoted_slate", y="component", hue="component", palette=dict(zip(slate_decomposition["component"], colors)), legend=False, ax=ax,)ax.axvline(0, color="black", linewidth=1)ax.set_title("Known Expected-Lift Decomposition in Promoted Slates")ax.set_xlabel("Mean probability lift per promoted slate")ax.set_ylabel("")plt.tight_layout()plt.show()
This figure explains why interference changes the evaluation question. The promoted item is only one part of the slate. A good recommender evaluation should ask whether the whole slate, cluster, or user session improved after accounting for displaced attention.
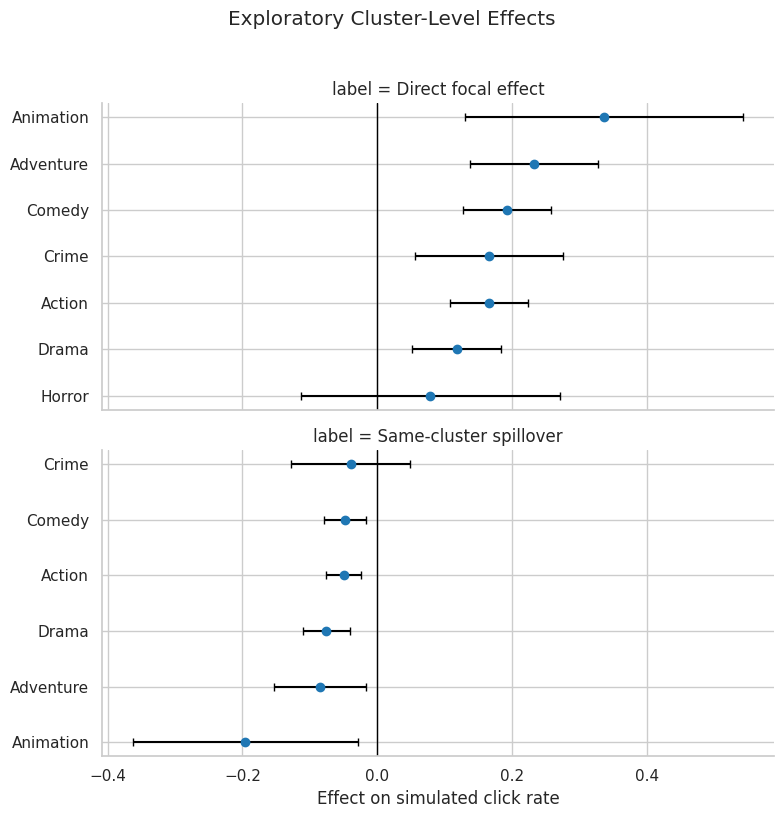
Cluster-Level Effect Heterogeneity
Spillovers may differ by genre cluster. This cell estimates observed direct focal effects and same-cluster spillover effects for clusters with enough support. These estimates are exploratory; the goal is to see where the simulated mechanism is strongest and where data are too sparse.
The cluster-level table is exploratory and helps identify where direct gains or spillover losses may be concentrated. It helps identify where direct gains or spillover losses may be concentrated. Sparse clusters are filtered out so the table stays focused on segments with enough treated and control support.
17. Plot Cluster-Level Direct and Spillover Effects
This plot shows the exploratory cluster effects with intervals. It is useful for seeing whether some content groups are more displacement-prone than others.
# Plot cluster-Level direct and spillover effects.ifnot cluster_effects.empty: plot_cluster_effects = cluster_effects.copy() plot_cluster_effects["label"] = plot_cluster_effects["effect_family"].map( {"direct": "Direct focal effect","same_cluster_spillover": "Same-cluster spillover", } ) g = sns.FacetGrid( plot_cluster_effects, row="label", sharex=True, sharey=False, height=4.0, aspect=2.0, )def point_ci(data, **kwargs):""" Summarize a vector of bootstrap estimates with a point and interval. Idea ---- This helper turns bootstrap draws into the estimate and confidence limits displayed in validation plots. Parameters ---------- data : object Input analysis table for the current project step. Returns ------- pandas.Series Point estimate and confidence interval bounds. """ ax = plt.gca() ordered = data.sort_values("estimate") y_positions = np.arange(len(ordered)) ax.errorbar( x=ordered["estimate"], y=y_positions, xerr=[ ordered["estimate"] - ordered["ci_95_lower"], ordered["ci_95_upper"] - ordered["estimate"], ], fmt="o", color="tab:blue", ecolor="black", capsize=3, ) ax.set_yticks(y_positions) ax.set_yticklabels(ordered["cluster"]) ax.axvline(0, color="black", linewidth=1) ax.set_xlabel("Effect on simulated click rate") ax.set_ylabel("") g.map_dataframe(point_ci) g.fig.suptitle("Exploratory Cluster-Level Effects", y=1.02) plt.tight_layout() plt.show()else:print("No clusters met the minimum support threshold.")
The cluster plot should be read as a guide for deeper analysis. Later notebooks can formalize these ideas by decomposing effects and checking sensitivity to the spillover exposure definition.
The saved files are the handoff to the next notebook. The most important tables are the observed effects, the validation table, and the slate decomposition. Together they show the estimated promoted-item gain, the estimated spillover loss, and the net slate consequence.
Takeaways and Next Step
This notebook estimated the randomized promotion simulation from several angles:
The direct focal-item effect measures the gain from moving a lower-ranked movie to the top of a slate.
Same-cluster and displaced-item contrasts measure competitor losses caused by the same promotion.
The total slate effect measures the net product outcome after combining focal gains and spillover losses.
Clustered uncertainty is the right default because promotion is assigned at the slate level.
The known simulation signal confirms why interference matters: a direct gain can coexist with a weaker or negative total slate effect.
The next notebook should formalize the decomposition into direct, indirect, and total effects, then compare alternative exposure definitions such as same-slate spillover, same-cluster spillover, and displaced-position spillover.