This notebook turns the MovieLens seed slates from the setup notebook into a causal simulation dataset for studying interference and spillovers.
The key idea is simple. Recommendation items in the same slate compete for limited attention. If one lower-ranked movie is promoted to the top of a slate, the promoted movie may gain visibility, but other movies can lose visibility or attention. The strongest spillover should usually fall on nearby substitute items, such as movies in the same genre cluster.
This notebook prepares exposure mappings before causal effect estimation. Instead, it defines the experimental structure that later estimators will use:
the item-row unit of analysis,
the slate-level randomized promotion assignment,
direct treatment exposure for promoted focal movies,
spillover exposure for non-promoted movies in the same slate,
stronger same-cluster spillover exposure for substitute movies,
simulated post-promotion outcomes based on relevance, visibility, and competition.
The result is an analysis-ready table with known assignment probabilities. That matters because the later notebooks can estimate direct, indirect, and total effects while clearly explaining what is randomized and what is simulated.
Dataset and Simulation Design Context
This project uses MovieLens 32M as a realistic user-item preference source. MovieLens contains ratings and movie metadata, but it lacks production recommendation impressions, randomized promotions, and observed slate outcomes.
Because the public data lack a real experiment, the project builds a transparent simulation. It constructs recommendation slates, selects lower-ranked focal movies, randomizes focal promotion at the slate level, and generates outcomes through an explicit competition model.
The simulated experiment is designed to teach interference. Promoting one item can increase that item’s engagement while reducing attention for substitutes and neighboring items. The estimands are direct focal effects, spillover effects, and total slate value, so the project emphasizes experiment design and measurement logic as a teaching workflow.
Role of this notebook. This notebook constructs the simulated promotion design, exposure mappings, and outcome mechanism used to study direct and spillover effects.
Mathematical Setup
An exposure mapping reduces a complex assignment vector () to a lower-dimensional exposure label:
\[
E_i = f_i(\mathbf{D}, G),
\]
where (G) is the item or slate relationship structure. In this project, (E_i) can include direct promotion, same-slate competition, or cluster-level spillover exposure. Once the exposure label is defined, the potential outcome is indexed by that label:
The mapping matters because all later estimators compare outcomes across exposure states. A poor mapping can hide interference, while an overly detailed mapping can create sparse cells that are hard to estimate.
1. Environment and Paths
This cell imports the libraries used in the notebook and finds the repository root by searching upward for the processed MovieLens files. This makes the notebook work whether it is run from the repository root, from JupyterLab, or through nbconvert.
# Set up environment and paths.from pathlib import Pathimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport seaborn as snsfrom IPython.display import displaysns.set_theme(style="whitegrid", context="notebook")pd.set_option("display.max_columns", 100)pd.set_option("display.max_rows", 80)pd.set_option("display.float_format", lambda value: f"{value:,.4f}")candidate_roots = [Path.cwd(), *Path.cwd().parents]PROJECT_DIR =next( root for root in candidate_rootsif (root /"data"/"processed"/"movielens_interference_slate_seed.parquet").exists())PROCESSED_DIR = PROJECT_DIR /"data"/"processed"NOTEBOOK_DIR = PROJECT_DIR /"notebooks"/"interference_spillover_effects"SLATE_SEED_PATH = PROCESSED_DIR /"movielens_interference_slate_seed.parquet"ITEMS_PATH = PROCESSED_DIR /"movielens_interference_items.parquet"USERS_PATH = PROCESSED_DIR /"movielens_interference_user_features.parquet"SLATE_SEED_PATH.exists(), ITEMS_PATH.exists(), USERS_PATH.exists()
(True, True, True)
All three checks should return True. These are the processed outputs from the setup notebook: seed slates, item features, and user features. This notebook uses those files as fixed inputs so the exposure mapping is reproducible.
2. Load the Seed Slates and Feature Tables
The seed slate table contains one row per user-slate-movie candidate. It already has a seed position, observed relevance from the user’s rating, and a genre-based spillover cluster. This cell loads the seed table and attaches user and item features that will be useful for balance checks and outcome simulation.
The loaded table should still have complete slates of equal size. Equal slate size keeps the simulation easy to explain: each promotion happens inside a 12-item candidate slate, and every slate has the same amount of attention to allocate.
Exposure Mapping Workflow
Define the Randomized Promotion Design
This cell defines the randomized intervention. In each slate, one focal movie is selected from the lower-ranked positions, then the slate is randomized to either promote that focal movie or leave the slate unchanged.
The design has two stages:
Focal selection: choose one eligible lower-position movie from each slate. This creates a candidate item that could be promoted.
Promotion assignment: flip a randomized promotion flag with probability 0.5. If assigned, the focal movie moves to position 1 and earlier items shift down by one position.
This design creates a clean comparison between promoted and non-promoted focal movies while also generating spillover exposure for the other items in promoted slates.
The observed promotion rate should be close to 50 percent. The focal items come from lower positions, which makes the intervention meaningful: moving a movie from position 5 or below into the top position creates a visible change and forces other items to shift.
Check Randomization Balance for Focal Items
Because promotion is randomized after focal selection, promoted and non-promoted focal items should look similar before treatment. This cell compares focal relevance, focal position, and user/item features across the two assignment arms. Large differences would suggest a coding problem.
The balance table is a pre-estimation diagnostic. Since assignment is random, small differences are expected by chance and systematic differences should be limited. Later effect estimates can therefore lean on the randomized design with light covariate adjustment.
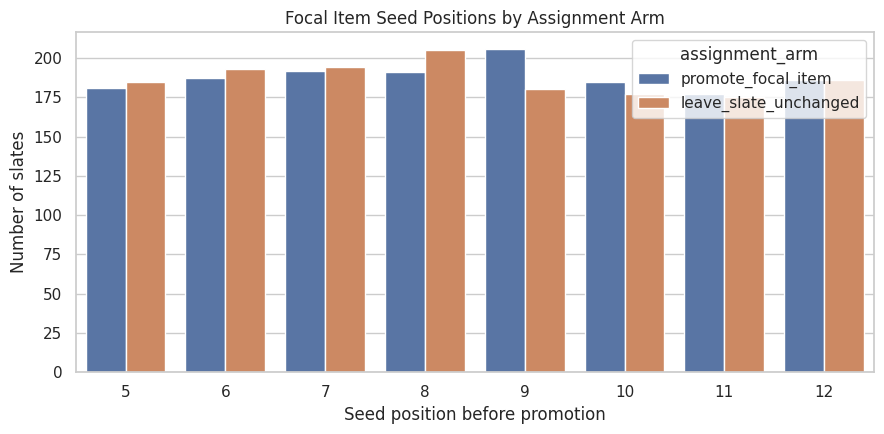
5. Visualize Focal Position Assignment
The focal item is always chosen from lower seed positions. This plot shows whether focal selection is spread across eligible positions or concentrated in one area of the slate. A spread is useful because promotion creates a range of position changes.
fig, ax = plt.subplots(figsize=(9, 4.5))sns.countplot(data=focal_items, x="focal_seed_position", hue="assignment_arm", ax=ax)ax.set_title("Focal Item Seed Positions by Assignment Arm")ax.set_xlabel("Seed position before promotion")ax.set_ylabel("Number of slates")plt.tight_layout()plt.show()
The assignment arms should have similar focal-position distributions. This matters because position gain is the mechanism of the direct effect. If one arm had much deeper focal items, promoted and control slates comparability would fail in a clean experiment design.
Map Direct and Spillover Exposures
This cell joins the slate-level assignment back to every item row and creates the core exposure variables.
Key variables:
direct_treatment: the row is the focal item and its slate was promoted.
same_slate_spillover: another item in the same slate was promoted.
same_cluster_spillover: a non-focal item shares the promoted focal item’s spillover cluster.
displaced_by_promotion: a non-focal item was above the focal item and shifted down after promotion.
final_position: the row’s post-assignment position.
visibility_gain: change in a simple visibility score after promotion.
The exposure groups make the interference structure explicit. The promoted focal item is the direct-treatment unit. Non-focal items in promoted slates are spillover-exposed, and same-cluster non-focal items are the most important substitute group. The final-position validity check confirms that each slate still has positions 1 through 12 after the simulated promotion.
7. Summarize Exposure Group Shares
This cell converts exposure counts into shares. The counts are useful, but shares make it easier to see how much data is available for each causal contrast. Same-cluster spillover rows are especially important because they represent plausible substitute displacement.
The direct-treatment group is small by design because each promoted slate has one promoted focal item. Spillover groups are larger because every other item in a promoted slate can be affected. This asymmetry is exactly why item-level analyses can be misleading if they only count the promoted item’s gain.
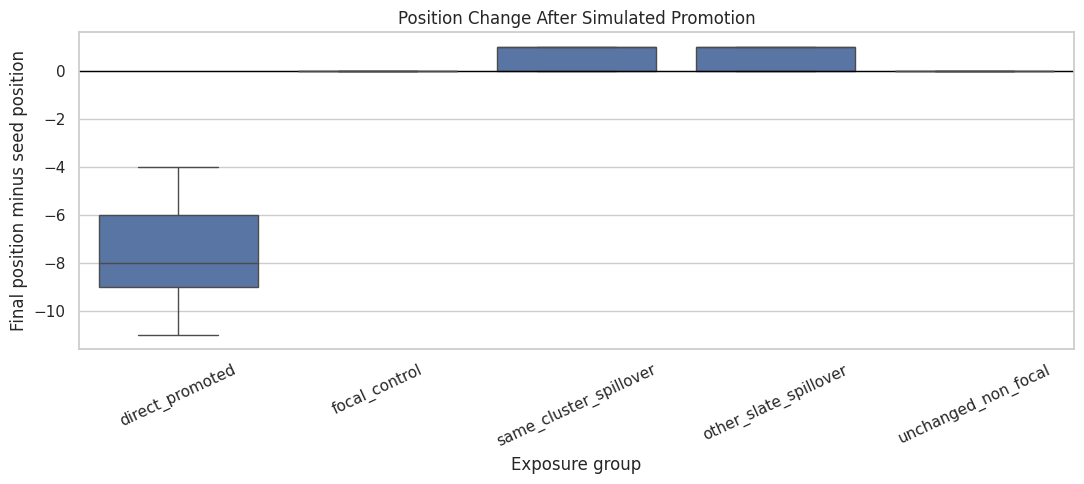
8. Plot Position Changes by Exposure Group
Promotion changes the focal item’s position dramatically and shifts some other items down. This plot shows the distribution of position changes. Negative values mean a movie moved upward; positive values mean it moved downward.
plot_order = ["direct_promoted","focal_control","same_cluster_spillover","other_slate_spillover","unchanged_non_focal",]fig, ax = plt.subplots(figsize=(11, 5))sns.boxplot( data=exposure, x="exposure_group", y="position_change", order=plot_order, ax=ax, showfliers=False,)ax.axhline(0, color="black", linewidth=1)ax.set_title("Position Change After Simulated Promotion")ax.set_xlabel("Exposure group")ax.set_ylabel("Final position minus seed position")ax.tick_params(axis="x", rotation=25)plt.tight_layout()plt.show()
The plot should show a strong upward move for directly promoted focal items and downward movement for displaced non-focal items. This is the mechanical source of interference. Promotion reallocates attention within the slate.
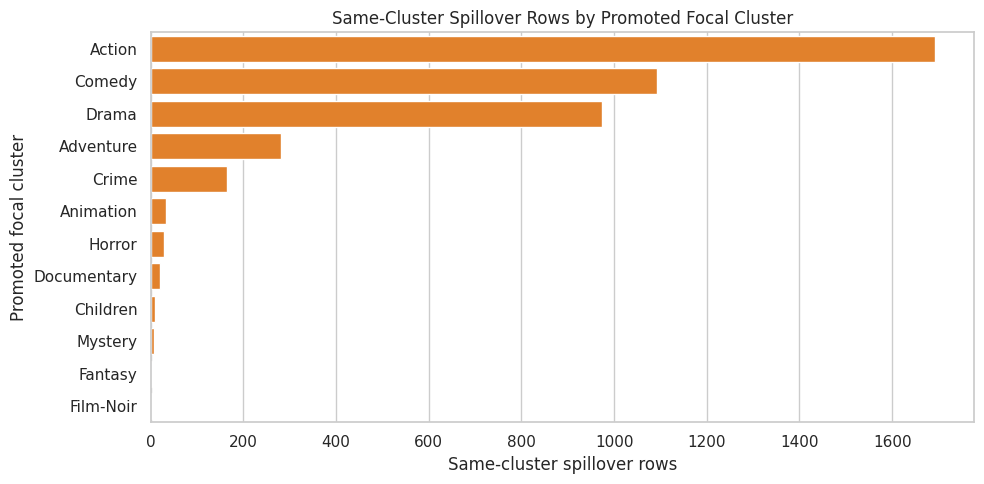
Same-Cluster Spillover by Genre Cluster
Same-cluster spillover varies across genres. This cell summarizes how often each spillover cluster appears as the promoted focal cluster and how many same-cluster competitors are exposed. This helps identify where later spillover estimates will have enough support.
Clusters with more same-cluster spillover rows will support more stable indirect-effect estimates. Sparse clusters can still be included in overall estimates, but later segment-level reporting should avoid over-interpreting very small groups.
10. Plot Same-Cluster Spillover Volume
This plot focuses on the largest promoted focal clusters. It shows where substitute displacement is most observable in the simulated data.
The largest clusters are the best candidates for detailed spillover analysis. This is also a product-relevant view: substitution is easier to reason about when the promoted item and competing items are in the same content family.
Simulate Observed Outcomes Under Competition
The seed ratings tell us user-item relevance, but they provide pre-simulation relevance signals. This cell creates simulated binary engagement outcomes using a transparent data-generating process.
The simulated click probability depends on:
user-item relevance from the observed rating,
baseline user rating tendency,
item popularity and liked rate,
final visibility after promotion,
a positive direct boost for promoted focal items,
a small generic attention penalty for non-focal items in promoted slates,
a stronger penalty for same-cluster substitutes.
The exact outcome model is synthetic, and the assumptions are explicit. That is the right setup for this interference notebook because MovieLens lacks real randomized exposure logs.
# Simulate observed outcomes under competition.def sigmoid(x):""" Apply the logistic sigmoid transformation. Idea ---- The simulation uses this helper to convert latent utility or score values into probabilities for generated recommendation outcomes. Parameters ---------- x : object Project-specific input named `x` used by this helper. Returns ------- numpy.ndarray Values transformed to the interval from zero to one. """return1/ (1+ np.exp(-x))outcome_rng = np.random.default_rng(RANDOM_SEED +17)exposure = exposure.copy()exposure["log_item_popularity"] = np.log1p(exposure["sample_rating_count"].fillna(0))log_pop_mean = exposure["log_item_popularity"].mean()log_pop_std = exposure["log_item_popularity"].std()exposure["log_item_popularity_z"] = ( exposure["log_item_popularity"] - log_pop_mean) / log_pop_stdbase_logit = (-2.75+0.78* (exposure["observed_relevance"] -3.5)+1.15* exposure["baseline_visibility"]+0.35* (exposure["liked_rate"] - exposure["liked_rate"].mean())+0.25* (exposure["sample_liked_rate"].fillna(exposure["sample_liked_rate"].mean()) - exposure["sample_liked_rate"].mean())+0.10* exposure["log_item_popularity_z"].fillna(0))observed_logit = (-2.75+0.78* (exposure["observed_relevance"] -3.5)+1.15* exposure["final_visibility"]+0.35* (exposure["liked_rate"] - exposure["liked_rate"].mean())+0.25* (exposure["sample_liked_rate"].fillna(exposure["sample_liked_rate"].mean()) - exposure["sample_liked_rate"].mean())+0.10* exposure["log_item_popularity_z"].fillna(0)+0.20* exposure["direct_treatment"]-0.08* exposure["same_slate_spillover"]-0.24* exposure["same_cluster_spillover"]-0.10* exposure["displaced_by_promotion"])exposure["p_no_promotion"] = sigmoid(base_logit).clip(0.01, 0.95)exposure["p_observed"] = sigmoid(observed_logit).clip(0.01, 0.95)exposure["known_probability_lift"] = exposure["p_observed"] - exposure["p_no_promotion"]exposure["simulated_click"] = outcome_rng.binomial(1, exposure["p_observed"]).astype("int8")exposure["simulated_engagement_score"] = ( exposure["simulated_click"] * (1+0.15* exposure["observed_relevance"])).astype("float32")outcome_summary = ( exposure.groupby("exposure_group") .agg( rows=("movieId", "size"), mean_probability=("p_observed", "mean"), mean_no_promotion_probability=("p_no_promotion", "mean"), mean_probability_lift=("known_probability_lift", "mean"), simulated_click_rate=("simulated_click", "mean"), mean_engagement_score=("simulated_engagement_score", "mean"), ) .reset_index() .sort_values("mean_probability_lift", ascending=False))display(outcome_summary)
exposure_group
rows
mean_probability
mean_no_promotion_probability
mean_probability_lift
simulated_click_rate
mean_engagement_score
0
direct_promoted
1505
0.3556
0.1762
0.1794
0.3435
0.5827
1
focal_control
1495
0.1779
0.1779
0.0000
0.1719
0.2935
4
unchanged_non_focal
16445
0.2151
0.2151
0.0000
0.2141
0.3673
2
other_slate_spillover
12246
0.1784
0.2154
-0.0370
0.1770
0.3033
3
same_cluster_spillover
4309
0.1466
0.2153
-0.0686
0.1522
0.2615
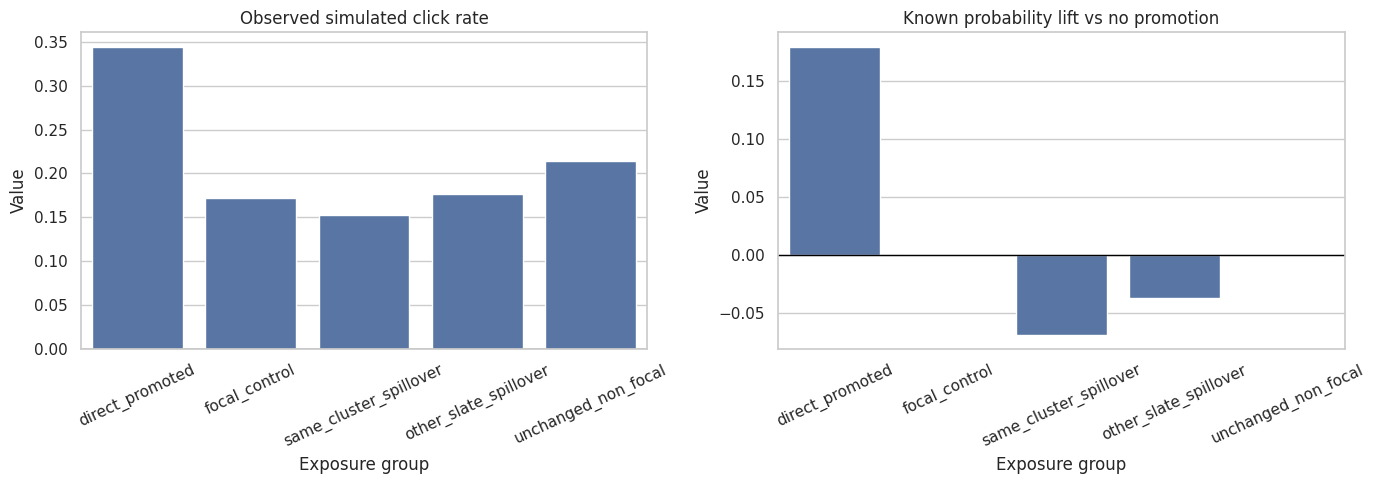
The simulated outcome table should show positive probability lift for directly promoted items and negative or near-negative lift for spillover groups. This is by design: the notebook is creating a controlled environment where later estimators should recover both promoted-item gains and competitor displacement.
12. Plot Simulated Outcomes by Exposure Group
This plot compares simulated click rates and known probability lift across exposure groups. It is a sanity check that the simulated data-generating process creates the expected pattern.
The left panel reflects both relevance selection and exposure, while the right panel isolates the known probability change induced by the simulation. This distinction is important: raw click-rate differences can differ from causal effects, even in a randomized simulation, because groups can differ in baseline relevance and position.
Build Slate-Level Outcomes
Interference is often best evaluated at the slate level because one item’s gain can be another item’s loss. This cell aggregates item-row outcomes into slate-level totals and separates focal, same-cluster competitor, and other competitor components.
The slate-level table is where displacement becomes visible. A promoted focal item can have a positive direct expected lift, while same-cluster and other competitors can have negative expected lifts. The total slate lift is the net product-relevant quantity.
14. Plot Slate-Level Net Lift
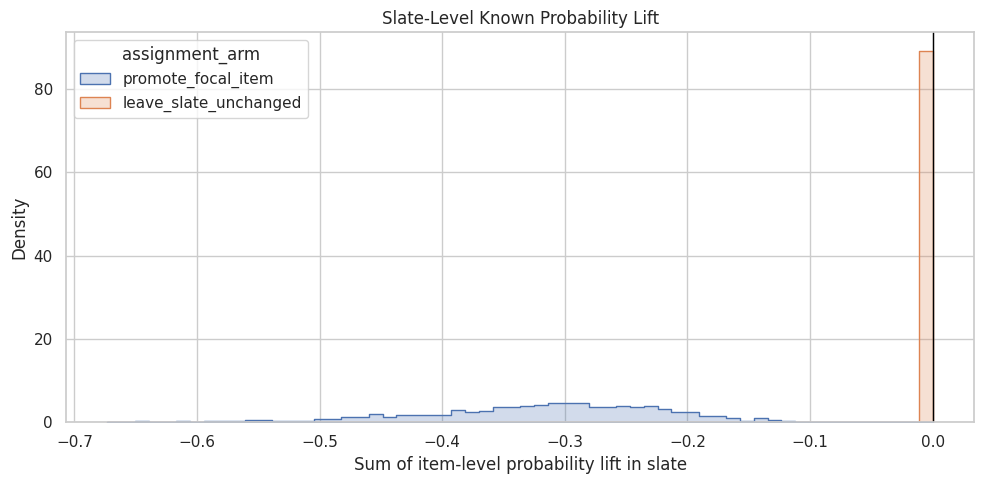
This plot shows the distribution of known expected total lift at the slate level. The promoted arm should have non-zero lift by construction, while the control arm should be zero because no slate positions changed.
fig, ax = plt.subplots(figsize=(10, 5))sns.histplot( data=slate_outcomes, x="total_known_probability_lift", hue="assignment_arm", bins=60, element="step", stat="density", common_norm=False, ax=ax,)ax.axvline(0, color="black", linewidth=1)ax.set_title("Slate-Level Known Probability Lift")ax.set_xlabel("Sum of item-level probability lift in slate")ax.set_ylabel("Density")plt.tight_layout()plt.show()
This distribution shows why total effects matter. A promotion can be beneficial for the focal item but still have a muted or negative net slate effect if competitor displacement is large. Later notebooks will estimate this net effect from observed simulated outcomes.
Compact Causal Design Summary
This cell summarizes the design choices and readiness checks in a compact table. The goal is to make the assumptions visible before any estimator is applied.
# Create a compact causal design summary.readiness_checks = pd.DataFrame( [ {"check": "complete_seed_slates_loaded","value": exposure["slate_id"].nunique(),"notes": "Each slate contains 12 item rows from the setup notebook.", }, {"check": "promotion_probability","value": PROMOTION_PROBABILITY,"notes": "Slate-level randomized assignment probability after focal selection.", }, {"check": "observed_promotion_rate","value": exposure.drop_duplicates("slate_id")["promotion_applied"].mean(),"notes": "Should be close to the design probability.", }, {"check": "direct_treatment_rows","value": int(exposure["direct_treatment"].sum()),"notes": "One directly treated focal item per promoted slate.", }, {"check": "same_slate_spillover_rows","value": int(exposure["same_slate_spillover"].sum()),"notes": "Non-focal items in promoted slates.", }, {"check": "same_cluster_spillover_rows","value": int(exposure["same_cluster_spillover"].sum()),"notes": "Non-focal items sharing the promoted focal item's cluster.", }, {"check": "invalid_final_position_slates","value": len(invalid_position_slates),"notes": "Should be zero; each slate should keep positions 1 through 12.", }, {"check": "mean_promoted_slate_known_lift","value": slate_outcomes.query("promotion_applied == 1")["total_known_probability_lift"].mean(),"notes": "Average known net expected lift in promoted slates under the simulation.", }, ])display(readiness_checks)
check
value
notes
0
complete_seed_slates_loaded
3,000.0000
Each slate contains 12 item rows from the setu...
1
promotion_probability
0.5000
Slate-level randomized assignment probability ...
2
observed_promotion_rate
0.5017
Should be close to the design probability.
3
direct_treatment_rows
1,505.0000
One directly treated focal item per promoted s...
4
same_slate_spillover_rows
16,555.0000
Non-focal items in promoted slates.
5
same_cluster_spillover_rows
4,309.0000
Non-focal items sharing the promoted focal ite...
6
invalid_final_position_slates
0.0000
Should be zero; each slate should keep positio...
7
mean_promoted_slate_known_lift
-0.3180
Average known net expected lift in promoted sl...
The readiness table is a contract for the next notebook. It says how many direct and spillover observations exist, verifies valid final positions, and records the known assignment probability. Estimation notebooks should use these diagnostics before reporting causal results.
The saved exposure mapping is the main output of this notebook. It contains treatment, spillover, position, visibility, simulated outcome, and assignment variables at the item-row level. That table is ready for direct-effect and spillover-effect estimators.
Takeaways and Next Step
This notebook converted MovieLens seed slates into a randomized interference simulation:
One eligible lower-ranked focal item was selected in each slate.
Slates were randomized to promote the focal item or leave the slate unchanged.
Direct treatment, same-slate spillover, same-cluster spillover, displacement, and final position were explicitly mapped.
Simulated outcomes were generated from relevance, visibility, and competition assumptions.
Item-level and slate-level outputs were saved for the next estimation notebook.
The next notebook should estimate direct, spillover, and total effects using the randomized assignment. A natural next step is 03_cluster_randomized_estimators.ipynb, which can compare simple difference-in-means estimators, cluster-robust standard errors, and slate-level total-effect estimates.