This capstone assembles the full AI-for-causal-inference workflow. We start with an industry decision, build an estimand card, screen variables, choose a design, run diagnostics, estimate effects, stress-test assumptions, generate a report, audit AI outputs, and compare model families.
The project is intentionally realistic: a company enabled an AI sales assistant for some sales reps and wants to know whether to expand it. Treatment was not randomized, adoption was targeted, and the data contain tempting post-treatment variables. This is exactly the kind of setting where AI assistance can help, but only if the workflow is structured and audited.
Learning Goals
By the end of this capstone, you should be able to:
Turn a business decision into a causal project contract.
Build a variable-timing screen and defensible adjustment set.
Compare naive, regression-adjusted, IPW, and AIPW estimates.
Diagnose overlap, balance, guardrails, and estimator stability.
Package evidence for AI-assisted report generation.
Audit AI-generated recommendations for hallucination and overclaiming.
Run role-style and all-model comparisons with memory cleanup.
Explain why end-to-end AI causal workflows remain brittle even when each component looks reasonable.
Live Model Note
Capstone notebooks are the most brittle notebooks in this course because many things can fail at once: model loading, structured parsing, variable-role reasoning, estimator diagnostics, report language, and all-model comparison. A model can be right about the business question and wrong about the adjustment set. It can produce a beautiful report that hides a bad control. It can pass one rerun and fail another.
That brittleness is part of the lesson. The workflow below treats AI as an assistant whose outputs must be structured, scored, redlined, and reviewed by a human causal owner. We also clear loaded model memory between model-family calls to reduce GPU fragility.
1. Setup
The capstone uses standard Python tools plus the shared local-LLM helpers from earlier notebooks. Live model calls are optional; the deterministic analysis is fully runnable without them.
import jsonimport reimport sysimport warningsfrom copy import deepcopyfrom pathlib import Pathfrom typing import Any, Literalimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport seaborn as snsimport statsmodels.formula.api as smffrom IPython.display import Markdown, displayfrom pydantic import BaseModel, Fieldwarnings.filterwarnings('ignore', category=FutureWarning)sns.set_theme(style='whitegrid', context='notebook')PROJECT_ROOT = Path.cwd()for candidate in [Path.cwd(), *Path.cwd().parents]:if (candidate /'notebooks'/'_shared'/'local_llm.py').exists(): PROJECT_ROOT = candidatebreakifstr(PROJECT_ROOT) notin sys.path: sys.path.insert(0, str(PROJECT_ROOT))print(f'Project root: {PROJECT_ROOT}')
Project root: /home/apex/Documents/portfolio
RUN_LIVE_LOCAL_LLM =TrueRUN_FULL_MODEL_COMPARISON =TrueRUN_SCHEMA_REPAIR_RETRY =TrueMODEL_ID ='Qwen/Qwen2.5-14B-Instruct'MAX_NEW_TOKENS =2400COMPACT_MAX_NEW_TOKENS =950TEMPERATURE =0.0SEED =224MODEL_COMPARISON_CASE_LIMIT =3try:import torchprint(f'CUDA available to this kernel: {torch.cuda.is_available()}')exceptExceptionas exc:print(f'Torch availability check failed: {exc}')
The company piloted an AI sales assistant that drafts follow-up messages, summarizes account history, and suggests next actions. Sales leadership wants to expand it to all reps if it increases qualified pipeline without harming customer experience.
The tricky part: enablement was targeted. Managers enabled the assistant first for reps with higher account readiness, stronger adoption likelihood, and available training capacity. That makes this an observational causal project, not a randomized experiment.
project_brief = {'project_id': 'ai_sales_assistant_capstone_v1','decision': 'Should the company expand the AI sales assistant to all eligible sales reps?','unit': 'rep_account_month','treatment': 'ai_assistant_enabled','primary_outcome': 'qualified_pipeline_created','secondary_outcome': 'pipeline_value_30d','guardrail_outcomes': ['customer_complaint_30d', 'discount_rate_30d'],'time_horizon': '30 days after account-month eligibility','assignment_process': 'Managers enabled the assistant first for reps with high readiness, high-volume accounts, and available onboarding capacity.','known_risks': ['Enablement was targeted rather than randomized.','AI activity metrics after enablement are post-treatment variables.','Revenue-facing outcomes can move with seasonality and account mix.','Expansion may increase discounting or customer complaints.', ],}print(json.dumps(project_brief, indent=2))
{
"project_id": "ai_sales_assistant_capstone_v1",
"decision": "Should the company expand the AI sales assistant to all eligible sales reps?",
"unit": "rep_account_month",
"treatment": "ai_assistant_enabled",
"primary_outcome": "qualified_pipeline_created",
"secondary_outcome": "pipeline_value_30d",
"guardrail_outcomes": [
"customer_complaint_30d",
"discount_rate_30d"
],
"time_horizon": "30 days after account-month eligibility",
"assignment_process": "Managers enabled the assistant first for reps with high readiness, high-volume accounts, and available onboarding capacity.",
"known_risks": [
"Enablement was targeted rather than randomized.",
"AI activity metrics after enablement are post-treatment variables.",
"Revenue-facing outcomes can move with seasonality and account mix.",
"Expansion may increase discounting or customer complaints."
]
}
3. Synthetic Capstone Data
The data-generating process contains pre-treatment confounding, a real positive effect, heterogeneous response, post-treatment usage, and guardrails. We keep the synthetic truth for teaching, but a real analysis would not have access to it.
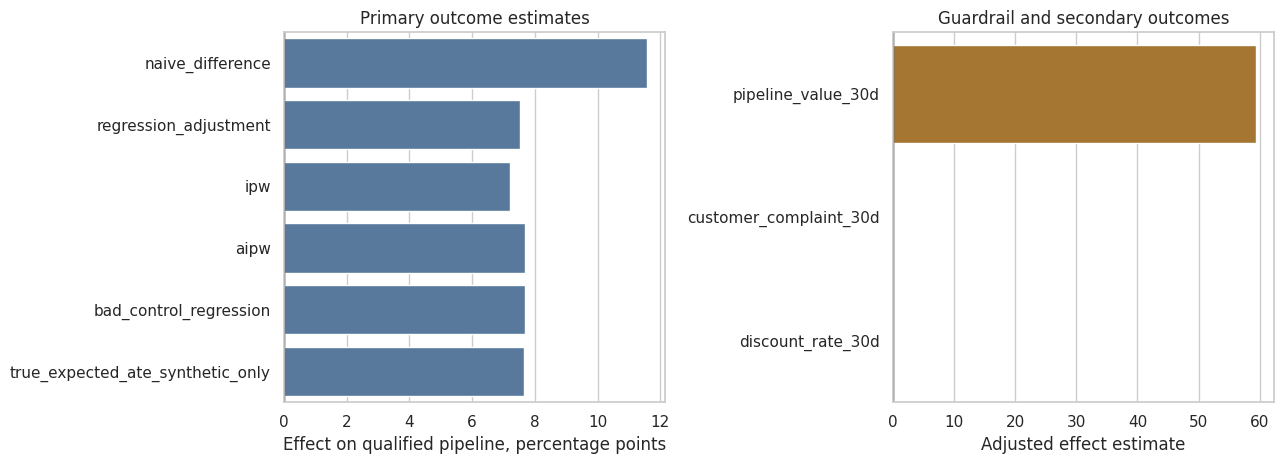
pd.DataFrame([ {'quantity': 'naive enabled-control difference', 'value': naive_effect}, {'quantity': 'true expected ATE visible only in synthetic data', 'value': true_ate},])
quantity
value
0
naive enabled-control difference
0.115851
1
true expected ATE visible only in synthetic data
0.076648
4. Project Contract and Estimand Card
The first capstone artifact is a project contract. It constrains later AI outputs: the model should not invent a new treatment, shift the outcome, or turn an observational design into an experiment.
estimand_card = {'project_id': project_brief['project_id'],'decision': project_brief['decision'],'unit': project_brief['unit'],'treatment': project_brief['treatment'],'outcome': project_brief['primary_outcome'],'time_horizon': project_brief['time_horizon'],'estimand': 'Average effect of enabling the AI sales assistant on qualified pipeline creation among eligible rep-account-months','comparison': 'The same eligible rep-account-months under no AI assistant enablement','design_class': 'observational_adjustment','key_assumption': 'Conditional exchangeability after observed pre-treatment adjustment','must_not_claim': ['Do not call this randomized evidence.','Do not control for AI messages generated after enablement.','Do not recommend full rollout without guardrail review.', ],}print(json.dumps(estimand_card, indent=2))
{
"project_id": "ai_sales_assistant_capstone_v1",
"decision": "Should the company expand the AI sales assistant to all eligible sales reps?",
"unit": "rep_account_month",
"treatment": "ai_assistant_enabled",
"outcome": "qualified_pipeline_created",
"time_horizon": "30 days after account-month eligibility",
"estimand": "Average effect of enabling the AI sales assistant on qualified pipeline creation among eligible rep-account-months",
"comparison": "The same eligible rep-account-months under no AI assistant enablement",
"design_class": "observational_adjustment",
"key_assumption": "Conditional exchangeability after observed pre-treatment adjustment",
"must_not_claim": [
"Do not call this randomized evidence.",
"Do not control for AI messages generated after enablement.",
"Do not recommend full rollout without guardrail review."
]
}
5. Variable Timing Screen
The post-treatment AI activity variable is tempting because it predicts outcomes. It is also a bad control for estimating the total effect of enablement.
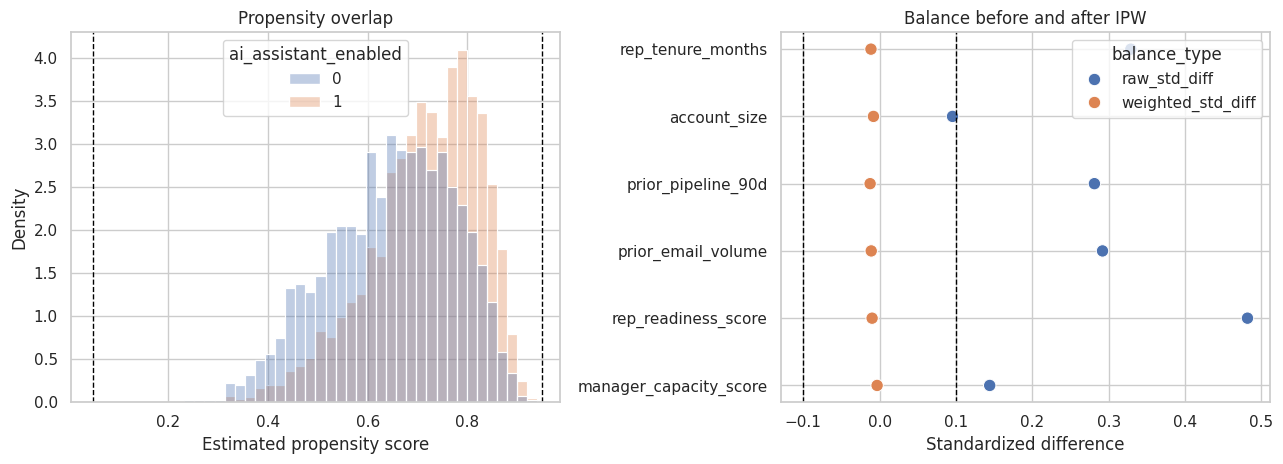
The capstone uses a propensity model to diagnose overlap and construct IPW/AIPW estimates. In production, this step should be reviewed carefully; propensity models are not magic confounding removers.
Sensitivity analysis here is deliberately simple: we ask how large an unobserved bias would need to be, relative to the preferred estimate, to erase the conclusion. In production, this should be replaced or supplemented with domain-specific sensitivity analysis.
The evidence package is what AI systems are allowed to summarize. They should not invent diagnostics, sources, or stronger claims.
def clean_value(value):ifisinstance(value, (np.integer,)):returnint(value)ifisinstance(value, (np.floating, float)):if np.isnan(value):returnNonereturnfloat(value)ifisinstance(value, dict):return {key: clean_value(val) for key, val in value.items() if clean_value(val) isnotNone}ifisinstance(value, list):return [clean_value(item) for item in value]return valuedef records(dataframe):return clean_value(dataframe.to_dict(orient='records'))evidence_package = clean_value({'project_brief': project_brief,'estimand_card': estimand_card,'variable_dictionary': records(variable_dictionary),'overlap': overlap,'balance_table': records(balance_table.round(4)),'estimate_table': records(estimate_table.round(5)),'guardrail_table': records(guardrail_table[['outcome', 'estimate', 'ci_low', 'ci_high', 'p_value']].round(5)),'sensitivity_summary': sensitivity_summary,'gate_table': records(gate_table),'approved_claim_boundary': 'Observed adjusted evidence suggests a positive effect on qualified pipeline, but assignment was targeted and rollout should require human review plus guardrail monitoring.','brittleness_note': 'This capstone combines deterministic analysis and LLM outputs; model outputs can vary across reruns and must be audited.',})print(json.dumps(evidence_package, indent=2)[:5200])
{
"project_brief": {
"project_id": "ai_sales_assistant_capstone_v1",
"decision": "Should the company expand the AI sales assistant to all eligible sales reps?",
"unit": "rep_account_month",
"treatment": "ai_assistant_enabled",
"primary_outcome": "qualified_pipeline_created",
"secondary_outcome": "pipeline_value_30d",
"guardrail_outcomes": [
"customer_complaint_30d",
"discount_rate_30d"
],
"time_horizon": "30 days after account-month eligibility",
"assignment_process": "Managers enabled the assistant first for reps with high readiness, high-volume accounts, and available onboarding capacity.",
"known_risks": [
"Enablement was targeted rather than randomized.",
"AI activity metrics after enablement are post-treatment variables.",
"Revenue-facing outcomes can move with seasonality and account mix.",
"Expansion may increase discounting or customer complaints."
]
},
"estimand_card": {
"project_id": "ai_sales_assistant_capstone_v1",
"decision": "Should the company expand the AI sales assistant to all eligible sales reps?",
"unit": "rep_account_month",
"treatment": "ai_assistant_enabled",
"outcome": "qualified_pipeline_created",
"time_horizon": "30 days after account-month eligibility",
"estimand": "Average effect of enabling the AI sales assistant on qualified pipeline creation among eligible rep-account-months",
"comparison": "The same eligible rep-account-months under no AI assistant enablement",
"design_class": "observational_adjustment",
"key_assumption": "Conditional exchangeability after observed pre-treatment adjustment",
"must_not_claim": [
"Do not call this randomized evidence.",
"Do not control for AI messages generated after enablement.",
"Do not recommend full rollout without guardrail review."
]
},
"variable_dictionary": [
{
"variable": "region",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "segment",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "month",
"timing": "pre",
"role": "seasonality_control",
"allowed_in_adjustment": true
},
{
"variable": "rep_tenure_months",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "account_size",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "prior_pipeline_90d",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "prior_email_volume",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "rep_readiness_score",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "manager_capacity_score",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "ai_assistant_enabled",
"timing": "treatment",
"role": "treatment",
"allowed_in_adjustment": false
},
{
"variable": "ai_messages_generated_after_enablement",
"timing": "post",
"role": "mediator_or_usage",
"allowed_in_adjustment": false
},
{
"variable": "qualified_pipeline_created",
"timing": "post",
"role": "primary_outcome",
"allowed_in_adjustment": false
},
{
"variable": "pipeline_value_30d",
"timing": "post",
"role": "secondary_outcome",
"allowed_in_adjustment": false
},
{
"variable": "customer_complaint_30d",
"timing": "post",
"role": "guardrail_outcome",
"allowed_in_adjustment": false
},
{
"variable": "discount_rate_30d",
"timing": "post",
"role": "guardrail_outcome",
"allowed_in_adjustment": false
}
],
"overlap": {
"min_propensity": 0.23244933930005748,
"max_propensity": 0.9401834725453633,
"share_between_05_95": 1.0,
"effective_sample_size_ipw": 5362.045681722396,
"status": "pass"
},
"balance_table": [
{
"variable": "rep_tenure_months",
"raw_std_diff": 0.329,
"weighted_std_diff": -0.0114,
"raw_status": "review",
"weighted_status": "pass"
},
{
"variable": "account_size",
"raw_std_diff": 0.0954,
"weighted_std_diff": -0.0081,
"raw_status": "pass",
"weighted_status": "pass"
},
{
"variable": "prior_pipeline_90d",
"raw_std_diff": 0.2813,
"weighted_std_diff": -0.0125,
"raw_status": "review",
"weighted_status": "pass"
},
{
"variable": "prior_email_volume",
"raw_std_diff": 0.2919,
"weighted_std_diff": -0.011,
"raw_status": "review",
"weighted_status": "pass"
},
{
"variable": "rep_readiness_score",
"raw_std_diff": 0.4818,
"weighted_std_diff": -0.0099,
"raw_status": "review",
"weighted_status": "pass"
def build_deterministic_capstone_report(package): preferred =next(row for row in package['estimate_table'] if row['method'] =='aipw') reg =next(row for row in package['estimate_table'] if row['method'] =='regression_adjustment') gates = pd.DataFrame(package['gate_table']) gate_lines ='\n'.join(f"- {row.gate}: {row.status} ({row.reason})"for row in gates.itertuples()) complaint =next(row for row in package['guardrail_table'] if row['outcome'] =='customer_complaint_30d') discount =next(row for row in package['guardrail_table'] if row['outcome'] =='discount_rate_30d')returnf"""### Capstone Causal Report: AI Sales Assistant**Decision.** {package['project_brief']['decision']}**Design.** Observational adjustment. Enablement was targeted by readiness and capacity, so this is not randomized evidence.**Estimand.** {package['estimand_card']['estimand']}**Primary estimate.** The preferred AIPW estimate is {100* preferred['estimate']:.1f} percentage points on qualified pipeline creation. Regression adjustment gives {100* reg['estimate']:.1f} percentage points with 95% CI {100* reg['ci_low']:.1f} to {100* reg['ci_high']:.1f} percentage points.**Diagnostics.**{gate_lines}**Guardrails.** Customer complaints changed by {100* complaint['estimate']:.2f} percentage points. Discount rate changed by {100* discount['estimate']:.2f} percentage points. Both should be monitored in any phased rollout.**Recommendation.** Proceed only with human review and a monitored phased rollout. Do not claim the AI assistant was randomized, and do not control for post-enablement AI message volume when estimating the total effect.**Brittleness note.** AI-generated summaries of this evidence can change across reruns and model families; use the structured gates and redline checks before sharing with stakeholders.""".strip()capstone_report = build_deterministic_capstone_report(evidence_package)display(Markdown(capstone_report))
Capstone Causal Report: AI Sales Assistant
Decision. Should the company expand the AI sales assistant to all eligible sales reps?
Design. Observational adjustment. Enablement was targeted by readiness and capacity, so this is not randomized evidence.
Estimand. Average effect of enabling the AI sales assistant on qualified pipeline creation among eligible rep-account-months
Primary estimate. The preferred AIPW estimate is 7.7 percentage points on qualified pipeline creation. Regression adjustment gives 7.5 percentage points with 95% CI 5.1 to 9.9 percentage points.
Guardrails. Customer complaints changed by 3.84 percentage points. Discount rate changed by 1.08 percentage points. Both should be monitored in any phased rollout.
Recommendation. Proceed only with human review and a monitored phased rollout. Do not claim the AI assistant was randomized, and do not control for post-enablement AI message volume when estimating the total effect.
Brittleness note. AI-generated summaries of this evidence can change across reruns and model families; use the structured gates and redline checks before sharing with stakeholders.
10. AI Output Schema and Prompt
The capstone LLM task is not to redo the analysis. It is to review and summarize the evidence package with explicit constraints.
CAPSTONE_SYSTEM_MESSAGE ="""You are a careful causal inference reviewer for an AI-assisted causal project.Use only the evidence package. Do not invent diagnostics, columns, or sources. Return final JSON only.""".strip()def capstone_schema_prompt():return"""Return one CapstoneCausalReview JSON object only.Schema:{ "title": "string", "design_assessment": "string", "estimand_assessment": "string", "diagnostic_summary": ["string", "string", "string"], "primary_result_summary": "string", "guardrail_summary": ["string", "string"], "risks_and_limitations": ["string", "string", "string"], "forbidden_claims": ["string", "string"], "recommendation": "roll_out | phase_rollout_with_monitoring | needs_more_analysis | do_not_roll_out", "recommendation_rationale": ["string", "string"], "human_review_gates": ["string"], "brittleness_note": "string", "confidence": "low | medium | high"}""".strip()def build_capstone_prompt(package):returnf"""{capstone_schema_prompt()}Evidence package:{json.dumps(package, indent=2)}Requirements:- State that this is observational adjustment, not randomized evidence.- Mention the post-treatment AI message variable as a forbidden adjustment variable.- Mention overlap, balance, estimator stability, guardrails, and sensitivity.- Recommend only what the evidence supports.- Mention brittleness and the need to audit model-generated summaries.""".strip()capstone_prompt = build_capstone_prompt(evidence_package)print(capstone_prompt[:3000])
Return one CapstoneCausalReview JSON object only.
Schema:
{
"title": "string",
"design_assessment": "string",
"estimand_assessment": "string",
"diagnostic_summary": ["string", "string", "string"],
"primary_result_summary": "string",
"guardrail_summary": ["string", "string"],
"risks_and_limitations": ["string", "string", "string"],
"forbidden_claims": ["string", "string"],
"recommendation": "roll_out | phase_rollout_with_monitoring | needs_more_analysis | do_not_roll_out",
"recommendation_rationale": ["string", "string"],
"human_review_gates": ["string"],
"brittleness_note": "string",
"confidence": "low | medium | high"
}
Evidence package:
{
"project_brief": {
"project_id": "ai_sales_assistant_capstone_v1",
"decision": "Should the company expand the AI sales assistant to all eligible sales reps?",
"unit": "rep_account_month",
"treatment": "ai_assistant_enabled",
"primary_outcome": "qualified_pipeline_created",
"secondary_outcome": "pipeline_value_30d",
"guardrail_outcomes": [
"customer_complaint_30d",
"discount_rate_30d"
],
"time_horizon": "30 days after account-month eligibility",
"assignment_process": "Managers enabled the assistant first for reps with high readiness, high-volume accounts, and available onboarding capacity.",
"known_risks": [
"Enablement was targeted rather than randomized.",
"AI activity metrics after enablement are post-treatment variables.",
"Revenue-facing outcomes can move with seasonality and account mix.",
"Expansion may increase discounting or customer complaints."
]
},
"estimand_card": {
"project_id": "ai_sales_assistant_capstone_v1",
"decision": "Should the company expand the AI sales assistant to all eligible sales reps?",
"unit": "rep_account_month",
"treatment": "ai_assistant_enabled",
"outcome": "qualified_pipeline_created",
"time_horizon": "30 days after account-month eligibility",
"estimand": "Average effect of enabling the AI sales assistant on qualified pipeline creation among eligible rep-account-months",
"comparison": "The same eligible rep-account-months under no AI assistant enablement",
"design_class": "observational_adjustment",
"key_assumption": "Conditional exchangeability after observed pre-treatment adjustment",
"must_not_claim": [
"Do not call this randomized evidence.",
"Do not control for AI messages generated after enablement.",
"Do not recommend full rollout without guardrail review."
]
},
"variable_dictionary": [
{
"variable": "region",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "segment",
"timing": "pre",
"role": "confounder",
"allowed_in_adjustment": true
},
{
"variable": "month",
"timing": "pre",
"role": "seasonality_control",
"allowed_in_adjustment": true
},
{
{
"title": "Capstone Review for AI Sales Assistant Expansion",
"design_assessment": "The design is observational adjustment, not randomized evidence. The assignment process was targeted based on manager decisions, which introduces potential biases.",
"estimand_assessment": "The estimand is the average effect of enabling the AI sales assistant on qualified pipeline creation among eligible rep-account-months, compared to the same units without the assistant. This requires conditional exchangeability after observed pre-treatment adjustment.",
"diagnostic_summary": [
"Overlap is adequate with all units having sufficient propensity scores within the range [0.05, 0.95].",
"Weighted balance is acceptable, with all covariates achieving satisfactory balance after weighting.",
"Estimator stability is confirmed with consistent signs across plausible methods and a small spread of estimates."
],
"primary_result_summary": "The preferred estimate using augmented inverse probability weighting (AIPW) indicates a positive effect of 7.7% (pp) on qualified pipeline creation, with a confidence interval from 5.1% to 10.0%. This suggests that enabling the AI assistant leads to higher qualified pipelines.",
"guardrail_summary": [
"Pipeline value increased by 59.4%, indicating potential revenue growth.",
"Customer complaints and discount rates also increased, suggesting possible negative impacts on customer satisfaction and pricing."
],
"risks_and_limitations": [
"The assignment process was targeted, leading to potential confounding factors not fully accounted for.",
"Post-treatment variables like AI messages generated after enablement were not used in the preferred adjustment set.",
"Seasonality and account mix can influence revenue-facing outcomes."
],
"forbidden_claims": [
"Do not claim this is randomized evidence.",
"Do not adjust for post-treatment variables such as AI messages generated after enablement."
],
"recommendation": "phase_rollout_with_monitoring",
"recommendation_rationale": [
"The evidence supports a positive impact on qualified pipeline creation.",
"However, guardrails indicate potential risks that require monitoring during rollout."
],
"human_review_gates": [
"Guardrails must be reviewed and monitored during any expansion."
],
"brittleness_note": "This capstone combines deterministic analysis and LLM outputs; model outputs can vary across reruns and must be audited.",
"confidence": "medium"
}
if parsed_capstone_review isnotNone: display(Markdown(f"### {parsed_capstone_review.title}")) display(Markdown(parsed_capstone_review.design_assessment)) display(Markdown('**Diagnostics**\n'+'\n'.join(f'- {item}'for item in parsed_capstone_review.diagnostic_summary))) display(Markdown(f'**Recommendation:** `{parsed_capstone_review.recommendation}` \n**Confidence:** `{parsed_capstone_review.confidence}`'))else:print('No parsed capstone review is available yet.')
Capstone Review for AI Sales Assistant Expansion
The design is observational adjustment, not randomized evidence. The assignment process was targeted based on manager decisions, which introduces potential biases.
Diagnostics - Overlap is adequate with all units having sufficient propensity scores within the range [0.05, 0.95]. - Weighted balance is acceptable, with all covariates achieving satisfactory balance after weighting. - Estimator stability is confirmed with consistent signs across plausible methods and a small spread of estimates.
The audit checks for the highest-risk capstone failures: randomized overclaiming, bad-control omission, missing guardrails, and missing brittleness.
def contains_any(text, patterns): text_lower = text.lower()returnany(pattern.lower() in text_lower for pattern in patterns)def score_capstone_review(review):if review isNone:return pd.DataFrame([{'criterion': 'parsed review exists', 'passed': False, 'score': 0}]) text =' '.join([ review.title, review.design_assessment, review.estimand_assessment,' '.join(review.diagnostic_summary), review.primary_result_summary,' '.join(review.guardrail_summary),' '.join(review.risks_and_limitations),' '.join(review.forbidden_claims), review.recommendation,' '.join(review.recommendation_rationale),' '.join(review.human_review_gates), review.brittleness_note, review.confidence, ]).lower() checks = {'states observational not randomized': contains_any(text, ['observational', 'not randomized', 'targeted']) andnot contains_any(text, ['randomized evidence', 'randomized experiment']),'mentions forbidden post-treatment AI message variable': contains_any(text, ['ai_messages_generated_after_enablement', 'post-treatment', 'post enablement', 'bad control']),'mentions overlap and balance': contains_any(text, ['overlap']) and contains_any(text, ['balance']),'mentions estimator stability or sensitivity': contains_any(text, ['stability', 'sensitivity', 'aipw', 'ipw']),'mentions guardrails': contains_any(text, ['complaint', 'discount', 'guardrail']),'recommendation is not unconditional rollout': review.recommendation in {'phase_rollout_with_monitoring', 'needs_more_analysis', 'do_not_roll_out'},'mentions human review gates': len(review.human_review_gates) >=1or contains_any(text, ['human review']),'mentions brittleness or audit': contains_any(text, ['brittle', 'rerun', 'audit', 'model output', 'unstable']),'does not use proof language': not contains_any(text, ['proves', 'guarantees', 'definitively']),'forbidden claims included': len(review.forbidden_claims) >=2, }return pd.DataFrame([ {'criterion': key, 'passed': bool(value), 'score': int(bool(value))}for key, value in checks.items() ])capstone_review_score = score_capstone_review(parsed_capstone_review)capstone_review_score
criterion
passed
score
0
states observational not randomized
False
0
1
mentions forbidden post-treatment AI message v...
True
1
2
mentions overlap and balance
True
1
3
mentions estimator stability or sensitivity
True
1
4
mentions guardrails
True
1
5
recommendation is not unconditional rollout
True
1
6
mentions human review gates
True
1
7
mentions brittleness or audit
True
1
8
does not use proof language
True
1
9
forbidden claims included
True
1
12. Redline Rules for the Final Report
Even if the structured review parses, the final report should be redlined before stakeholder use.
REDLINE_PATTERNS = {'randomization overclaim': r'\b(randomized experiment|randomized evidence|random assignment)\b','proof language': r'\b(proves?|guarantees?|definitively)\b','bad-control reassurance': r'\bcontrol\w*\b.{0,80}\b(ai_messages_generated_after_enablement|messages generated|post-enablement)\b','unconditional rollout': r'\b(roll out to all|full rollout|expand to all)\b',}def redline_text(text): rows = []for issue, pattern in REDLINE_PATTERNS.items():for match in re.finditer(pattern, text, flags=re.IGNORECASE): start, end = match.span() snippet = text[max(0, start -80): min(len(text), end +80)].replace('\n', ' ') rows.append({'issue': issue, 'match': match.group(0), 'snippet': snippet})return pd.DataFrame(rows)redline_text(capstone_report)
issue
match
snippet
0
randomization overclaim
randomized evidence
l adjustment. Enablement was targeted by readi...
1
bad-control reassurance
controls in preferred adjustment set: pass (po...
nt process: pass (Enablement was targeted, not...
2
bad-control reassurance
control for post-enablement
itored phased rollout. Do not claim the AI ass...
13. Optional All-Model Capstone Comparison
The comparison uses compact cases based on the capstone. Each model must produce a decision and identify the blockers. We clear model memory between model families.
CAPSTONE_EVAL_CASES = [ {'case_name': 'targeted_ai_sales_assistant','brief': 'Managers targeted AI sales assistant enablement to high-readiness reps. There is a post-treatment variable ai_messages_generated_after_enablement.','expected_design': 'observational_adjustment','expected_decision': 'phase_rollout_with_monitoring','must_exclude': ['ai_messages_generated_after_enablement'],'must_monitor': ['customer_complaint_30d', 'discount_rate_30d'], }, {'case_name': 'randomized_ai_holdout','brief': 'Eligible reps were randomly assigned to AI assistant enablement with a 20% holdout. Guardrails include complaint rate and discounting.','expected_design': 'randomized_experiment','expected_decision': 'phase_rollout_with_monitoring','must_exclude': [],'must_monitor': ['complaint rate', 'discounting'], }, {'case_name': 'post_treatment_only_metrics','brief': 'The only available predictors are AI messages generated after enablement and pipeline outcome. The team asks for a causal rollout recommendation.','expected_design': 'do_not_analyze_yet','expected_decision': 'do_not_roll_out','must_exclude': ['AI messages generated after enablement'],'must_monitor': [], },]CAPSTONE_EVAL_CASES
[{'case_name': 'targeted_ai_sales_assistant',
'brief': 'Managers targeted AI sales assistant enablement to high-readiness reps. There is a post-treatment variable ai_messages_generated_after_enablement.',
'expected_design': 'observational_adjustment',
'expected_decision': 'phase_rollout_with_monitoring',
'must_exclude': ['ai_messages_generated_after_enablement'],
'must_monitor': ['customer_complaint_30d', 'discount_rate_30d']},
{'case_name': 'randomized_ai_holdout',
'brief': 'Eligible reps were randomly assigned to AI assistant enablement with a 20% holdout. Guardrails include complaint rate and discounting.',
'expected_design': 'randomized_experiment',
'expected_decision': 'phase_rollout_with_monitoring',
'must_exclude': [],
'must_monitor': ['complaint rate', 'discounting']},
{'case_name': 'post_treatment_only_metrics',
'brief': 'The only available predictors are AI messages generated after enablement and pipeline outcome. The team asks for a causal rollout recommendation.',
'expected_design': 'do_not_analyze_yet',
'expected_decision': 'do_not_roll_out',
'must_exclude': ['AI messages generated after enablement'],
'must_monitor': []}]
def compact_capstone_prompt(case):returnf"""Return one CompactCapstoneDecision JSON object only.Schema:{{ "decision": "roll_out | phase_rollout_with_monitoring | needs_more_analysis | do_not_roll_out", "design_label": "randomized_experiment | observational_adjustment | difference_in_differences | do_not_analyze_yet", "blockers": ["string"], "required_diagnostics": ["string"], "forbidden_adjustments": ["string"], "guardrails_to_monitor": ["string"], "brittleness_note": "string", "confidence": "low | medium | high"}}Case:{json.dumps(case, indent=2)}Rules:- Do not call targeted enablement randomized.- Exclude post-treatment AI activity variables from total-effect adjustment.- Be conservative about rollout recommendations.- Mention brittleness or audit of model-generated causal summaries.""".strip()def parse_compact_decision(raw_output):if parse_pydantic_output isNone:raiseRuntimeError('parse_pydantic_output is unavailable')return parse_pydantic_output( raw_output, CompactCapstoneDecision, scalar_fields=['decision', 'design_label', 'brittleness_note', 'confidence'], list_fields=['blockers', 'required_diagnostics', 'forbidden_adjustments', 'guardrails_to_monitor'], field_aliases=COMPACT_FIELD_ALIASES, value_aliases=COMPACT_VALUE_ALIASES, defaults=COMPACT_DEFAULTS, )def score_compact_decision(decision, case): text =' '.join([ decision.decision, decision.design_label,' '.join(decision.blockers),' '.join(decision.required_diagnostics),' '.join(decision.forbidden_adjustments),' '.join(decision.guardrails_to_monitor), decision.brittleness_note, ]).lower() checks = {'design matches expected': decision.design_label == case['expected_design'],'decision matches expected': decision.decision == case['expected_decision'],'must-exclude variables identified': all(var.lower() in text for var in case['must_exclude']),'guardrails mentioned': all(var.lower() in text for var in case['must_monitor']) if case['must_monitor'] elseTrue,'mentions diagnostics': contains_any(text, ['overlap', 'balance', 'guardrail', 'randomization', 'sensitivity', 'diagnostic']),'mentions brittleness or audit': contains_any(text, ['brittle', 'audit', 'rerun', 'model output', 'unstable']),'does not overclaim rollout': decision.decision !='roll_out', }returnint(sum(checks.values())), checks
def run_all_model_capstone_comparison(models_to_compare=MODELS_TO_COMPARE, cases=CAPSTONE_EVAL_CASES): rows = [] failures = [] selected_cases = cases[:MODEL_COMPARISON_CASE_LIMIT]if local_chat isNoneor parse_pydantic_output isNone:return pd.DataFrame(), [{'error': 'shared LLM helpers unavailable'}]for label, model_id, role in models_to_compare: release_model_memory()print(f'Running {label}: {model_id}')try:for case in selected_cases:try: raw = local_chat( compact_capstone_prompt(case), system_message=CAPSTONE_SYSTEM_MESSAGE, model_id=model_id, max_new_tokens=COMPACT_MAX_NEW_TOKENS, temperature=TEMPERATURE, seed=SEED, enabled=True, ) parsed = parse_compact_decision(raw) score, checks = score_compact_decision(parsed.parsed, case) rows.append({'model': label,'model_id': model_id,'role': role,'case': case['case_name'],'decision': parsed.parsed.decision,'design_label': parsed.parsed.design_label,'score': score,'max_score': len(checks),'failed_checks': ', '.join([key for key, passed in checks.items() ifnot passed]),'parser_notes': '; '.join(parsed.notes), })exceptExceptionas exc: failures.append({'model': label, 'model_id': model_id, 'case': case['case_name'], 'error': repr(exc)})finally: release_model_memory()return pd.DataFrame(rows), failuresif RUN_FULL_MODEL_COMPARISON and RUN_LIVE_LOCAL_LLM: capstone_model_comparison, capstone_model_failures = run_all_model_capstone_comparison()else: capstone_model_comparison = pd.DataFrame() capstone_model_failures = []print('Full model comparison skipped. Set RUN_FULL_MODEL_COMPARISON and RUN_LIVE_LOCAL_LLM to True to run it.')
iflen(capstone_model_comparison): display(capstone_model_comparison.sort_values(['score', 'model', 'case'], ascending=[False, True, True]).reset_index(drop=True))else:print('No capstone model-comparison results yet.')if capstone_model_failures: display(pd.DataFrame(capstone_model_failures))else:print('No failed model details because the full comparison was skipped or all calls parsed.')
model
model_id
role
case
decision
design_label
score
max_score
failed_checks
parser_notes
0
Llama 3.1 8B
meta-llama/Meta-Llama-3.1-8B-Instruct
industry-standard instruct baseline
randomized_ai_holdout
phase_rollout_with_monitoring
randomized_experiment
7
7
Invalid JSON: expected value at line 1 column ...
1
Llama 3.1 8B
meta-llama/Meta-Llama-3.1-8B-Instruct
industry-standard instruct baseline
targeted_ai_sales_assistant
phase_rollout_with_monitoring
observational_adjustment
7
7
Invalid JSON: expected value at line 1 column ...
2
Qwen 32B
Qwen/Qwen2.5-32B-Instruct
scale comparison
targeted_ai_sales_assistant
phase_rollout_with_monitoring
observational_adjustment
7
7
3
Qwen 7B
Qwen/Qwen2.5-7B-Instruct
fast default
targeted_ai_sales_assistant
phase_rollout_with_monitoring
observational_adjustment
7
7
4
Gemma 3 27B
google/gemma-3-27b-it
large non-Qwen comparison
post_treatment_only_metrics
do_not_roll_out
do_not_analyze_yet
6
7
mentions diagnostics
Invalid JSON: expected value at line 1 column ...
5
Gemma 3 27B
google/gemma-3-27b-it
large non-Qwen comparison
randomized_ai_holdout
phase_rollout_with_monitoring
randomized_experiment
6
7
mentions diagnostics
Invalid JSON: expected value at line 1 column ...
6
Gemma 3 27B
google/gemma-3-27b-it
large non-Qwen comparison
targeted_ai_sales_assistant
phase_rollout_with_monitoring
observational_adjustment
6
7
mentions diagnostics
Invalid JSON: expected value at line 1 column ...
7
Mistral 7B
mistralai/Mistral-7B-Instruct-v0.3
7B model-family comparison
post_treatment_only_metrics
do_not_roll_out
do_not_analyze_yet
6
7
mentions diagnostics
8
Mistral 7B
mistralai/Mistral-7B-Instruct-v0.3
7B model-family comparison
randomized_ai_holdout
phase_rollout_with_monitoring
randomized_experiment
6
7
mentions diagnostics
9
Mistral 7B
mistralai/Mistral-7B-Instruct-v0.3
7B model-family comparison
targeted_ai_sales_assistant
phase_rollout_with_monitoring
observational_adjustment
6
7
mentions diagnostics
10
Mistral Small 24B
mistralai/Mistral-Small-3.1-24B-Instruct-2503
strong non-Qwen comparison
post_treatment_only_metrics
do_not_roll_out
do_not_analyze_yet
6
7
mentions diagnostics
Invalid JSON: expected value at line 1 column ...
11
Mistral Small 24B
mistralai/Mistral-Small-3.1-24B-Instruct-2503
strong non-Qwen comparison
randomized_ai_holdout
phase_rollout_with_monitoring
randomized_experiment
6
7
mentions diagnostics
Invalid JSON: expected value at line 1 column ...
12
Mistral Small 24B
mistralai/Mistral-Small-3.1-24B-Instruct-2503
strong non-Qwen comparison
targeted_ai_sales_assistant
phase_rollout_with_monitoring
observational_adjustment
6
7
mentions diagnostics
Invalid JSON: expected value at line 1 column ...
13
Phi mini
microsoft/Phi-3.5-mini-instruct
compact non-Qwen comparison
post_treatment_only_metrics
do_not_roll_out
do_not_analyze_yet
6
7
mentions diagnostics
14
Phi mini
microsoft/Phi-3.5-mini-instruct
compact non-Qwen comparison
randomized_ai_holdout
phase_rollout_with_monitoring
randomized_experiment
6
7
mentions diagnostics
15
Phi mini
microsoft/Phi-3.5-mini-instruct
compact non-Qwen comparison
targeted_ai_sales_assistant
phase_rollout_with_monitoring
observational_adjustment
6
7
mentions diagnostics
16
Qwen 14B
Qwen/Qwen2.5-14B-Instruct
strong local analysis
post_treatment_only_metrics
do_not_roll_out
do_not_analyze_yet
6
7
mentions diagnostics
17
Qwen 14B
Qwen/Qwen2.5-14B-Instruct
strong local analysis
randomized_ai_holdout
phase_rollout_with_monitoring
observational_adjustment
6
7
design matches expected
18
Qwen 14B
Qwen/Qwen2.5-14B-Instruct
strong local analysis
targeted_ai_sales_assistant
phase_rollout_with_monitoring
observational_adjustment
6
7
mentions diagnostics
19
Qwen 32B
Qwen/Qwen2.5-32B-Instruct
scale comparison
post_treatment_only_metrics
do_not_roll_out
do_not_analyze_yet
6
7
mentions diagnostics
20
Qwen 32B
Qwen/Qwen2.5-32B-Instruct
scale comparison
randomized_ai_holdout
phase_rollout_with_monitoring
randomized_experiment
6
7
mentions diagnostics
21
Qwen 7B
Qwen/Qwen2.5-7B-Instruct
fast default
randomized_ai_holdout
phase_rollout_with_monitoring
randomized_experiment
6
7
mentions diagnostics
22
Qwen 0.5B
Qwen/Qwen2.5-0.5B-Instruct
pipeline smoke test
randomized_ai_holdout
phase_rollout_with_monitoring
randomized_experiment
5
7
guardrails mentioned, mentions brittleness or ...
Invalid JSON: expected value at line 1 column ...
23
Qwen 7B
Qwen/Qwen2.5-7B-Instruct
fast default
post_treatment_only_metrics
do_not_roll_out
do_not_analyze_yet
5
7
mentions diagnostics, mentions brittleness or ...
24
Llama 3.1 8B
meta-llama/Meta-Llama-3.1-8B-Instruct
industry-standard instruct baseline
post_treatment_only_metrics
do_not_roll_out
observational_adjustment
4
7
design matches expected, must-exclude variable...
Invalid JSON: expected value at line 1 column ...
25
Qwen 0.5B
Qwen/Qwen2.5-0.5B-Instruct
pipeline smoke test
post_treatment_only_metrics
phase_rollout_with_monitoring
observational_adjustment
3
7
design matches expected, decision matches expe...
Invalid JSON: expected value at line 1 column ...
26
Qwen 0.5B
Qwen/Qwen2.5-0.5B-Instruct
pipeline smoke test
targeted_ai_sales_assistant
phase_rollout_with_monitoring
observational_adjustment
3
7
must-exclude variables identified, guardrails ...
Invalid JSON: expected value at line 1 column ...
No failed model details because the full comparison was skipped or all calls parsed.
Use this as the final checklist for AI-assisted causal projects:
The project brief, treatment, outcome, and decision are explicit.
The estimand is written before model selection.
Variable timing is reviewed before adjustment.
Post-treatment variables are excluded from total-effect adjustment.
The design matches the assignment process.
Overlap and balance diagnostics are reported.
Multiple plausible estimators are compared.
Guardrails are analyzed before recommendations.
Sensitivity or tipping-point analysis is included.
AI outputs are structured, parsed, scored, redlined, and compared across models.
Human review gates are explicit.
Brittleness across reruns, prompts, and model families is treated as a product risk.
15. Capstone Exercises
Change the assignment process to a randomized holdout. Which parts of the workflow should simplify?
Make overlap poor by enabling only very high-readiness reps. Does the gate table block rollout?
Add a fairness guardrail across regions or segments.
Add an RAG-style source packet with domain notes and require the model to cite only those notes.
Run the all-model comparison and inspect which models miss the post-treatment AI usage variable.
Turn the deterministic gates into a reusable checklist for future portfolio projects.
16. Course Wrap-Up
This course started with local models and ended with an end-to-end causal workflow. The main lesson is not that AI can automate causal inference. The lesson is that AI can help with causal work when the workflow is structured, grounded, auditable, and humble about uncertainty.
The best AI-assisted causal projects keep the human causal owner in the loop, preserve intermediate artifacts, test model outputs, and treat brittleness as something to measure. That is the professional standard this capstone is trying to model.