A causal analysis agent is not a magic analyst. It is a workflow controller that turns a project brief into structured intermediate artifacts: an estimand card, variable-role screen, design recommendation, diagnostic checks, estimates, and a report draft.
The goal of this notebook is to build a small but auditable causal analysis agent. The deterministic tools will do the statistical work. The LLM will propose and critique plans. Human review gates will decide whether the workflow should proceed.
Learning Goals
By the end of this notebook, you should be able to:
Define an agent state for causal analysis workflows.
Separate LLM planning from deterministic statistical tools.
Build tools for profiling data, screening variable roles, selecting an identification strategy, running diagnostics, and estimating effects.
Add human review gates that prevent the agent from silently using bad controls or weak designs.
Use structured LLM outputs for agent plans and critiques.
Score agent plans across model families for causal reasoning, brittleness, and unsafe automation.
Live Model Note
Agent notebooks are especially brittle because errors compound. A model can make a small mistake in the project brief, carry that mistake into the adjustment set, choose a bad control, run the wrong estimator, and then write a confident report. A multi-step agent can therefore look more impressive while being less safe.
This notebook treats brittleness as a design constraint. The agent must leave an audit trail, use deterministic tools for computations, clear model memory between model-family comparisons, and stop at human review gates when assumptions are not credible.
1. Setup
We will use a synthetic customer-retention project. The treatment is not randomized: high-risk customers are more likely to receive a concierge retention offer. That makes naive treated-versus-control comparisons misleading and gives the agent a realistic design problem.
import jsonimport reimport sysimport warningsfrom copy import deepcopyfrom pathlib import Pathfrom typing import Any, Literalimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport seaborn as snsimport statsmodels.formula.api as smffrom IPython.display import Markdown, displayfrom pydantic import BaseModel, Fieldwarnings.filterwarnings('ignore', category=FutureWarning)sns.set_theme(style='whitegrid', context='notebook')PROJECT_ROOT = Path.cwd()for candidate in [Path.cwd(), *Path.cwd().parents]:if (candidate /'notebooks'/'_shared'/'local_llm.py').exists(): PROJECT_ROOT = candidatebreakifstr(PROJECT_ROOT) notin sys.path: sys.path.insert(0, str(PROJECT_ROOT))print(f'Project root: {PROJECT_ROOT}')
Project root: /home/apex/Documents/portfolio
RUN_LIVE_LOCAL_LLM =TrueRUN_FULL_MODEL_COMPARISON =TrueRUN_SCHEMA_REPAIR_RETRY =TrueMODEL_ID ='Qwen/Qwen2.5-14B-Instruct'MAX_NEW_TOKENS =2200COMPACT_MAX_NEW_TOKENS =950TEMPERATURE =0.0SEED =220MODEL_COMPARISON_CASE_LIMIT =3try:import torchprint(f'CUDA available to this kernel: {torch.cuda.is_available()}')exceptExceptionas exc:print(f'Torch availability check failed: {exc}')
Read a project brief and extract the decision, treatment, outcome, unit, and candidate variables.
Create an estimand card.
Screen variable roles before modeling.
Recommend a design class and list assumptions.
Run deterministic diagnostics and estimators.
Produce a report draft that is grounded in computed artifacts.
A dangerous causal analysis agent will:
Treat every business question as an estimation problem.
Use post-treatment variables as controls.
Skip overlap checks.
Hallucinate variables or diagnostics.
Treat a fluent report as evidence that the design is credible.
Keep going after a human gate should have stopped it.
3. Running Example: Targeted Retention Concierge
A subscription company offered a concierge retention intervention to customers at risk of churn. The business question is whether the intervention increases 60-day renewal.
The assignment process is targeted, not randomized. High-risk customers are more likely to receive the offer. This creates confounding: treated customers are different before treatment.
The agent must not simply compare treated and untreated customers. It should identify the design as observational adjustment, screen controls, check overlap, estimate effects with adjustment/IPW/AIPW-style tools, and flag residual assumptions.
project_brief = {'project_id': 'retention_concierge_observational_v1','decision': 'Should the company expand a concierge retention offer to more at-risk subscription customers?','unit': 'customer_account','treatment': 'concierge_offer','outcome': 'renewed_60d','time_horizon': '60 days after offer eligibility','assignment_context': 'Customer-success managers prioritized accounts using churn-risk signals and available capacity.','candidate_variables': ['segment','tenure_months','monthly_spend','prior_usage_30d','support_tickets_prior_30d','risk_score_pre','concierge_offer','support_contacts_after_offer','renewed_60d', ],'business_risk': 'Expanding the program may consume expensive customer-success capacity.',}print(json.dumps(project_brief, indent=2))
{
"project_id": "retention_concierge_observational_v1",
"decision": "Should the company expand a concierge retention offer to more at-risk subscription customers?",
"unit": "customer_account",
"treatment": "concierge_offer",
"outcome": "renewed_60d",
"time_horizon": "60 days after offer eligibility",
"assignment_context": "Customer-success managers prioritized accounts using churn-risk signals and available capacity.",
"candidate_variables": [
"segment",
"tenure_months",
"monthly_spend",
"prior_usage_30d",
"support_tickets_prior_30d",
"risk_score_pre",
"concierge_offer",
"support_contacts_after_offer",
"renewed_60d"
],
"business_risk": "Expanding the program may consume expensive customer-success capacity."
}
4. Simulating the Retention Data
The simulation has a known data-generating process, but the agent will not be allowed to use that truth during the analysis. It sees only the project brief, the variable dictionary, and the observed data.
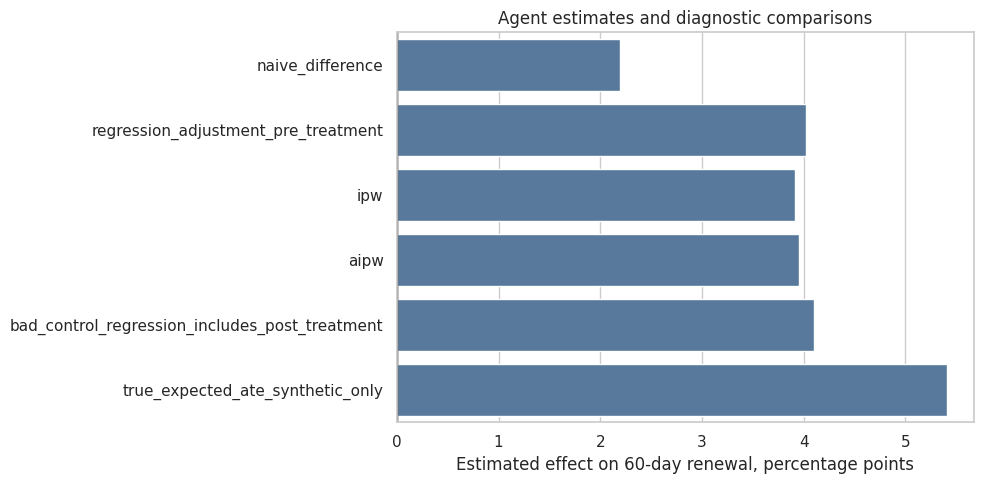
The true treatment effect is positive. However, because the intervention is targeted to high-risk customers, the naive treated-versus-control difference can be too pessimistic.
true_ate = df['true_expected_effect'].mean()naive_difference = ( df.loc[df['concierge_offer'] ==1, 'renewed_60d'].mean()- df.loc[df['concierge_offer'] ==0, 'renewed_60d'].mean())pd.DataFrame([ {'quantity': 'naive treated-control difference', 'value': naive_difference}, {'quantity': 'true expected ATE visible only in simulation', 'value': true_ate},])
quantity
value
0
naive treated-control difference
0.021940
1
true expected ATE visible only in simulation
0.054033
5. Variable Dictionary and Role Screen
The agent gets a variable dictionary. In a real project, this dictionary would come from data documentation, product owners, and analysts. The agent should not guess variable timing from column names alone.
The key trap here is support_contacts_after_offer. It is post-treatment. A naive agent may use it as a control because it predicts renewal, but controlling for it would block part of the treatment pathway and introduce post-treatment bias.
variable_dictionary = [ {'variable': 'segment', 'role': 'pre_treatment_confounder', 'timing': 'pre', 'description': 'Customer segment before treatment eligibility.'}, {'variable': 'tenure_months', 'role': 'pre_treatment_confounder', 'timing': 'pre', 'description': 'Months since subscription started.'}, {'variable': 'monthly_spend', 'role': 'pre_treatment_confounder', 'timing': 'pre', 'description': 'Monthly spend before the offer decision.'}, {'variable': 'prior_usage_30d', 'role': 'pre_treatment_confounder', 'timing': 'pre', 'description': 'Usage in the 30 days before offer eligibility.'}, {'variable': 'support_tickets_prior_30d', 'role': 'pre_treatment_confounder', 'timing': 'pre', 'description': 'Support tickets before offer eligibility.'}, {'variable': 'risk_score_pre', 'role': 'pre_treatment_confounder', 'timing': 'pre', 'description': 'Pre-treatment churn-risk score used in prioritization.'}, {'variable': 'concierge_offer', 'role': 'treatment', 'timing': 'treatment', 'description': 'Whether the account received the concierge offer.'}, {'variable': 'support_contacts_after_offer', 'role': 'post_treatment_variable', 'timing': 'post', 'description': 'Support contacts after the offer decision.'}, {'variable': 'renewed_60d', 'role': 'outcome', 'timing': 'post', 'description': 'Whether the account renewed within 60 days.'},]role_table = pd.DataFrame(variable_dictionary)role_table
variable
role
timing
description
0
segment
pre_treatment_confounder
pre
Customer segment before treatment eligibility.
1
tenure_months
pre_treatment_confounder
pre
Months since subscription started.
2
monthly_spend
pre_treatment_confounder
pre
Monthly spend before the offer decision.
3
prior_usage_30d
pre_treatment_confounder
pre
Usage in the 30 days before offer eligibility.
4
support_tickets_prior_30d
pre_treatment_confounder
pre
Support tickets before offer eligibility.
5
risk_score_pre
pre_treatment_confounder
pre
Pre-treatment churn-risk score used in priorit...
6
concierge_offer
treatment
treatment
Whether the account received the concierge offer.
7
support_contacts_after_offer
post_treatment_variable
post
Support contacts after the offer decision.
8
renewed_60d
outcome
post
Whether the account renewed within 60 days.
def screen_variable_roles(variable_dictionary, data_columns): rows = []for item in variable_dictionary: variable = item['variable'] role = item['role'] timing = item['timing'] rows.append({'variable': variable,'role': role,'timing': timing,'exists_in_data': variable in data_columns,'allowed_in_adjustment': role =='pre_treatment_confounder'and timing =='pre','requires_human_review': role in {'post_treatment_variable', 'outcome', 'treatment'} or timing !='pre','description': item['description'], })return pd.DataFrame(rows)role_screen = screen_variable_roles(variable_dictionary, df.columns)adjustment_set = role_screen.loc[role_screen['allowed_in_adjustment'], 'variable'].tolist()bad_controls = role_screen.loc[role_screen['role'].eq('post_treatment_variable'), 'variable'].tolist()role_screen
variable
role
timing
exists_in_data
allowed_in_adjustment
requires_human_review
description
0
segment
pre_treatment_confounder
pre
True
True
False
Customer segment before treatment eligibility.
1
tenure_months
pre_treatment_confounder
pre
True
True
False
Months since subscription started.
2
monthly_spend
pre_treatment_confounder
pre
True
True
False
Monthly spend before the offer decision.
3
prior_usage_30d
pre_treatment_confounder
pre
True
True
False
Usage in the 30 days before offer eligibility.
4
support_tickets_prior_30d
pre_treatment_confounder
pre
True
True
False
Support tickets before offer eligibility.
5
risk_score_pre
pre_treatment_confounder
pre
True
True
False
Pre-treatment churn-risk score used in priorit...
6
concierge_offer
treatment
treatment
True
False
True
Whether the account received the concierge offer.
7
support_contacts_after_offer
post_treatment_variable
post
True
False
True
Support contacts after the offer decision.
8
renewed_60d
outcome
post
True
False
True
Whether the account renewed within 60 days.
6. Agent State
An agent should maintain a state object. The state is the audit trail: what the agent knew, what it decided, which tools it called, which gates passed, and which outputs it produced.
A good state object is boring. That is the point. If the agent makes a mistake, the state should make the mistake inspectable.
The estimand card turns a vague business question into a target quantity. This is an artifact the agent should create before modeling.
def build_estimand_card(brief):return {'unit': brief['unit'],'treatment': brief['treatment'],'outcome': brief['outcome'],'time_horizon': brief['time_horizon'],'estimand': 'Average treatment effect of receiving the concierge offer among eligible customer accounts','comparison': 'The same eligible accounts under no concierge offer','decision_use': brief['decision'],'primary_risk': 'Treatment was targeted using pre-treatment churn risk, so untreated customers may not be comparable without adjustment.', }estimand_card = build_estimand_card(project_brief)agent_state['artifacts']['estimand_card'] = estimand_cardrecord_step(agent_state, 'build_estimand_card', 'completed', {'estimand': estimand_card['estimand']})print(json.dumps(estimand_card, indent=2))
{
"unit": "customer_account",
"treatment": "concierge_offer",
"outcome": "renewed_60d",
"time_horizon": "60 days after offer eligibility",
"estimand": "Average treatment effect of receiving the concierge offer among eligible customer accounts",
"comparison": "The same eligible accounts under no concierge offer",
"decision_use": "Should the company expand a concierge retention offer to more at-risk subscription customers?",
"primary_risk": "Treatment was targeted using pre-treatment churn risk, so untreated customers may not be comparable without adjustment."
}
9. Tool 3: Design Selector
The design selector should be conservative. Given targeted treatment assignment and no randomized holdout, the initial design class is observational adjustment. The selector should also say what would make the analysis stronger.
def select_design(brief, role_screen): treatment = brief['treatment'] pre_confounders = role_screen.loc[role_screen['allowed_in_adjustment'], 'variable'].tolist() post_treatment = role_screen.loc[role_screen['role'].eq('post_treatment_variable'), 'variable'].tolist()return {'recommended_design': 'observational_adjustment','why': 'Assignment was targeted by churn-risk signals rather than randomized.','required_assumption': 'Conditional exchangeability after adjusting for observed pre-treatment confounders.','adjustment_set': pre_confounders,'excluded_variables': post_treatment + [treatment, brief['outcome']],'stronger_future_design': 'Randomized holdout or staggered rollout with a pre-specified comparison group.', }design_plan = select_design(project_brief, role_screen)agent_state['artifacts']['design_plan'] = design_planrecord_step(agent_state, 'select_design', 'completed', {'recommended_design': design_plan['recommended_design']})record_gate( agent_state,'no post-treatment controls in adjustment set','pass'ifnotset(design_plan['adjustment_set']).intersection(bad_controls) else'fail',f"bad controls excluded: {bad_controls}",)print(json.dumps(design_plan, indent=2))
{
"recommended_design": "observational_adjustment",
"why": "Assignment was targeted by churn-risk signals rather than randomized.",
"required_assumption": "Conditional exchangeability after adjusting for observed pre-treatment confounders.",
"adjustment_set": [
"segment",
"tenure_months",
"monthly_spend",
"prior_usage_30d",
"support_tickets_prior_30d",
"risk_score_pre"
],
"excluded_variables": [
"support_contacts_after_offer",
"concierge_offer",
"renewed_60d"
],
"stronger_future_design": "Randomized holdout or staggered rollout with a pre-specified comparison group."
}
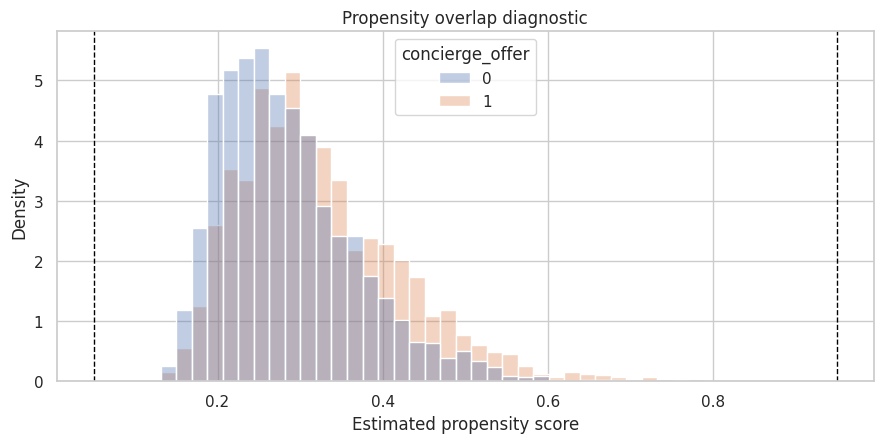
10. Tool 4: Overlap and Balance Diagnostics
For observational adjustment, the agent must check whether treated and comparison customers overlap on observed pre-treatment covariates. A model should not proceed just because an estimator can be fit.
The deterministic agent can now create a compact run summary. This is the object an LLM should summarize, not replace.
def json_clean(value):ifisinstance(value, (np.floating, float)) and np.isnan(value):returnNoneifisinstance(value, (np.integer,)):returnint(value)ifisinstance(value, (np.floating,)):returnfloat(value)return valuedef clean_record(record): cleaned = {key: json_clean(value) for key, value in record.items()}return {key: value for key, value in cleaned.items() if value isnotNone}def build_agent_run_summary(state): estimates = pd.DataFrame(state['artifacts']['estimate_table']) preferred = clean_record(estimates.loc[estimates['method'] =='aipw'].iloc[0].to_dict()) gate_table = pd.DataFrame(state['gates']) status ='ready_for_human_review'ifnot gate_table['status'].eq('fail').any() else'halted' state['final_status'] = statusreturn {'project_id': state['brief']['project_id'],'final_status': status,'recommended_design': state['artifacts']['design_plan']['recommended_design'],'estimand': state['artifacts']['estimand_card']['estimand'],'preferred_estimate': preferred,'diagnostics': {'overlap': state['artifacts']['overlap_diagnostics'],'estimate_stability': state['artifacts']['estimate_stability'],'gates': state['gates'], },'do_not_do': ['Do not use support_contacts_after_offer as an adjustment variable.','Do not call this randomized evidence.','Do not expand without human review of unobserved-confounding risk.', ],'brittleness_note': 'Agent outputs are brittle because planning, variable-role decisions, diagnostics, and report language can each fail and compound.', }agent_run_summary = build_agent_run_summary(agent_state)print(json.dumps(agent_run_summary, indent=2)[:4500])
{
"project_id": "retention_concierge_observational_v1",
"final_status": "ready_for_human_review",
"recommended_design": "observational_adjustment",
"estimand": "Average treatment effect of receiving the concierge offer among eligible customer accounts",
"preferred_estimate": {
"method": "aipw",
"estimate": 0.03953175950386774
},
"diagnostics": {
"overlap": {
"min_propensity": 0.13148356328220018,
"max_propensity": 0.7886534937694106,
"share_between_05_95": 1.0,
"effective_sample_size_ipw": 4381.418754943585,
"status": "pass"
},
"estimate_stability": {
"plausible_methods": [
{
"method": "regression_adjustment_pre_treatment",
"estimate": 0.040211131308402474
},
{
"method": "ipw",
"estimate": 0.039099118209487665
},
{
"method": "aipw",
"estimate": 0.03953175950386774
}
],
"signs_consistent": true,
"spread_pp": 0.11120130989148089,
"status": "pass"
},
"gates": [
{
"gate": "all brief columns exist",
"status": "pass",
"reason": "[]"
},
{
"gate": "no post-treatment controls in adjustment set",
"status": "pass",
"reason": "bad controls excluded: ['support_contacts_after_offer']"
},
{
"gate": "overlap is adequate",
"status": "pass",
"reason": "share in [0.05, 0.95] = 1.000"
},
{
"gate": "plausible estimators directionally agree",
"status": "pass",
"reason": "spread = 0.11 pp"
}
]
},
"do_not_do": [
"Do not use support_contacts_after_offer as an adjustment variable.",
"Do not call this randomized evidence.",
"Do not expand without human review of unobserved-confounding risk."
],
"brittleness_note": "Agent outputs are brittle because planning, variable-role decisions, diagnostics, and report language can each fail and compound."
}
14. Deterministic Report From the Agent
The report is cautious because the design is observational. It should recommend human review, not autonomous rollout.
def build_agent_report(summary): estimate = summary['preferred_estimate']['estimate'] gates = pd.DataFrame(summary['diagnostics']['gates']) gate_lines ='\n'.join(f"- {row.gate}: {row.status} ({row.reason})"for row in gates.itertuples())returnf"""### Causal Agent Run Report**Project.** {summary['project_id']}**Design selected.** {summary['recommended_design']}. The design relies on conditional exchangeability after observed pre-treatment adjustment.**Estimand.** {summary['estimand']}**Preferred estimate.** The AIPW estimate suggests a {100* estimate:.1f} percentage point effect on 60-day renewal. Because this is observational evidence, this should be treated as decision support rather than definitive proof.**Gates.**{gate_lines}**Key caution.** The post-treatment variable `support_contacts_after_offer` was excluded from the preferred adjustment set. Including it would create bad-control bias.**Brittleness note.** A causal analysis agent can fail through compounding errors across planning, tool calls, diagnostics, and report generation. This run should be reviewed before any rollout decision.""".strip()agent_report = build_agent_report(agent_run_summary)display(Markdown(agent_report))
Causal Agent Run Report
Project. retention_concierge_observational_v1
Design selected. observational_adjustment. The design relies on conditional exchangeability after observed pre-treatment adjustment.
Estimand. Average treatment effect of receiving the concierge offer among eligible customer accounts
Preferred estimate. The AIPW estimate suggests a 4.0 percentage point effect on 60-day renewal. Because this is observational evidence, this should be treated as decision support rather than definitive proof.
Gates. - all brief columns exist: pass ([]) - no post-treatment controls in adjustment set: pass (bad controls excluded: [‘support_contacts_after_offer’]) - overlap is adequate: pass (share in [0.05, 0.95] = 1.000) - plausible estimators directionally agree: pass (spread = 0.11 pp)
Key caution. The post-treatment variable support_contacts_after_offer was excluded from the preferred adjustment set. Including it would create bad-control bias.
Brittleness note. A causal analysis agent can fail through compounding errors across planning, tool calls, diagnostics, and report generation. This run should be reviewed before any rollout decision.
15. Optional LLM Agent Planner
Now we ask a local model to produce an agent plan from the project brief and data profile. The model does not get to run the analysis. It only proposes a plan that we can score.
{
"project_summary": "Analyze the impact of a concierge retention offer on customer renewal rates within 60 days, considering potential confounders and ensuring robust causal inference.",
"estimand": "The average treatment effect (ATE) of the concierge offer on customer renewals within 60 days.",
"recommended_design": "observational_adjustment",
"adjustment_set": ["segment", "tenure_months", "monthly_spend", "prior_usage_30d", "support_tickets_prior_30d", "risk_score_pre"],
"excluded_variables": ["support_contacts_after_offer", "renewed_60d"],
"tool_sequence": ["overlap_check", "balance_check", "bad_control_identification", "estimator_stability_check", "report_audit"],
"human_review_gates": ["initial_balance_review", "final_estimator_stability_review"],
"risks_and_failure_modes": ["Selection bias due to non-random assignment", "Unmeasured confounding", "Model misspecification"],
"stop_conditions": ["Significant imbalance detected", "Estimator instability observed", "Substantial overlap issues identified"],
"final_output_artifacts": ["Causal effect estimate", "Balance table", "Overlap plot", "Estimator stability report"],
"confidence": "medium"
}
if parsed_agent_plan isnotNone: display(Markdown(f"### LLM Agent Plan: `{parsed_agent_plan.recommended_design}`")) display(Markdown(parsed_agent_plan.project_summary)) display(Markdown('**Adjustment set**\n'+'\n'.join(f'- `{item}`'for item in parsed_agent_plan.adjustment_set))) display(Markdown('**Human review gates**\n'+'\n'.join(f'- {item}'for item in parsed_agent_plan.human_review_gates)))else:print('No parsed LLM agent plan is available yet.')
LLM Agent Plan: observational_adjustment
Analyze the impact of a concierge retention offer on customer renewal rates within 60 days, considering potential confounders and ensuring robust causal inference.
Human review gates - initial_balance_review - final_estimator_stability_review
16. Auditing the LLM Agent Plan
The audit checks whether the plan preserves core causal safeguards. The score is not a measure of intelligence. It is a checklist for whether the generated plan is safe enough to discuss.
def contains_any(text, patterns): text_lower = text.lower()returnany(pattern.lower() in text_lower for pattern in patterns)def score_agent_plan(plan, known_columns):if plan isNone:return pd.DataFrame([{'criterion': 'parsed plan exists', 'passed': False, 'score': 0}]) text =' '.join([ plan.project_summary, plan.estimand, plan.recommended_design,' '.join(plan.adjustment_set),' '.join(plan.excluded_variables),' '.join(plan.tool_sequence),' '.join(plan.human_review_gates),' '.join(plan.risks_and_failure_modes),' '.join(plan.stop_conditions),' '.join(plan.final_output_artifacts), ]).lower() hallucinated_adjusters =sorted(set(plan.adjustment_set) -set(known_columns)) checks = {'chooses observational adjustment': plan.recommended_design =='observational_adjustment','includes pre-treatment risk/usage confounders': {'risk_score_pre', 'prior_usage_30d'}.issubset(set(plan.adjustment_set)),'excludes post-treatment support contacts': 'support_contacts_after_offer'inset(plan.excluded_variables) and'support_contacts_after_offer'notinset(plan.adjustment_set),'mentions overlap or propensity diagnostics': contains_any(text, ['overlap', 'propensity', 'common support']),'mentions bad controls': contains_any(text, ['bad control', 'post-treatment', 'post treatment']),'mentions human review gates': len(plan.human_review_gates) >=2,'mentions unobserved confounding risk': contains_any(text, ['unobserved', 'exchangeability', 'hidden confounding']),'mentions brittleness or compounding errors': contains_any(text, ['brittle', 'rerun', 'compound', 'audit', 'model output']),'does not hallucinate adjustment columns': len(hallucinated_adjusters) ==0,'does not claim randomized evidence': not contains_any(text, ['randomized evidence', 'random assignment']) or contains_any(text, ['not randomized', 'not random']), } out = pd.DataFrame([ {'criterion': key, 'passed': bool(value), 'score': int(bool(value))}for key, value in checks.items() ])if hallucinated_adjusters:print('Hallucinated adjustment columns:', hallucinated_adjusters)return outagent_plan_score = score_agent_plan(parsed_agent_plan, df.columns)agent_plan_score
criterion
passed
score
0
chooses observational adjustment
True
1
1
includes pre-treatment risk/usage confounders
True
1
2
excludes post-treatment support contacts
True
1
3
mentions overlap or propensity diagnostics
True
1
4
mentions bad controls
False
0
5
mentions human review gates
True
1
6
mentions unobserved confounding risk
False
0
7
mentions brittleness or compounding errors
True
1
8
does not hallucinate adjustment columns
True
1
9
does not claim randomized evidence
False
0
17. Optional All-Model Agent-Planning Comparison
We now compare model families on compact agent-planning cases. This comparison is intentionally strict: a model gets credit for choosing a conservative design, naming required tools, adding human gates, and mentioning agent brittleness.
AGENT_EVAL_CASES = [ {'case_name': 'randomized_email_holdout','brief': 'A marketing team randomly held out 10% of eligible users from an email campaign. Outcome is purchase within 14 days.','columns': ['randomized_email', 'purchase_14d', 'segment', 'prior_spend', 'send_week'],'expected_design': 'randomized_experiment','expected_risk': 'check randomization balance and guardrails', }, {'case_name': 'targeted_retention_offer','brief': 'High-risk subscribers were targeted for a concierge retention offer. Outcome is renewal within 60 days. There is a post-offer support-contact variable.','columns': ['concierge_offer', 'renewed_60d', 'risk_score_pre', 'prior_usage_30d', 'support_contacts_after_offer', 'segment'],'expected_design': 'observational_adjustment','expected_risk': 'exclude post-treatment support contacts and check overlap', }, {'case_name': 'staggered_policy_rollout','brief': 'A pricing policy rolled out to regions in different months. Outcome is monthly gross margin. Regions have multiple pre-rollout months.','columns': ['region', 'month', 'policy_active', 'gross_margin', 'pre_policy_trend', 'region_size'],'expected_design': 'difference_in_differences','expected_risk': 'check pre-trends, timing, and spillovers', },]AGENT_EVAL_CASES
[{'case_name': 'randomized_email_holdout',
'brief': 'A marketing team randomly held out 10% of eligible users from an email campaign. Outcome is purchase within 14 days.',
'columns': ['randomized_email',
'purchase_14d',
'segment',
'prior_spend',
'send_week'],
'expected_design': 'randomized_experiment',
'expected_risk': 'check randomization balance and guardrails'},
{'case_name': 'targeted_retention_offer',
'brief': 'High-risk subscribers were targeted for a concierge retention offer. Outcome is renewal within 60 days. There is a post-offer support-contact variable.',
'columns': ['concierge_offer',
'renewed_60d',
'risk_score_pre',
'prior_usage_30d',
'support_contacts_after_offer',
'segment'],
'expected_design': 'observational_adjustment',
'expected_risk': 'exclude post-treatment support contacts and check overlap'},
{'case_name': 'staggered_policy_rollout',
'brief': 'A pricing policy rolled out to regions in different months. Outcome is monthly gross margin. Regions have multiple pre-rollout months.',
'columns': ['region',
'month',
'policy_active',
'gross_margin',
'pre_policy_trend',
'region_size'],
'expected_design': 'difference_in_differences',
'expected_risk': 'check pre-trends, timing, and spillovers'}]
def compact_agent_prompt(case):returnf"""Return one CompactAgentDecision JSON object only.Schema:{{ "design": "randomized_experiment | observational_adjustment | difference_in_differences | regression_discontinuity | do_not_analyze_yet", "should_proceed": "yes_with_human_review | needs_more_information | no", "required_tools": ["string"], "human_gates": ["string"], "excluded_variables": ["string"], "risk_flags": ["string"], "confidence": "low | medium | high"}}Case:{json.dumps(case, indent=2)}Rules:- Do not invent columns.- Name tools and human gates.- Mention brittleness or compounding agent errors.- Be conservative when design assumptions are not credible.""".strip()def parse_compact_agent_decision(raw_output):if parse_pydantic_output isNone:raiseRuntimeError('parse_pydantic_output is unavailable')return parse_pydantic_output( raw_output, CompactAgentDecision, scalar_fields=['design', 'should_proceed', 'confidence'], list_fields=['required_tools', 'human_gates', 'excluded_variables', 'risk_flags'], field_aliases=COMPACT_FIELD_ALIASES, value_aliases=COMPACT_VALUE_ALIASES, defaults=COMPACT_DEFAULTS, )def score_compact_agent_decision(decision, case): text =' '.join([ decision.design, decision.should_proceed,' '.join(decision.required_tools),' '.join(decision.human_gates),' '.join(decision.excluded_variables),' '.join(decision.risk_flags), ]).lower() checks = {'design matches expected': decision.design == case['expected_design'],'requires human gate': len(decision.human_gates) >=1or decision.should_proceed !='yes_with_human_review','mentions relevant diagnostic risk': contains_any(text, case['expected_risk'].split()),'mentions brittleness or compounding errors': contains_any(text, ['brittle', 'compound', 'audit', 'model output', 'rerun']),'does not proceed without review': decision.should_proceed !='yes'and decision.should_proceed in {'yes_with_human_review', 'needs_more_information', 'no'}, }if case['case_name'] =='targeted_retention_offer': checks['excludes post-treatment variable'] ='support_contacts_after_offer'inset(decision.excluded_variables)returnint(sum(checks.values())), checks
def run_all_model_agent_comparison(models_to_compare=MODELS_TO_COMPARE, cases=AGENT_EVAL_CASES): rows = [] failures = [] selected_cases = cases[:MODEL_COMPARISON_CASE_LIMIT]if local_chat isNoneor parse_pydantic_output isNone:return pd.DataFrame(), [{'error': 'shared LLM helpers unavailable'}]for label, model_id, role in models_to_compare: release_model_memory()print(f'Running {label}: {model_id}')try:for case in selected_cases:try: raw = local_chat( compact_agent_prompt(case), system_message=AGENT_SYSTEM_MESSAGE, model_id=model_id, max_new_tokens=COMPACT_MAX_NEW_TOKENS, temperature=TEMPERATURE, seed=SEED, enabled=True, ) parsed = parse_compact_agent_decision(raw) score, checks = score_compact_agent_decision(parsed.parsed, case) rows.append({'model': label,'model_id': model_id,'role': role,'case': case['case_name'],'design': parsed.parsed.design,'should_proceed': parsed.parsed.should_proceed,'score': score,'max_score': len(checks),'failed_checks': ', '.join([key for key, passed in checks.items() ifnot passed]),'parser_notes': '; '.join(parsed.notes), })exceptExceptionas exc: failures.append({'model': label, 'model_id': model_id, 'case': case['case_name'], 'error': repr(exc)})finally: release_model_memory()return pd.DataFrame(rows), failuresif RUN_FULL_MODEL_COMPARISON and RUN_LIVE_LOCAL_LLM: agent_model_comparison, agent_model_failures = run_all_model_agent_comparison()else: agent_model_comparison = pd.DataFrame() agent_model_failures = []print('Full model comparison skipped. Set RUN_FULL_MODEL_COMPARISON and RUN_LIVE_LOCAL_LLM to True to run it.')
iflen(agent_model_comparison): summary = ( agent_model_comparison .groupby(['model', 'model_id', 'role'], as_index=False) .agg(mean_score=('score', 'mean'), min_score=('score', 'min'), cases=('case', 'nunique')) .sort_values(['mean_score', 'min_score'], ascending=False) ) display(summary)else:print('No model-comparison summary yet.')if agent_model_failures: display(pd.DataFrame(agent_model_failures))else:print('No failed model details because the full comparison was skipped or all calls parsed.')
model
model_id
role
mean_score
min_score
cases
1
Llama 3.1 8B
meta-llama/Meta-Llama-3.1-8B-Instruct
industry-standard instruct baseline
5.333333
5
3
3
Mistral Small 24B
mistralai/Mistral-Small-3.1-24B-Instruct-2503
strong non-Qwen comparison
5.333333
5
3
2
Mistral 7B
mistralai/Mistral-7B-Instruct-v0.3
7B model-family comparison
5.000000
5
3
0
Gemma 3 27B
google/gemma-3-27b-it
large non-Qwen comparison
5.000000
4
3
4
Phi mini
microsoft/Phi-3.5-mini-instruct
compact non-Qwen comparison
5.000000
4
3
8
Qwen 7B
Qwen/Qwen2.5-7B-Instruct
fast default
5.000000
4
3
7
Qwen 32B
Qwen/Qwen2.5-32B-Instruct
scale comparison
4.666667
4
3
6
Qwen 14B
Qwen/Qwen2.5-14B-Instruct
strong local analysis
4.333333
3
3
5
Qwen 0.5B
Qwen/Qwen2.5-0.5B-Instruct
pipeline smoke test
3.333333
3
3
No failed model details because the full comparison was skipped or all calls parsed.
18. Agent Design Checklist
Before trusting a causal analysis agent, check that it has:
A structured state object.
An estimand card before modeling.
A variable-role screen before adjustment.
Explicit exclusion of post-treatment variables.
Design selection with assumptions.
Overlap, balance, and estimator-stability diagnostics.
Human review gates and stop conditions.
A report grounded in computed artifacts.
A model-output audit for hallucinated columns and overconfident language.
Memory cleanup between large local model calls.
19. Exercises
Add a synthetic unobserved confounder to the data-generating process. How should the agent report the residual risk?
Make overlap worse by targeting only the highest-risk customers. Does the overlap gate stop the workflow?
Add a randomized-holdout flag to the brief and modify the design selector to choose an experiment.
Add an agent tool that writes a minimal analysis plan for a stakeholder before any estimation code is run.
Run the all-model comparison and inspect which models fail to exclude support_contacts_after_offer.
Extend the agent state so each artifact records the tool version, timestamp, and reviewer approval.
20. Key Takeaways
A causal analysis agent should orchestrate tools, not replace identification thinking.
Deterministic tools should own profiling, diagnostics, and estimation.
The LLM should be constrained to planning, critique, translation, and report drafting.
Human review gates are not decoration. They are part of the causal design.
Agentic workflows are brittle because errors compound across steps. The remedy is structure, memory cleanup, explicit stop conditions, and auditability.